使用 FFmpeg 将 webm 格式转成 mp4
记录一下使用 [[FFmpeg]] 将 YouTube 下载的 WebM 格式视频转码成 Adobe Premiere 可以处理的 MP4 格式。
基础知识
WebM 格式
[[WebM]] 是 Google 开源的一个,免版权费用视频文件格式。该格式可以提供高质量的视频压缩以在 HTML5 页面上使用。BSD 许可开源。1
WebM 采用 On2 Technologies 公司开发的 [[VP8]] 和后续的 [[VP9]] 作为视频解码器,使用 Xiph.Org 基金会开发的 Vorbis,[[Opus]] 作为音频编码器,以 [[Matroska]] 格式作为封装格式。
FFmpeg
FFmpeg 是一系列有关多媒体,包括音频、视频,字幕等等相关元数据处理的编程库和处理工具。可以非常方便地用来对视频内容编解码,转码等等操作。FFmpeg 是一个开放源代码的项目,是一个命令行工具,如果你想要一个 GUI,可以尝试一下 [[HandBrake]]。
FFmpeg 支持非常多的编码格式,包括 VP8,VP9,H.264,Opus,Vorbis,AAC 等等。
处理
查看一下下载的视频:
ffmpeg -i \[놀면\ 뭐하니\ 후공개\]\ WSG\ 워너비\ 블라인드\ 오디션\ 풀영상\ \[엠마스톤\ -\ 그런\ 일은\]\ \(Hangout\ with\ Yoo\ -\ WSG\ Wannabe\ YooPalBong\)\ \[n2eVz5IIu-Y\].webm
ffmpeg version 5.0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with Apple clang version 13.1.6 (clang-1316.0.21.2)
configuration: --prefix=/usr/local/Cellar/ffmpeg/5.0.1 --enable-shared --enable-pthreads --enable-version3 --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libbluray --enable-libdav1d --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librist --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libspeex --enable-libsoxr --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack --enable-videotoolbox
libavutil 57. 17.100 / 57. 17.100
libavcodec 59. 18.100 / 59. 18.100
libavformat 59. 16.100 / 59. 16.100
libavdevice 59. 4.100 / 59. 4.100
libavfilter 8. 24.100 / 8. 24.100
libswscale 6. 4.100 / 6. 4.100
libswresample 4. 3.100 / 4. 3.100
libpostproc 56. 3.100 / 56. 3.100
Input #0, matroska,webm, from '[놀면 뭐하니 후공개] WSG 워너비 블라인드 오디션 풀영상 [엠마스톤 - 그런 일은] (Hangout with Yoo - WSG Wannabe YooPalBong) [n2eVz5IIu-Y].webm':
Metadata:
ENCODER : Lavf58.29.100
Duration: 00:04:22.52, start: -0.007000, bitrate: 547 kb/s
Stream #0:0(eng): Video: vp9 (Profile 0), yuv420p(tv, bt709), 1920x1080, SAR 1:1 DAR 16:9, 29.97 fps, 29.97 tbr, 1k tbn (default)
Metadata:
DURATION : 00:04:22.495000000
Stream #0:1(eng): Audio: opus, 48000 Hz, stereo, fltp (default)
Metadata:
DURATION : 00:04:22.521000000
可以清楚的看到其中有两条数据,Video 使用 vp9 编码,而音频则是 opus 编码的。
使用命令转码:
ffmpeg -i origin.webm newfile.mp4
更多 ffmpeg 的选项可以参考之前的 FFmpeg 入门 。
转码过后:
❯ ffmpeg -i \[놀면\ 뭐하니\ 후공개\]\ WSG\ 워너비\ 블라인드\ 오디션\ 풀영상\ \[엠마스톤\ -\ 그런\ 일은\]\ \(Hangout\ with\ Yoo\ -\ WSG\ Wannabe\ YooPalBong\)\ \[n2eVz5IIu-Y\].mp4
ffmpeg version 5.0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with Apple clang version 13.1.6 (clang-1316.0.21.2)
configuration: --prefix=/usr/local/Cellar/ffmpeg/5.0.1 --enable-shared --enable-pthreads --enable-version3 --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libbluray --enable-libdav1d --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librist --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libspeex --enable-libsoxr --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack --enable-videotoolbox
libavutil 57. 17.100 / 57. 17.100
libavcodec 59. 18.100 / 59. 18.100
libavformat 59. 16.100 / 59. 16.100
libavdevice 59. 4.100 / 59. 4.100
libavfilter 8. 24.100 / 8. 24.100
libswscale 6. 4.100 / 6. 4.100
libswresample 4. 3.100 / 4. 3.100
libpostproc 56. 3.100 / 56. 3.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from '[놀면 뭐하니 후공개] WSG 워너비 블라인드 오디션 풀영상 [엠마스톤 - 그런 일은] (Hangout with Yoo - WSG Wannabe YooPalBong) [n2eVz5IIu-Y].mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
encoder : Lavf59.16.100
Duration: 00:04:22.58, start: 0.000000, bitrate: 599 kb/s
Stream #0:0[0x1](eng): Video: h264 (High) (avc1 / 0x31637661), yuv420p(tv, bt709, progressive), 1920x1080 [SAR 1:1 DAR 16:9], 465 kb/s, 24 fps, 24 tbr, 12288 tbn (default)
Metadata:
handler_name : VideoHandler
vendor_id : [0][0][0][0]
Stream #0:1[0x2](eng): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 129 kb/s (default)
Metadata:
handler_name : SoundHandler
vendor_id : [0][0][0][0]
可以看到视频流已经变成 h264 编码,而音频也变成了 aac。
邻家的百万富翁 读后感
《邻家的百万富翁》是 [[20220515-21-天计划]] 中的第二本书,这本书在我的书单中已经存在很久了,好像是当时听某个播客中推荐的,就加到了书单,正好在这次计划中看完。这是一本讲述以统计数据,调查问卷的方式整理出来的对美国平民百万富翁的一份调查报告。最近几年因为 [[Naval Ravikant]],[[芒格]],[[孟岩]],等等人的影响已经对投资,金钱的观点所有改变,就像作者所说「有钱不是为了成为富人,而是为了拥有选择的权利。」
邻家的百万富翁作为一本畅销书确实非常易读,通过目录就能大致知道作者想要在这一章节中讲述的内容:
- 第二章收入和财富的关系,人们常常把收入和财富混为一谈,然而并不是收入越高,财富就越多
- 第三章「想要积累财富,首先要学会尊重金钱」,让我们树立正确的金钱观,警惕消费陷阱,任何时候都要学会节俭
- 第四章「消费自由就是想买什么就买什么?」显然作者的反问句就已经给出了答案,作者在这一章中以翔实的数据和例子让我知道了大部分的富人不会买超过自身年收入 3~4 倍的房子,大多数的富人也不开豪车,通常一辆耐用的家用车一开就是几十年
- 第五章「如何才能守住财富」,通过智力、教育、自制力、韧性、节俭
- 第六章「富豪的工作很“平庸”」,这一章讲述富豪的职业,工作内容,早期职业经历的重要性,销售的重要性,并且大家都认可努力工作才是正道,如果你想知道富人们是如何选择工作的不妨来读读这一章,一份热爱的职业不仅能带来收入,还能为你提供各种资源
- 第七章「学会投资,别打鸡蛋放在一个篮子里」,重点不言而喻,富人是如何投资的,说的道理不仅通俗,而且是被巴菲特,芒格等等反复说过的,分散,指数,通过不断地自我学习。
总结书的内容
- 作者通过将美国富人作为研究对象,通过观察,调查总结出富人之所以成为富人的原因,其中不乏人尽皆知的道理,也不乏在职业、消费和投资领域的独到见解。
启发或想法
- 将收入转换成财富,
- 合理分配自己的时间、精力,时间对所有人都是公平的,并且时间是不可逆的,用在了 A 上就必然不能用在 B 上。
- 向那些取得了财富的人学习,而不是像装富的人学习
- 定期储蓄、节制消费、学习投资
- 长远来看储蓄对一个人的财富积累能力影响最大
- 尽早形成关于工作和职业的人生态度
- 认清自己的优劣势,忧患意识
财富的积累固然不容易,但不是不可能。我们都想变得富有,但是变得富有的目的不应该是为了过高消费的生活。
谁应该看这本书
任何想要了解财富是什么人。
三个 Quotes
你能通过创造一些有价值的东西(如产品或服务)来获得收入吗?并且你能继续持有并靠继续投资,使得这些收入不断增值吗?
投资自己的事业是那些经济成功人士的标志之一。但前提是他们要具备毅力、韧性和自制力等个性特征,能成功度过那些不可避免的低谷期。
创造力、自制力和某些社交技能(包括领导能力)比成绩和能力更重要。
书摘见:Clip
自由软件 自由社会 读书笔记
《自由软件 自由社会》是 [[20220515-21-天计划]] 阅读的第一本书,虽然早就听说过 [[Richard Stallman]],也听过其提倡的[[自由软件]],但是从来没有系统地了解过 Stallman 的思想,以及自由软件具体指代什么,而软件开发又和社会有着什么样的连接。我带着这样的疑问看完了这一本 Stallman 的著作集。
关于[[自由]],在哲学领域,政治领域,以及有无数的哲人给出了无数不同的解读,卢梭在社会契约论中说,只有服从了社会为自己所设之规定才叫做自由,康德说「自由不是想干什么就干什么,而是不想干什么就不干什么」,[[赛亚 伯林]]进而提出了[[积极自由]]和[[消极自由]],相较于政治哲学而言,软件行业发展才不过短短几十年,下面就来总结一下 Stallman 关于自由在软件领域的思考。
自由软件的定义是什么?
自由软件,free software, 这里的 free 不是免费,而是和 free speech 中的 free 同一个含义。
阅读的时候,让我最惊讶的是 Stallman 将自由软件和法律做了类比。 一个「自由的社会」是由法律来规范的,任何自由社会的法律对这些都有限制,即没有自由社会允许秘密法律。没有政府可以对其治理的对象隐藏规范,法律能够起效,只有在公平正义的情况下才可以。只有当法律条款可以被监管,或者管理的管理者(立法机构、律师)知悉和控制时,法律才是有效的。
在美国的司法实践中,我们可以看到当事人雇佣律师来提高收益,而诉讼过程中,律师撰写诉状,进而影响法官的判决意见。这过程中所有的材料都是符合 Stallman 所说的「自由」,诉讼简报是公开的,论据是透明的,论证过程也公开的,法官意见可以在之后的任何诉讼中被引用,可以被复制,可以被融合到其他案例中。整个美国的司法系统就是建立在「源代码」的设计和原则之上的。它对任何想使用它的人都是开放和自由的。
这一段类比论证突然让我醒悟过来过去几年里面为什么我一直着迷美国司法案件,正因为是公开的,所有的讨论就可以基于前人公开的「经验」,「知识」,在经过几十年,几百年的实践之后,就会有不断被修正,不断被重新认识,不断完善的司法系统。
这不仅是人类知识得以进步的原因,我想也是近[[200年来科技发展迅速的原因]],知识的交换带来了指数级的增长。
而这不也正是软件行业在短短几十年间就迅速改变了当代生活的原因吗?当代社会当然存在 Stallman 说的专有软件,但我们自己思考,服务器早已经被 GNU/Linux 占领,而手机操作系统领域,也早已被 Android 这样一个开源系统所占领。
回过来我们再来看看 Stallman 关于[[自由软件]]的具体定义,自由软件赋予了用户运行、复制、分发、学习、修改并改进的自由。进而归纳出四项基本自由:
- 基于任何目的、按自己的意愿运行软件的自由
- 学习软件如何工作的自由,按意愿修改软件符合自己要求的自由
- 分发软件副本的自由
- 将修改过的软件版本再分发给其他人的自由,这样整个社区就有机会共享你对软件的修改
自由软件和开源的区别?
从自由软件的四项自由,我们可以发现第二条,则是以获取源码为前提的,如果没有源代码,则后三条自由无从谈起。
相较于自由软件,可以看出来开源仅仅只能保证源码可得,相较于自由软件的约束要宽泛很多。
Stallman 也举了一些例子来举证,很多开源软件实际上并不符合自由软件:
- Open Watcom 许可证不允许修改的版本用于私人使用
- 另外也有一些专有系统通过检查签名的方式可以阻止一些程序的运行,即使源码是可得的,也无法保证是自由的
关于专利、版权和商标
在书中另外一个让我没有想到的是 Stallman 对于「专利」,「版权」,「商标」的思考。我们总以知识产权来统称这些概念,但实际我们能看到一些差别。
- 版权法是设计为了保护作者的身份和艺术
- 专利法的本意是促进发表有用的想法,代价是赋予想法的发表者暂时的垄断权
- 而商标法则是保护品牌。
在阅读 Stallman 关于版权的讨论的时候,我时不时得想起当前正在如火如荼发生的 Web3 革命。我们要把被大公司夺取的自由抢回来。
想象一下,我们说的音乐版权真正的保护了音乐创作者了吗?是不是利益的大头都被音乐平台抽去了。在 Kindle 上发布作品的作家,是不是也受到了 Kindle 的限制。
在这些专有设备上运行的程序夺走了用户对其计算的控制权,想想一下 Amazon 可以在任何时候删掉用户设备上的《1984》,想想一下 Apple Music 可以因为某人不喜欢而下架整张专辑。数字技术可以赋予用户自由,同样也以一种温水煮青蛙的方式来剥夺了用户的自由。使用自由软件是掌握我们自己数字生活的第一步。
关于监控
我的另一个疑惑便是自由软件何以和自由社会联系在一起,Stallman 用了整整一章来给我们普及大规模监控的危害。
而现实中的事实也告诉我们一旦当某人或某机构可以获取足够多的信息,就会对人们的思考方式产生深远的影响。
自由的定义
最后 Stallman 给出了关于「自由和权力」的区别,自由是指能够做出主要是影响自己的决定;而权力是指能够做出影响他人甚于自己的决定。
甚至引用了 William Hazlitt 的话,「对自由的爱是对他人的爱,对权力的爱是对自己的爱。」我们不要放弃我们对软件的控制权力。
总结
因为整本书是 Stallman 历年的演讲、论文集,所以不可避免的产生了很多重复内容,在不同的文章中总是会看到一些重复的思考。但总体上我能从这本书中知道 Stallman 所主张的观点,暂不管不管这样的思想是否是对的,但过去几十年的经验告诉我,如果没有 Stallman,没有 [[Linus Torvalds]],我们的社会可能会没有当前这样的发展。
自由意味着你控制着自己的生活。如果你使用程序来打理你的生活,你的自由就取决于你如何控制着这些程序。
去中心化的协同文档 Skiff 初体验
昨天有朋友分享给我一篇文章,关于红杉领投两轮的 Skiff,简单的看了一下,文章介绍的 Skiff 是一款基于 Web3 的在线协同文档应用。具有与 Google Docs 类似的文档编写和共享功能。
Skiff 将 E2EE (端到端加密技术)作为在线工作的核心设计原则,被用于消息传递、写作、协作和通信。Skiff 服务器只会存储加密版本的数据,而无法破译它。
2024 年 2 月更新
Skiff 已经被 [[Notion]] 收购,将在 6 个月内关闭原来的服务。
文档内容可以在设置中选择存放在 Skiff 的中心服务器上,或者 [[IPFS]] 中。
- 端到端加密
- 隐私优先
- 支持 [[MetaMask]] 加密钱包登录
- 数据可选择存储于 IPFS
- 支持发送和接收来自 ENS 地址的邮件
- 邮箱容量默认是 10G,可以通过升级扩容至 100G
- 支持三个邮箱别名
- 客户端有 Android, iOS, macOS 版本
今年 3 月 31 日,Skiff 完成了 1050 万美元 A 轮融资,由红杉资本领投。在去年 5 月红杉资本就参与领投了 Skiff 420 万美元种子轮,投资方还包括一群在隐私和去中心化领域拥有深厚专业知识的天使投资人:Mozilla 前首席执行官 John Lilly、[[Coinbase]] 前首席技术官 Balaji Srinivasan、TCG 加密投资者 Gaby Goldberg 和来自 Dropbox 和以太坊基金会的 Albert Ni。
端到端加密
用户每次登录 Skiff 时,浏览器都会生成一个密钥,该密钥用于在成功登录后解密由 Skiff 的服务器发送到您设备的帐户数据,并且都是在本地发生的。从中派生的密钥永远不会通过任何网络发送和存储在 Skiff 的服务器中。
当 A 编辑了一份文档后,会使用仅在他和 B 之间共享的对称加密密钥对其进行加密(该密钥不会与 Skiff 共享),B 接收到 A 的加密编辑后,执行验证和解密,然后将其合并到文档中。整个过程,数据不会泄露给任何中央服务器。这样便于验证和保护个人和敏感信息。
当文档出现敏感内容时,也可以通过设置密码进行保护。
存储
在数据存储方面,Skiff 与 IPFS 集成。在 IPFS 上,数据被复制并分布在参与计算机的网络中,这些计算机协同工作以确保存储在网络上的所有数据的完整性和持久性。所以使用 IPFS 就可以永久访问用户数据,并无需依赖中央服务器。
目前为止 Skiff 可以在设置中选择将内容保存到 IPFS 还是 Skiff 自身的服务器。
Web 3 登录方式
2021 年 12 月上,Skiff 也开始支持 MetaMask 钱包登录,让用户使用现有的密钥对(以太坊地址)访问 Skiff 上端到端加密文档和数据。
在今年 1 月,Skiff 又可以使用以太坊域名服务(ENS)名称来简化 Skiff 上的用户名。
Skiff Mail
在体验文档编辑的时候,发现 Skiff 还退出了端到端加密的邮箱服务。
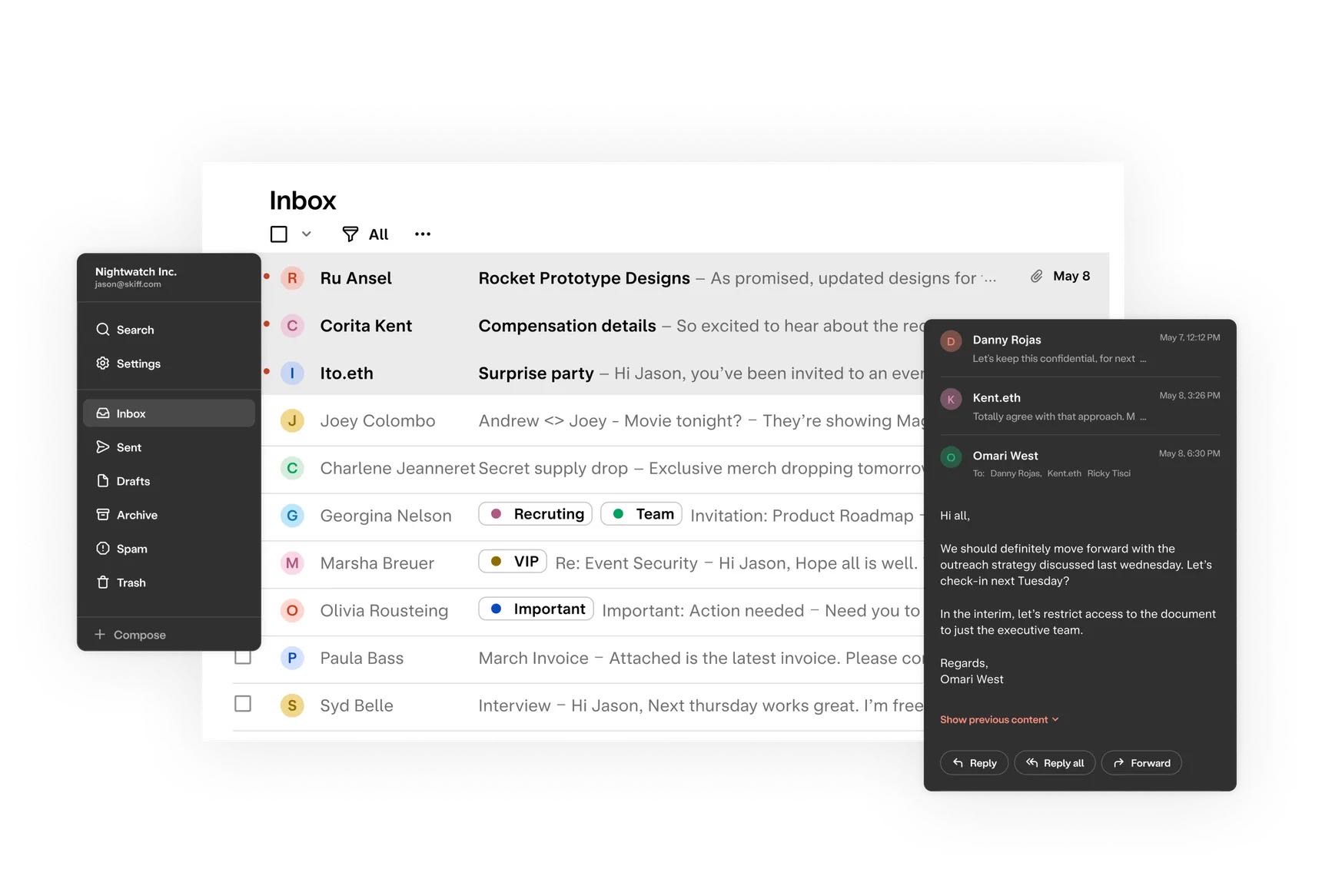
还能支持三个 @skiff.com 的别名,并且轻量使用起来问题不大,支持标签等等,就是目前搜索功能相较于成熟的 Gmail 还有一定距离。
注册
- 点击邮箱注册链接 https://gtk.pw/skiff(含个人推荐链接),如果使用 MetaMask 可以使用其登录,或者输入自己的邮箱地址然后点击下方按钮”Continue”,等待接收确认邮件;
- 收到邮件后,点击邮件内的”Confirm email”按钮(如果没有收到邮件查看一下垃圾箱),在打开的页面中输入密码并确认;
- 保存”recovery key”,直接点击”Save key as PDF”按钮即可;
- 根据需要选”Team”或”Personal”,为了简化注册过程建议选”Personal”;
- 注册 Workspace 成功后,在页面顶端”You’re invited to Skiff Mail’s Alpha release. Switch to your inbox to send end-to-end encrypted, private emails.”通知后点击”Claim account”激活邮箱地址;
- 邮箱 ID 需 6 位数以上,可以包括字母、数字和英文句号,每个邮箱账户最多可以设置 3 个邮箱 ID。(和 Gmail 一样,”someone”和”some.one”是一样的,在邮件收发时会自动忽略英文句号)
推荐三个代码统计工具 tokei, cloc 和 scc
有些时候在开源项目的时候可能需要对整个项目有一个全局的了解,比如想要了解这个项目中具体有多少行代码,那么这个时候,下面三个命令就派上用场了。
之前在 Twitter 上看到有人分享说 SQLite 的注释非常详细,甚至比代码都多,那么用下面这些工具一眼就能看到。
Tokei
Tokei 是一个使用 Rust 编写的用来显示代码信息的命令行工具,Tokei 可以以编程语言为分类显示文件数,代码行数,注释行数,空行数。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Language Files Lines Code Comments Blanks
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
BASH 4 49 30 10 9
JSON 1 1332 1332 0 0
Shell 1 49 38 1 10
TOML 2 77 64 4 9
───────────────────────────────────────────────────────────────────────────────
Markdown 5 1355 0 1074 281
|- JSON 1 41 41 0 0
|- Rust 2 53 42 6 5
|- Shell 1 22 18 0 4
(Total) 1471 101 1080 290
───────────────────────────────────────────────────────────────────────────────
Rust 19 3416 2840 116 460
|- Markdown 12 351 5 295 51
(Total) 3767 2845 411 511
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Total 32 6745 4410 1506 829
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
在 macOS 下安装:
brew install tokei
cloc
cloc 同样是一个用来计算代码行数的命令行工具,和 Tokei 一样,可以统计代码行数,注释行数,空行。 cloc 使用 Perl 编写。
Debian/Ubuntu:
sudo apt install cloc
或者以 Docker 运行:
docker run --rm -v $PWD:/tmp aldanial/cloc
scc
scc 是一个使用 Go 语言编写的统计代码行数的工具。
brew install scc
使用 uPic 快捷上传图片到图床
uPic 是一个 macOS 上的图片上传工具,使用 Swift 编写。支持对接非常多的对象存储,以及可以自定义使用 [[Chevereto]],或者 Lsky Pro 作为图床。
安装
可以直接从 App Store 安装,或者:
brew install bigwig-club/brew/upic --cask
自定义配置
配置 Lsky Pro
Lsky Pro 兰空图床是一个 PHP 编写的图床程序。Lsky Pro 升级了 2.0 版本,API 接口也进行了重写。
首先使用用户名,密码获取 Token:
curl -X POST -F "email=email@address" -F "password=your_passwd" https://your.domain/api/v1/tokens
复制返回值中的 token 字段。
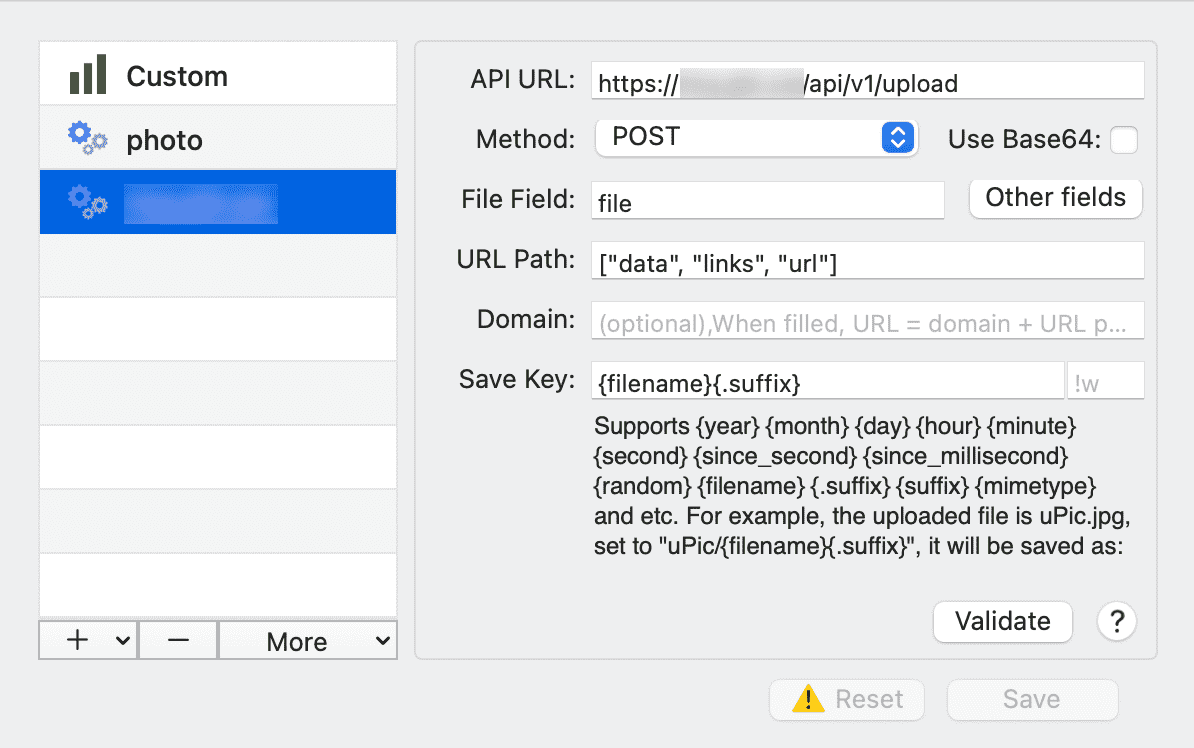
然后配置 uPic,创建一个自定义 Host:
POST /api/v1/upload- 文件字段填写
file - URL
["data", "links", "url"]
示意图:
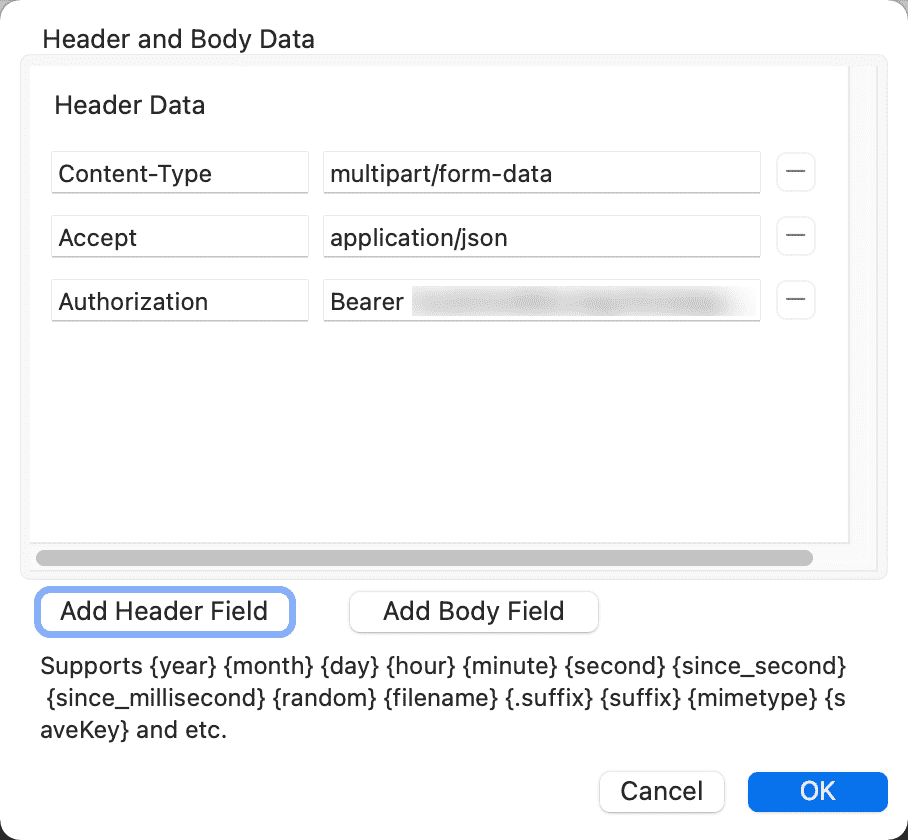
然后配置 Other fields,添加 Header,记得 Bearer 后面添加上面获取的 Token。
设置 Chevereto
根据 Chevereto 的官方文档,可以配置:
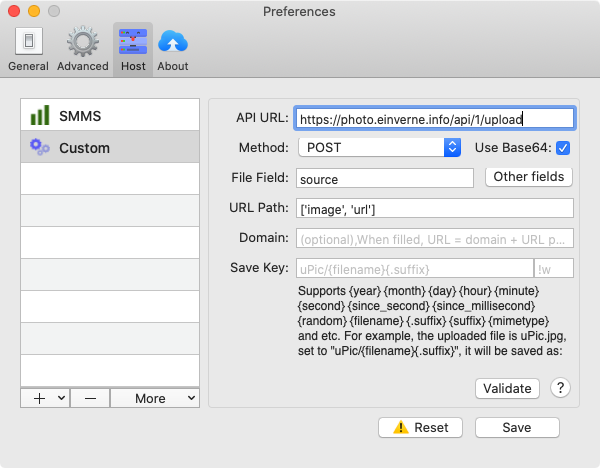
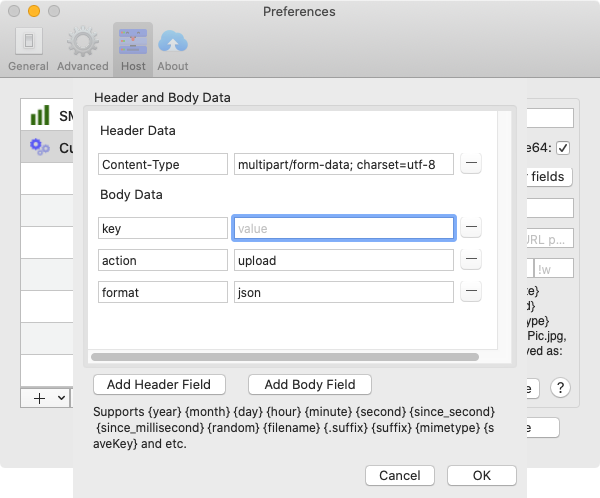
API:
POST http://mysite.com/api/1/upload/?key=12345&source=http://somewebsite/someimage.jpg&format=json
参数:
key, The API v1 key, can be found in admin dashboard.action, 值是uploadsource, URL 或者是图片的 Base64format, 返回类型,可以是json,redirect,txt
返回结果
{
"status_code": 200,
"success": {
"message": "image uploaded",
"code": 200
},
"image": {
"name": "example",
"extension": "png",
"size": 53237,
"width": 1151,
"height": 898,
"date": "2014-06-04 15:32:33",
"date_gmt": "2014-06-04 19:32:33",
"storage_id": null,
"description": null,
"nsfw": "0",
"md5": "c684350d722c956c362ab70299735830",
"storage": "datefolder",
"original_filename": "example.png",
"original_exifdata": null,
"views": "0",
"id_encoded": "L",
"filename": "example.png",
"ratio": 1.2817371937639,
"size_formatted": "52 KB",
"mime": "image/png",
"bits": 8,
"channels": null,
"url": "http://127.0.0.1/images/2014/06/04/example.png",
"url_viewer": "http://127.0.0.1/image/L",
"thumb": {
"filename": "example.th.png",
"name": "example.th",
"width": 160,
"height": 160,
"ratio": 1,
"size": 17848,
"size_formatted": "17.4 KB",
"mime": "image/png",
"extension": "png",
"bits": 8,
"channels": null,
"url": "http://127.0.0.1/images/2014/06/04/example.th.png"
},
"medium": {
"filename": "example.md.png",
"name": "example.md",
"width": 500,
"height": 390,
"ratio": 1.2820512820513,
"size": 104448,
"size_formatted": "102 KB",
"mime": "image/png",
"extension": "png",
"bits": 8,
"channels": null,
"url": "http://127.0.0.1/images/2014/06/04/example.md.png"
},
"views_label": "views",
"display_url": "http://127.0.0.1/images/2014/06/04/example.md.png",
"how_long_ago": "moments ago"
},
"status_txt": "OK"
}
配置 Backblaze B2
[[Backblaze B2 Cloud Storage]]
同类产品
同类的图片上传工具还有:
- PicGo 使用 Electron-vue 实现。
- PicX
- PicUploader
reference
使用 beets 命令行工具整理音乐库
之前在了解到 [[MusicBrainz]] 以及在整理我的音乐库的时候 就获知了 beets 这样一款命令行工具,通过文件名来在 MusicBrainz, Discogs, 和 Beatport 中获取音乐的 metadata.
beets 是一款音乐文件整理的命令行工具。
beets 的特性:
- 获取 metadata,包括封面、歌词、风格
- 转码
- 检查音乐库中重复的文件或专辑
- 通过浏览器来访问浏览音乐库,并支持直接在浏览器中播放
Installation
安装:
pip install beets
首先输入如下命令查看配置文件的位置:
beet config -p
使用默认的编辑器编辑配置文件:
beet config -e
导入音乐库之前注意备份,Beets 可能会修改或移动文件。
放入配置:
directory: ~/Music
library: ~/Music/musiclibrary.db
import:
copy: no
move: no
link: no
hardlink: no
delete: no
write: no
beet import -A不进行 autotagbeet import -W当进行 autotag 时,不将 tags 写入文件,仅保留在 beets 数据库beet import -C不将文件拷贝到音乐目录,保留在原始位置beet import -m移动文件到音乐库
更多配置:
library: library.db
directory: ~/Music
import:
write: yes
copy: yes
move: no
link: no
hardlink: no
delete: no
resume: ask
incremental: no
incremental_skip_later: no
from_scratch: no
quiet_fallback: skip
none_rec_action: ask
timid: no
log:
autotag: yes
quiet: no
singletons: no
default_action: apply
languages: []
detail: no
flat: no
group_albums: no
pretend: no
search_ids: []
duplicate_action: ask
bell: no
set_fields: {}
clutter: [Thumbs.DB, .DS_Store]
ignore:
- .*
- '*~'
- System Volume Information
- lost+found
ignore_hidden: yes
replace:
'[\\/]': _
^\.: _
'[\x00-\x1f]': _
'[<>:"\?\*\|]': _
\.$: _
\s+$: ''
^\s+: ''
^-: _
path_sep_replace: _
asciify_paths: no
art_filename: cover
max_filename_length: 0
aunique:
keys: albumartist album
disambiguators: albumtype year label catalognum albumdisambig releasegroupdisambig
bracket: '[]'
overwrite_null:
album: []
track: []
plugins: []
pluginpath: []
threaded: yes
timeout: 5.0
per_disc_numbering: no
verbose: 0
terminal_encoding:
original_date: no
artist_credit: no
id3v23: no
va_name: Various Artists
ui:
terminal_width: 80
length_diff_thresh: 10.0
color: yes
colors:
text_success: green
text_warning: yellow
text_error: red
text_highlight: red
text_highlight_minor: lightgray
action_default: turquoise
action: blue
format_item: $artist - $album - $title
format_album: $albumartist - $album
time_format: '%Y-%m-%d %H:%M:%S'
format_raw_length: no
sort_album: albumartist+ album+
sort_item: artist+ album+ disc+ track+
sort_case_insensitive: yes
paths:
default: $albumartist/$album%aunique{}/$track $title
singleton: Non-Album/$artist/$title
comp: Compilations/$album%aunique{}/$track $title
statefile: state.pickle
musicbrainz:
host: musicbrainz.org
ratelimit: 1
ratelimit_interval: 1.0
searchlimit: 5
match:
strong_rec_thresh: 0.04
medium_rec_thresh: 0.25
rec_gap_thresh: 0.25
max_rec:
missing_tracks: medium
unmatched_tracks: medium
distance_weights:
source: 2.0
artist: 3.0
album: 3.0
media: 1.0
mediums: 1.0
year: 1.0
country: 0.5
label: 0.5
catalognum: 0.5
albumdisambig: 0.5
album_id: 5.0
tracks: 2.0
missing_tracks: 0.9
unmatched_tracks: 0.6
track_title: 3.0
track_artist: 2.0
track_index: 1.0
track_length: 2.0
track_id: 5.0
preferred:
countries: []
media: []
original_year: no
ignor: []
required: []
ignored_media: []
ignore_data_tracks: yes
ignore_video_tracks: yes
track_length_grace: 10
track_length_max: 30
具体参数: https://beets.readthedocs.io/en/stable/reference/config.html
转码
GitHub Codespaces 使用
很早以前就收到 GitHub 邮件说可以使用 Codespaces Beta 了。但当时没有怎么在意,最近在想要修改一些项目中个别配置的时候不想将整个项目都拉到本地然后再提交,就尝试了一下网页端的 Codespaces,没想到的是整个体验过程非常顺畅,并且自动同步了之前在 VSCode 上的所有配置。
点击下图中的 Create codespace 可以快速地创建。

默认会使用 4 核 8G 内存 32 GB 磁盘的 Codespaces。
GitHub Codespaces 已经正式发布了,免费的用户也可以拥有一个 2 核 15GB 空间,一个月 60 分钟的 Space 空间。如果选择 4 核的空间,相应的就只能免费使用 30 分钟;选择 8 核的空间就只能免费使用 15 分钟。
默认的 Codespaces 包括了常用的工具,包括 Python,Node.js,Docker 等等。1 如果要使用自定义的镜像,那么可以参考 这里
GitHub Codespaces 提供了一个在线的编程环境,GitHub 会创建一个在线的 Codespace,一个虚拟的容器。用户可以直接在浏览器中,或者通过本地的 Visual Studio Code 远程连接到该 Space,直接进行文件的修改。
用户所有创建的 Codespaces 都可以在这里 找到。
逃离豆瓣之豆瓣代替服务
这篇笔记新建的时间是 2020 年 12 月 29 号,想来从那个时间点开始我就一直想着怎么离开豆瓣了。过去一年时间里面陆陆续续也发现了不少不错的网站,甚至有一些比豆瓣都要好用。这里就再整理一下。
豆瓣让我不能忍受的便是对词条的删减,以及对用户笔记,影评,书评的肆意审查,基本导致了现在豆瓣陷入不可用的状态。
我也曾经说过,我离不开豆瓣的几个理由:
- 我过去几千条的标注
- 豆瓣关注的有趣的灵魂
- 还有无数的有价值的影评,书评
豆瓣电影 剧集
NeoDB
NeoDB 是一个建立在 federated network (联邦网络)中的用来标记书籍、电影、音乐和游戏的网站。
NeoDB 目前只能通过 [[Mastodon]] (或[[Pleroma]]/Friendica/PixelFed)实例的账号来登录。
我的页面:https://neodb.social/users/einverne@m.einverne.info/
themoviedb
themoviedb 简称为 TMDB ,是一个从 2008 年开始的电影,剧集数据库。拥有非常全的数据库。
TMDB 也开放了编辑入口,所有的注册用户都可以贡献,和当年的豆瓣非常相似,官方也有非常详细的 贡献指南 。
看网站的设计,词条的界面,数据也非常详细,设计也不错。
Trake.tv
[[trakt]] 是一个电视剧和电影媒体资源订阅追踪平台,电视界的 IMDB。可以认为是一个电视剧的数据库,有每个电视剧的元数据,至少包括剧名、首播时间、是否完结、长度、季、集、语言、国家、简介、类别、演员,链接到官网,IMDB,TMDB,TVDB,Wiki 等的链接等等。而且这些数据是公开的,有非常多 App 在使用他作为基础数据提供其他服务。
Trakt 相较于豆瓣更好的地方在于可以和第三方的应用交互,比如在 Plex 中看完一集之后可以自动同步到 trake。
Trakt 还支持 [[Kodi]], [[Plex]], [[Emby]], [[Netflix]], [[Infuse]], [[Jellyfin]], [[MediaPortal]], [[MrMC]], [[Stremio]], [[Serviio]], [[VLC]] 等等。
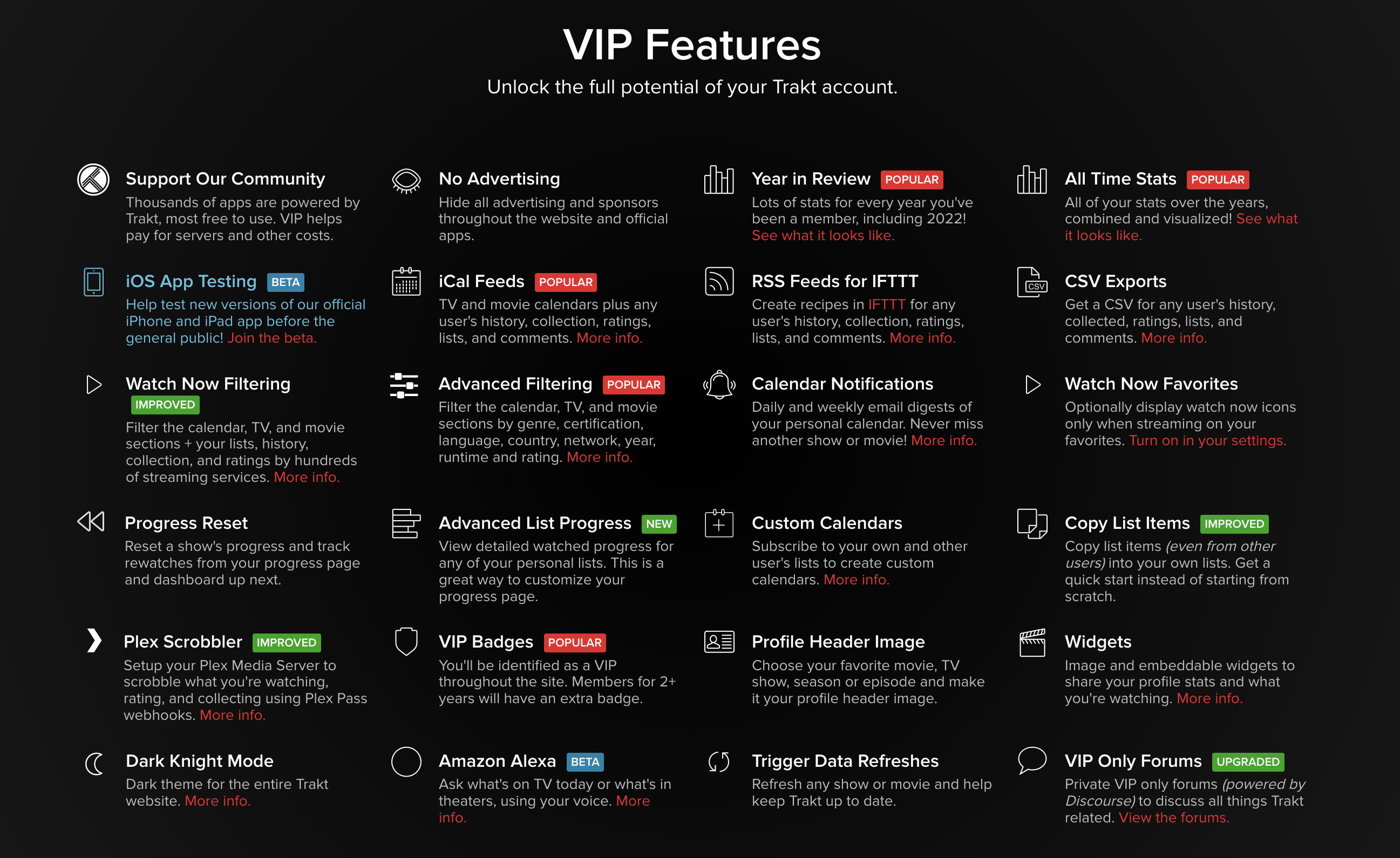
Trakt 还提供了 VIP 增值服务,包括了如上的功能。个人 30$ 一年起步,还有另外一个是 60$ 一年。
LetterBoxd
LitterBoxd 是另一个可以标记看过电影的网站。不过 LetterBoxd 只支持电影。
首页:
词条页面
TVDB
TBDB 是专注在剧集的网站。
IMDB
IMDB 就不用多说了,老牌的电影资料站。
豆瓣读书
Google Books
- 支持图书目录预览,支持标题,ISBN 搜索,支持浏览记录等等
- 支持标注想读(To read),在读(Reading now),读过(Have read),支持打分,甚至也是 1-5 分,支持填写 review
- 支持一键链接到网络商城购买,支持跳转到 Google Play 购买电子版
Google Book 的 API 文档:
Goodreads
Amazon 收购而来的网站,和 Kindle 搭配使用。
thestorygraph
可以用来追踪阅读进度,以及管理看过书籍。
豆瓣音乐
本人不怎么使用豆瓣音乐,所以没怎么整理,不过 Last.FM 已经存在很多年了。数据也比较全。
Proxmox 扩展 VM 虚拟机磁盘容量
之前在 Proxmox 上给 Ubuntu 划分了 64GB 的空间,运行一段时间之后磁盘空间剩余不多,就抽时间扩展一下。本文就记录一下给 Proxmox VE 的虚拟机扩展的过程。其实之前的文章里面也略微提到过一些,但是没有完整记录。
本来想着是这一篇文章把虚拟机的扩展和缩减空间一并整理了,但写着写着篇幅就比较大了,本文最后还是集中在扩容部分,缩减(shrink) 部分有机会再整理吧。
扩容之前
在扩容之前,为了防止发生错误,请先备份虚拟机,然后关闭虚拟机操作。
关于备份的操作可以参考: Proxmox VE 下备份和恢复虚拟机
虚拟机磁盘扩容
在 Proxmox VE 管理后台,点击虚拟机,在 Hardware 中选中 Hard Disk,然后在菜单栏中就能看到 Resize disk
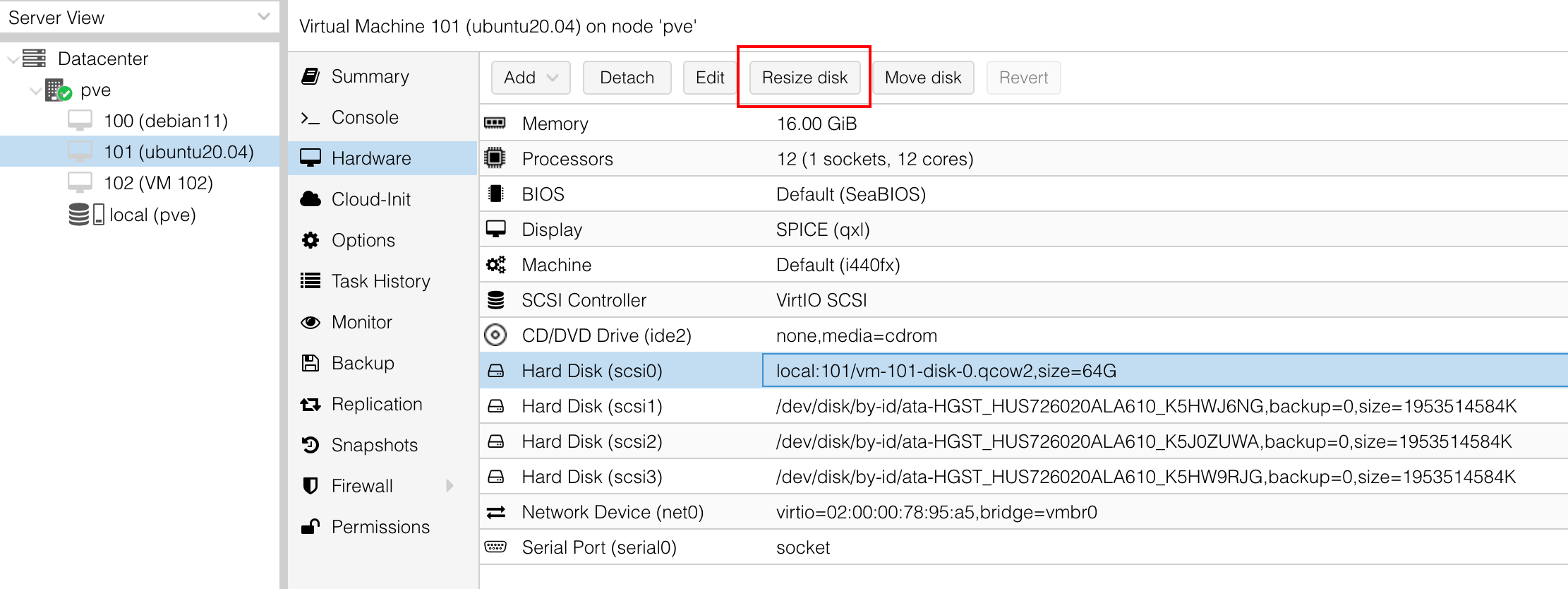
不过需要注意的是,这里的只能给虚拟机的磁盘增加容量,而不能缩小容量,关于缩小容量的操作以后有机会再写。
图中可以看到原始的虚拟机磁盘分配了 64GB,我又扩容了 64GB。
扩容之后启动虚拟机,SSH 登录,然后执行 df -h
Filesystem Size Used Avail Use% Mounted on
udev 7.8G 0 7.8G 0% /dev
tmpfs 1.6G 1.5M 1.6G 1% /run
/dev/sda2 63G 38G 23G 63% /
tmpfs 7.9G 4.0K 7.9G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup
/dev/loop0 56M 56M 0 100% /snap/core18/2344
/dev/loop2 62M 62M 0 100% /snap/core20/1434
/dev/loop1 56M 56M 0 100% /snap/core18/2409
mergerfs 5.4T 4.6T 510G 91% /mnt/storage
/dev/loop3 68M 68M 0 100% /snap/lxd/22753
/dev/loop6 44M 44M 0 100% /snap/snapd/15177
/dev/loop7 62M 62M 0 100% /snap/core20/1405
/dev/loop5 45M 45M 0 100% /snap/snapd/15534
/dev/loop4 68M 68M 0 100% /snap/lxd/22526
/dev/sdd1 1.8T 1.6T 196G 89% /mnt/sdb1
/dev/sdb1 1.8T 1.6T 117G 94% /mnt/sdd1
/dev/sdc1 1.8T 1.6T 198G 89% /mnt/sdc1
tmpfs 1.6G 0 1.6G 0% /run/user/1000
可以看到系统分区的容量 /dev/sda2 并没有扩展。
还可以用 sudo fdisk -l 来查看。
然后检查一下分区,执行 sudo lsblk
❯ sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 55.5M 1 loop /snap/core18/2344
loop1 7:1 0 55.5M 1 loop /snap/core18/2409
loop2 7:2 0 61.9M 1 loop /snap/core20/1434
loop3 7:3 0 67.8M 1 loop /snap/lxd/22753
loop4 7:4 0 67.9M 1 loop /snap/lxd/22526
loop5 7:5 0 44.7M 1 loop /snap/snapd/15534
loop6 7:6 0 43.6M 1 loop /snap/snapd/15177
loop7 7:7 0 61.9M 1 loop /snap/core20/1405
sda 8:0 0 128G 0 disk
├─sda1 8:1 0 1M 0 part
└─sda2 8:2 0 64G 0 part /
可以看到系统的分区 sda2 确实是没有完全占用全部的磁盘(sda)。这个时候我们只需要扩展一下系统分区即可。
我们可以使用很多种方式(parted, growpart, cfdisk)扩展分区,这里我们就使用 growpart 命令。
在 Debian 和 Ubuntu 下 growpart 命令在 cloud-guest-utils 包中。
注意这里的数字 2 要替换成自己的分区号。
sudo growpart /dev/sda 2
结果:
❯ sudo growpart /dev/sda 2
CHANGED: partition=2 start=4096 old: size=134211584 end=134215680 new: size=268431327 end=268435423
没有使用 [[LVM]],就使用 resize2fs,执行:
sudo resize2fs /dev/sda2
执行结果:
❯ sudo resize2fs /dev/sda2
resize2fs 1.45.5 (07-Jan-2020)
Filesystem at /dev/sda2 is mounted on /; on-line resizing required
old_desc_blocks = 8, new_desc_blocks = 16
The filesystem on /dev/sda2 is now 33553915 (4k) blocks long.
之后在查询 df -h 就看到空间完美的被使用了。
如果使用了 LVM,需要执行如下步骤:
sudo pvresize /dev/sda2
更新逻辑卷的大小:
sudo lvresize --extents +100%FREE --resizefs /dev/mapper/ubuntu--vg-ubuntu--lv
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。