配置 Rime 在 Vim 下退出编辑模式时自动切换成英文输入法
半年以前在 Obisidian 的文章下面有人曾经问过我一个问题,如何在 Vim 或者其他使用 Vim 模式的编辑器,比如 IntelliJ,或者 Obisidian 开启 Vim 模式后方便地切换中英文输入法,因为在编辑模式和普通模式下,需要经常切换输入法,使得体验变得非常槽糕。

这个问题一直萦绕再我脑海里,直到今天再整理关于 Rime 相关的笔记的时候发现 macOS 下的 squirrel 支持了一个 vim_mode 选项,这使得我们可以在配置中定义在哪些应用中,当我们按下 Esc 的时候将 Rime 自动切换成英文状态。1
配置
在 squirrel.custom.yaml 配置文件中可以配置 vim_mode 这样的语句。
org.vim.MacVim:
ascii_mode: true
no_inline: true
vim_mode: true
表示在 MacVim 应用中,当按下 Esc 的时候会自动将 Rime 切换成英文输入法。这样就可以节省 一次切换输入法的麻烦。
所以最后我的配置:
com.jetbrains.intellij:
ascii_mode: true
vim_mode: true
net.kovidgoyal.kitty:
ascii_mode: true
vim_mode: true
md.obsidian:
vim_mode: true
配置不同的应用自动切换英文
上面的 vim_mode 只会对 Esc 按键进行响应,那么如果要针对不同的应用进行中英文的自动切换呢?答案上面的配置中也已经有了,通过 ascii_mode 来配置,比如我在 Alfred 中及几乎不会使用到中文的,基本上就是模糊打出应用的名字,然后直接回车就启动应用了;再比如在终端或者 IDE 中使用中文的场景也特别少,所以可以直接配置上 ascii_mode 当切换到该应用时立即切换成 Rime 下的英文模式。
在不同的应用间切换不同的输入法
上面的操作已经可以满足大部分人的需求了,但如果你还想更进一步,比如当我使用 Kakao talk 的时候想要切换成韩语输入法,那么就需要接触 Hammerspoon 了,配置可见我的 dotfiles
使用 MusicBrainz 管理我的音乐库
自从 2014 年总结整理了当年所有流行的音乐网站 之后就一直使用网易云音乐到今天,然而这些年的发展过程中多多少少产生了一些变化,虾米没了,Google Play Music 也没有了。而如今网易云音乐也出现了各种各样的问题,虽然有些问题可以或多或少的被规避,但网易用起来就是没有那么舒服了。
我在原来的那篇文章中提到了互联网化,以及伴随着移动设备的发展,我个人偏好的几个产品特点:
- WEB 化
- 同步账号系统
- 跨平台
- UGC 用户贡献
这几点虽然现在网易云音乐依然做的非常不错,并且能推出 Linux 版本这件事情就是值得称赞的。而所有的音乐服务中,也只有网易能把「云村」这样的一个 UGC 社区运营得如此出彩。
但是在核心的音乐版权上却一而再的在退步,虽然偷偷摸摸地用音乐云盘的法律漏洞可以避免一些用户使用上的问题,但是我个人最无法忍受的事情,就是偷偷摸摸删除用户文件,这件事情让我再无法忍受。所以自从那件事情被暴露之后我就一直在思考有没有什么方案我可以迁移。相较于 Apple Music 或 Spotify 这样的音乐流媒体分发模式,我个人更偏向于购买或者能让我看到音乐文件的方式。所以我个人是不会去重度使用那些流媒体音乐服务的。
而由因为前段时间 Play Music 服务关闭,一下子下载了十几个 GB 的文件,造成了我对音乐文件的管理的困扰。所以一有时间我就会去想怎么离线管理起我的这些音乐文件。
我的音乐库管理方法
在寻找代替方案的过程中,我先整理了一下我的需求
- 一个整体的音乐库(良好的组织方式),能够让我对所有的歌曲文件一目了然
- 我个人偏向于按照音乐家,专辑,单曲这样的形式去管理
- 可以让我对音乐文件的 metadata 进行编辑
- 可以让我快速通过,名字,音乐家,或标签进行搜索
良好的文件组织形式
离线的音乐文件不像那些在线的音乐服务,可以直接将音乐加入到不同的列表进行管理,我个人更加倾向于在本地通过目录组织进行管理。
所以目前我在 Music 这样的目录中建立了一个顶层的文件夹用来管理所有的文件。
普通专辑
普通的专辑,我就以这样的层级进行管理:
Music > Artist > Album Name > Audio
Various Artist
对于合集,以这样的方式。
Music > Various Artists > Movies > Soundtracks
Music > Movies > Soundtracks > Hackers
找出重复文件
当需要管理成千上万个文件的时候,重复文件的查找就变得异常困难,幸好可以借助开源的命令行工具 jdupes 来快速找到重复文件并删除,节省了大量的空间。
管理音乐文件 metadata 和 ID3
一旦确定了音乐媒体库的文件结构,可以开始整理,但是整理的过程中,就会发现每个音乐文件都会带一个完整或不完整的 metadata 信息,这些信息会被一些音乐播放器获取在播放时用来显示封面或音乐家,专辑的信息。很多年前在使用 Play Music 的时候,为了让 Google 自动匹配上,使用 mp3tag 批量修改了一些文件,但是 mp3tag 只能在 Windows 上使用,所以又找到了一个叫做 MusicBrainz,这个软件是跨平台的,可以用来修改文件的 metadata。
ID3 是一个位于 mp3 文件开头或结尾若干字节的附加信息,包含了该 mp3 歌手,标题,专辑,年代,风格等等信息。
[[ID3 tags]] 通常会被播放器用来展示其基本信息,包括封面,歌手,专辑等等。
MusicBrainz Picard
MusicBrainz Picard 是一个 Python 编写的、开源的(GPL 2.0)、跨平台的音乐文件元数据管理工具。很早之前在 Windows 上用过 一款叫做 Mp3tag 的软件,MusicBrainz Picard 就是类似的工具。
关于该软件的使用就不再多说,可以直接参考图文教程
在使用之前可以做一些调整
利用 MusicBrainz 自动修改文件 metadata
使用 MusicBrainz 导入文件,然后点击菜单中的 Cluster,会自动根据专辑进行归类。
点击需要编辑的专辑,然后点击 Look Up,如果查找不到,可以点击 Scan,自动根据歌曲 metadata 匹配信息。匹配到的文件会自动到右边,在下方可以看到被编辑的内容,点击保存即可将内容保存到文件。
利用 MusicBrainz 自动修正目录
在菜单栏 Options 中默认只选中了 Save Tags,可以将 Move Files 勾选上,这样每一次保存的时候会自动修正目录。
reference
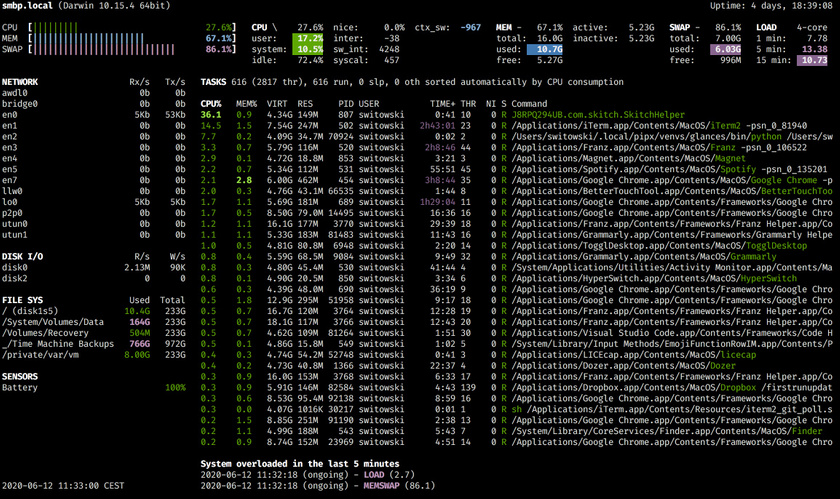
Asus RT-AC86U 初始设置
前些天给家里买手机正好凑单了一个 Asus RT-AC86U,正好可以代替出了两次故障的小米 3G。
提前工作
- 登录管理后台(http://router.asus.com/Main_Login.asp)启用 SSH (系统管理 - 系统设置 - 服务 - 启用 SSH)
- 开启 JFFS 分区,系统管理 - 系统设置 - Persistent JFFS2 partition - Enable JFFS custom scripts and configs
- U 盘格式成 ext4 插到路由器
- 一个已经刷成 Merlin 固件 的路由器
固件选择
- 官改固件 是在官方的固件上的增强,增加了软件中心
- 原版 Merlin 固件
- Merlin 改版 在原本梅林固件的基础上修改而来
刷机步骤
AC86U 的刷机步骤非常简单,通过网页「升级页面」,直接上传 .w 后缀的固件,然后等待刷机完成自动重启即可。
2020 年 11 月固件版本:3.0.0.4.386_40451_koolshare 2022 年 8 月升级到:3.0.0.4.386_41634_koolshare
启用 Clash 代理插件
禁用检测:
sed -i 's/\\tdetect\_package/\\t# detect\_package/g' /koolshare/scripts/ks_tar_install.sh
这里 是 shadowsocks 插件地址。
这里 是 Merlin Clash 插件。在这个 Telegram 频道中下载 merlinclash_hnd 开头的插件按照包。
在 Merlin firmware 下安装 Entware
Entware 是一个嵌入式设备的包管理工具,之前在 QNAP NAS 上也有安装过。
梅林内置了 entware 安装脚本,直接在终端执行:
entware-setup.sh
执行后 entware 会把软件安装在 /opt 目录下。
在安装 Entware 的时候记得一定保证网络环境畅通,否则下载下来的不完整的 opkg 二进制可能有各种问题,要不就是 Permission denied, 要不就是 Segmentation fault。
在安装了 Entware 之后,就可以非常方便的进行常用的包安装,比如安装 rsync:
opkg update
opkg install rsync
或者安装更加复杂的应用,比如说在路由器上
- 通过 Entware 安装 Transmission
- 安装 支持 PHP 的 Lighttpd Web 服务器
- 安装 Plex Server
- 安装 UPNP 服务器
等等很多特性,都可以在官方提供的页面 看到。
设置 Swap 分区
在之前的 Linux swap 分区 的文章里面提过,Swap 分区会在系统物理内存将满的时候被使用,虽然 AC86U 自身具备了 500 多兆的内存,但是如果跑多了应用可能会很快被用尽。所以如果看到内存将被用满,可以尝试创建 swap 分区。
如果是 Merlin 的固件,通过 SSH 登录后台之后直接运行 amtm,这是梅林固件自带的一个终端管理工具,在其中可以非常快速的通过交互命令创建 swap 分区。如果想手动创建也可以通过如下的方式纯手工进行设置。1
依次执行:
dd if=/dev/zero of=/tmp/mnt/sda1/swapfile bs=1024 count=512000
mkswap /tmp/mnt/sda1/swapfile
swapon /tmp/mnt/sda1/swapfile
然后,创建启动脚本:
echo '
#!/bin/sh
# Turn On Usage Of Swapfile
if [ -f "/tmp/mnt/sda1/swapfile" ];then
swapon /tmp/mnt/sda1/swapfile
echo "Turning Swapfile On"
fi
' >> /jffs/scripts/post-mount
增加执行权限:
chmod a+rx /jffs/scripts/*
这样系统每一次重启就会自动的使用该 swap 分区。
其他工具
可以通过 amtm 安装其他工具,比如:
dnscrypt-proxy, skynet, diversion, mini dns-server
扩展 Proxmox 系统分区以及 Proxmox 文件系统初识
昨天想要扩展一下之前安装的 Proxmox 容量,对系统进行了一次关机,然而关机之后就悲剧的发现在 U 盘中的系统启动不了了,将 U 盘拔下检测之后发现 U 盘可能挂了,一个全新的 U 盘,在连续 192 天运行之后挂掉了。无奈之下只能想办法先恢复一下 Proxmox 系统以及安装在系统之上的 OpenMediaVault 了。
恢复的过程倒也是很麻烦,只不过这一次想稳定一些,将系统还是安装在一块之前主力机上淘汰下的 SSD 上吧,所以用 Clonezilla 先备份 SSD 上的系统,然后将之前 U 盘上的 Proxmox 系统恢复到 SSD 上,做完之后发现 Clonezilla 实际上是将整块 U 盘上的分区表,分区一并搬到了 SSD 上,所以在磁盘里面能看到实际 Proxmox 系统只是占用了 32G 的大小。那这个时候就需要将现在的 Proxmox 分区扩展到整块磁盘了。
这个时候就需要复习之前整理过的两个命令了 fdisk 和 parted。fdisk 用来查看磁盘的分区详情,然后使用 parted 对磁盘分区进行扩容。
不过在进入正题之前,先提前警告一下,对磁盘的操作请格外小心,请先备份好数据,或者找一块闲置的磁盘进行操作,否则可能丢失整块磁盘的数据!
前提知识
Proxmox 的文件系统
在正式进入之前先来回顾一下 Proxmox 的文件系统,在全新安装的 Proxmox 系统上可以看到一块硬盘被划分了三个分区。
root@pve:~# fdisk -l /dev/sdd
Disk /dev/sdd: 232.9 GiB, 250059350016 bytes, 488397168 sectors
Disk model: Samsung SSD 850
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: AC6AD606-ED82-475B-A813-7----------2
Device Start End Sectors Size Type
/dev/sdd1 34 2047 2014 1007K BIOS boot
/dev/sdd2 2048 1050623 1048576 512M EFI System
/dev/sdd3 1050624 488397134 487346511 232.4G Linux LVM
上面已经是我扩容后的结果,扩容之前 sdd3 这个分区只有不到 30G。
说明:
- BIOS boot 分区是 GNU [[GRUB]] 来引导基于 Legacy BIOS 但是启动设备上有 GPT 格式分区表的操作系统时使用的分区。
- EFI System 分区是一块 FAT32 格式的分区,存储 EFI 引导程序以及启动时固件使用的应用程序。
- Linux LVM 分区则是系统真正可以使用的分区。LVM 是逻辑卷管理器,可以用来创建和管理逻辑卷,而不是直接管理磁盘,这就使得我们之后对分区大小进行调整变得可能。对 LVM 逻辑卷的扩大缩小并不会影响其中的已存储的数据。
接下来再来看看 LVM 分区下的逻辑卷。
Disk /dev/mapper/pve-swap: 3.5 GiB, 3758096384 bytes, 7340032 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/mapper/pve-root: 7 GiB, 7516192768 bytes, 14680064 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/mapper/pve-vm--100--disk--0: 32 GiB, 34359738368 bytes, 67108864 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 65536 bytes / 65536 bytes
Disklabel type: dos
Disk identifier: 0x4236f4d0
Device Boot Start End Sectors Size Id Type
/dev/mapper/pve-vm--100--disk--0-part1 * 2048 56868863 56866816 27.1G 83 Linux
/dev/mapper/pve-vm--100--disk--0-part2 56870910 67106815 10235906 4.9G 5 Extended
/dev/mapper/pve-vm--100--disk--0-part5 56870912 67106815 10235904 4.9G 82 Linux swap / Solari
从 fdisk -l 的输出可以看到 Proxmox 创建了三个逻辑卷分区:
/dev/mapper/pve-swap是 swap 分区/dev/mapper/pve-root是 Proxmox 的 root 分区 7 GB/dev/mapper/pve-vm--100--disk--0则是我在其中安装的 OpenMediaVault 划分给了它 32 GB 空间
使用 lvdisplay 可以看到逻辑卷的详细信息。可以看到 /dev/mapper/pve-root 就是 pve 卷组里面的逻辑卷。
root@pve:~# lvdisplay
--- Logical volume ---
LV Path /dev/pve/swap
LV Name swap
VG Name pve
LV UUID cYatZ5-kif7-n8N2-v9c5-UOlb-wfLJ-qt35G7
LV Write Access read/write
LV Creation host, time proxmox, 2020-11-10 18:42:21 +0800
LV Status available
# open 2
LV Size 3.50 GiB
Current LE 896
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
--- Logical volume ---
LV Path /dev/pve/root
LV Name root
VG Name pve
LV UUID dc0VlK-7DSo-lgzw-7Zxy-aK3s-jlTc-TPOmDA
LV Write Access read/write
LV Creation host, time proxmox, 2020-11-10 18:42:22 +0800
LV Status available
# open 1
LV Size 7.00 GiB
Current LE 1792
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:1
--- Logical volume ---
LV Name data
VG Name pve
LV UUID oNuSZd-JoDA-1jPW-Wdcs-q59D-vuDx-fDnUab
LV Write Access read/write
LV Creation host, time proxmox, 2020-11-10 18:42:22 +0800
LV Pool metadata data_tmeta
LV Pool data data_tdata
LV Status available
# open 2
LV Size 219.88 GiB
Allocated pool data 1.72%
Allocated metadata 1.84%
Current LE 56290
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:4
到这里其实就能看到 Proxmox 安装的时候实际上创建了一个叫做 pve 的卷组 (Volume Group),然后在上面分别创建了 swap, root, data 三个逻辑卷 (Logical Volume)。
什么是 LVM
LVM 是 Logical Volume Manager 逻辑卷管理的简称。
LVM 对底层的物理磁盘进行封装,向上以逻辑卷的形式提供。当上层的应用要访问文件系统的时候,不是通过直接操作分区,而是通过 VLM 的逻辑卷,对底层的磁盘进行管理。
LVM 最大的特点是可以对磁盘进行动态管理,逻辑卷大小可以在变更文件内容情况下动态调整。
基本术语
存储介质,系统的存储设备,比如常见的硬盘等等。
Physical Volume 物理卷,物理卷在逻辑卷管理中的最底层,实际上是物理硬盘的分区,也可以是整个物理硬盘。
Volume Group 卷组,建立在物理卷之上,一个卷组至少要包括一个物理卷,卷组建立之后可以动态添加物理卷到卷组中。逻辑卷管理系统中可以只有一个卷组,也可以拥有多个卷组。
Logical Volume 逻辑卷,建立在卷组之上,卷组中未分配的空间可用于建立新的逻辑卷,逻辑卷建立之后可动态地扩展和缩小空间。
扩容过程
如果 Proxmox 没有安装 parted 先安装:
apt update && apt install -y parted
安装后再执行 parted -l 列出分区信息。
如果有弹出 Fix/Ignore 的提示,输入 Fix 快速修复。
扩容分区
使用 fdisk -l 来查看 Proxmox 在哪一块磁盘,以及磁盘上的分区信息,文章之前以及提过,可以看到 Proxmox 划分的三个分区没有完全利用 SSD 的全部空间。
对于我的系统,我的 Proxmox 安装在 sdd 这块硬盘上,使用 parted 对磁盘分区进行操作:
parted /dev/sdd
进入交互模式后,可以使用 print 来查看分区信息,可以看到 LVM 分区只用了很小一部分空间,扩容:
resizepart 3 100%
这里的 3 指的是分区编号,一定小心。
然后退出:
quit
这个时候已经将磁盘剩余的空间都划分给了 /dev/sdd3
可以使用 fdisk -l 或 parted 的 print 来查看。
root@pve:~# parted /dev/sdd
GNU Parted 3.2
Using /dev/sdd
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) print
Model: ATA Samsung SSD 850 (scsi)
Disk /dev/sdd: 250GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 17.4kB 1049kB 1031kB bios_grub
2 1049kB 538MB 537MB fat32 boot, esp
3 538MB 250GB 250GB lvm
更新物理卷的大小:
pvresize /dev/sdd3
提示更新成功。
扩容逻辑卷
查看 Proxmox 的逻辑卷内容,cat /etc/pve/storage.cfg 可以看到:
root@pve:~# cat /etc/pve/storage.cfg
dir: local
path /var/lib/vz
content iso,backup,vztmpl
lvmthin: local-lvm
thinpool data
vgname pve
content rootdir,images
local-lvm 是对应着 vgname 这个叫做 pve 的 Volume Group 中的 data 名字的逻辑卷。
使用 lvdisplay 可以看到:
--- Logical volume ---
LV Name data
VG Name pve
LV UUID oNuSZd-JoDA-1jPW-Wdcs-q59D-vuDx-fDnUab
LV Write Access read/write
LV Creation host, time proxmox, 2020-11-10 18:42:22 +0800
LV Pool metadata data_tmeta
LV Pool data data_tdata
LV Status available
# open 2
LV Size 29.88 GiB
Allocated pool data 1.72%
Allocated metadata 1.84%
Current LE 56290
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:4
这里的 LV Size 就是逻辑卷的大小。
然后使用 pvs 查看物理卷的使用情况,在 PFree 里面能看到有很大部分的空间是没有使用的。
然后利用 lvextend 命令进行逻辑卷的扩容:
lvextend -l +100%FREE /dev/pve/data
上面的命令会将 100% 空间划分给 data,如果只想要增加 10 GB,那么:
lvextend -L +10G /dev/pve/data
如果熟悉 lvresize 也可以:
lvresize --extents +100%FREE --resizefs /dev/pve/data
然后可以使用 pvs 和 lvdisplay 进行查看。
reference
『译』我最喜欢的命令行工具
偶然间看到一篇介绍 cli 的文章,感觉写得不错,正好借此机会也整理一下我之前使用过,以及觉得非常值得推荐的 CLI 工具。
下面就是译文全文。原文可以见 https://switowski.com/blog/favorite-cli-tools
下面是一个很长的列表,如果觉得不想完整的看完,这里提供一个简介。
- fish shell 一个简单易用的 shell
- starship 一个不需要额外设置的终端提示
- z 可以在文件系统中快速跳转
- fzf 模糊搜索
- fd
find命令的代替 - ripgrep
grep的代替 - htop and glances 系统监控工具
- virtualenv and virtualfish, Python 虚拟环境管理
- pyenv, nodenv, and rbenv, Python, Node, 和 Ruby 的多版本管理
- pipx 将 Python 的包安装到隔离的环境
- ctop and lazydocker, Docker 的监控工具
- homebrew, MacOS 上的包管理
- asciinema, 录制终端的会话(并且可以让观看者直接从录制中复制代码)
- colordiff and diff-so-fancy, 带有颜色的
diff工具 - tree, 展示文件夹的结构及内容
- bat, 更好的
cat - httpie, 更好的
curl - tldr, 简化版的
man pages - exa, 更好的
ls - litecli and pgcli, 更好的
sqlite3和psql - mas, App Store 的 CLI 版
- ncdu, 磁盘使用分析工具
fish-shell
每一次打开终端使用最多的就是 Shell。过去我使用过 Bash 和 Z shell,但是现在我使用 fish。这是一个非常棒的 shell,拥有很多开箱即用的特性,比如自动提示 (auto suggestions), 语法高亮,或者是切换文件夹 (⌥+Left 或者 ⌥+Right)。
换句话说,这对新手非常友好,你不需要设置任何东西。但是另一方面,fish 使用不同于其他 shell 的另一种语法,所以通常你并不能直接复制粘贴来使用互联网上的脚本。你要不就是将脚本改成适合 fish scripts 语法,要不就只能打开一个 Bash 会话来执行脚本。我能理解 fish 背后不兼容的原因 (Bash 是一门不是那么容易理解的语言)。我很少编写 bash/fish 脚本,所以每一次使用都得从头再来。并且相较于 bash 脚本,fish 脚本的资料更少,所以我通常就只能阅读文档,而不是从 StackOverflow 来复制拷贝已经编写好的脚本。
是否要推荐 fish ? 答案是 Yes!切换 Shell 非常简单,尝试一下吧。尤其是当你不喜欢对你的 Shell 修修补补,或者想要通过最少的配置来达到很好的效果。
Fish plugins
你可以通过给 fish 安装插件来扩展功能。通过插件管理工具可以非常轻松的安装和管理,比如 Fisher, Oh My Fish,或者 fundle。
目前我只使用三个插件:
- franciscolourenco/done,当长时间执行的脚本完成后发送系统通知。我不会长时间开着终端,而是使用 Guake style 终端,当我需要的时候从屏幕的上方显示,当我不需要的时候就隐藏。使用这个插件的时候,当我执行一个耗时比较长的任务的时候,当完成的时候会发送一个桌面通知。
- evanlucas/fish-kubectl-completions, 提供了
kubectl命令的自动补全。 - fzf,将 fzf 和 fish 集成 (见 fzf)
过去我常常会使用很多插件 (rbenv, pyenv, nodenv, fzf, z),但我切换到一个不同的 shell 来避免拖慢我的 shell。
如果你想了解更多 fish 的资料,可以查阅 awesome-file 这个仓库。和 Z shell 和 Bash 相比,fish 只有更少的插件,如果你经常调整你的 Shell,这可能不是最好的选择。但是对我而言,这却是一个益处,这使得我不再启用很多的插件,然后再抱怨太慢。
Starship
如果要我在这个列表里面选择一个最喜欢的工具,那就是 Starship。Starship 是一个终端提示 (prompt),它可以和任何 Shell 搭配使用。如果你安装了它,你只需要在 .bashrc / .zshrc / config.fish 中添加一行即可。
它可以显示:
- 当前目录的
git status信息,以及不同的标识来显示是否有新文件,或者有更改等等。 - 如果你在一个 Python 项目目录下会显示 Python 的版本 (同样的道理在 Go/Node/Rust/Elm 等等其他语言中也一样)
- 命令执行的时间(如果超过几秒钟的话)
- 如果上一个命令失败了会有错误提示
z

z 可以让你在文件系统中快速跳转。它会记住你曾经访问过的文件夹路径,经过一段时间后,你可以快速的直接使用 z path 来跳转。
比如,我经常访问的目录 ~/work/src/projects,我可以直接执行 z pro 然后立即跳转过去。z 的算法基于频率,基于频率和最新访问的组合。如果它记住了一个不常使用的目录,你可以在任何时间手动移除它。
这个工具大大地提高了在常用的目录间切换的效率,并且节省了大量的击键次数。
fzf
fzf 表示 “fuzzy finder”, 这是一个通用工具,可以让你来查找文件,历史中的命令,进程名,git 提交历史,和其他更多的模糊查找。你可以敲入一些字母,然后尝试在结果中匹配这些字母。敲入的字母越多,搜索结果越精确。你可能在代码编辑器中曾经看到过这种搜索,当你想要打开一个文件,你不需要敲入完整的路径,只需要敲入部分文件的名字,这就是模糊搜索。
我通过 fish fzf 插件 来使用,我可以快速找回历史命令,或者快速打卡一个文件。
fd

和 find 命令类似,但是易用,更快,并且拥有一个默认的设置。
如果你想找一个叫做 invoice 的文件,但是你不确定它的扩展名? 或者你想要找一个放着所有发票的文件夹?你可以卷起袖子开始为 find 命令编写正则表达式,或这直接运行 fd invoice。
默认情况下,fd 会忽略任何在 .gitignore 中列出的文件和目录。大部分情况下,这就是你想要的,但是对于那些极特殊的情况,我有一个 alias : fda='fd -IH'
输出的结果是带颜色的,并且根据 benchmarks,它甚至比 find 要快。
ripgrep

和 fd 类似,ripgrep 是 grep 的一个代替品,并且非常快,健全的默认值以及彩色的输出结果。
它会跳过在 .gitignore 中定义的文件,以及隐藏的文件,你可以设置 alias: rga='rg -uuu'。他会禁用所有的智能过滤,让 ripgrep 和普通的 grep 一样。
htop and glances
在 Linux 或者 Mac 上显示进程信息的工具就是 top,他是每一个系统管理员的好朋友。即使你通常在开发网站,也是一个不错的工具。你可以查看是否是你的 Docker 或者 Chrome 吃光了你的 RAM。
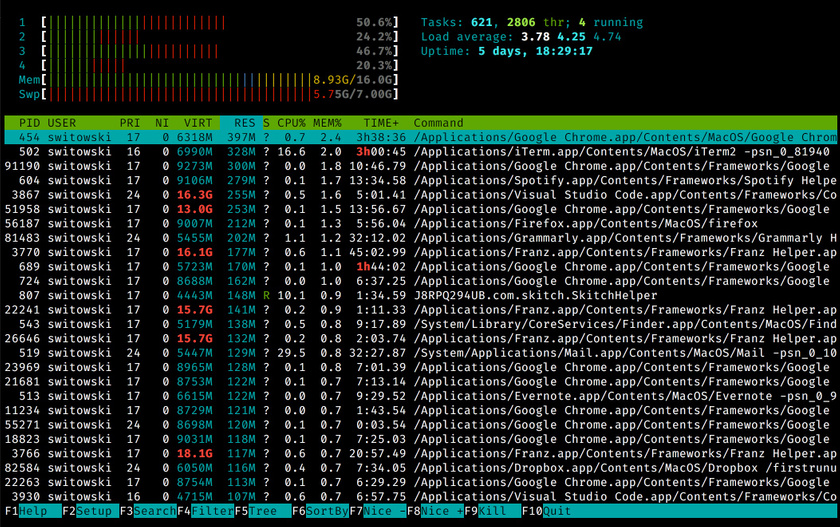
top 工具非常基础,所以大部分的人切换到了 htop。htop 在此基础上,增加了颜色,拥有丰富的选项,并且用起来非常方便。
glances 是 htop 的一款互补的工具。除了列举了所有进程的 CPU 和内存使用,它还展示系统一些其他额外的信息。
你可以看到:
- 网络或磁盘的使用
- 文件系统使用以及全部的空间
- 其他 sensor 的数据,比如电池
- 最近使用了大量资源的进程
我使用 htop 来快速过滤并杀死进程,但是我使用 glances 来快速查看电脑的状态。Glances 提供了 API,Web UI,等等不同的输出格式,这样你就可以将系统的监控带到另一个层级。
virtualenv and virtualfish
virtualenv 是一个用来创建 Python 虚拟环境的工具。
pyenv, nodenv and rbenv
Pyenv, nodenv, and rubyenv 是用来管理不同版本的 Python,Node,和 Ruby 的工具。
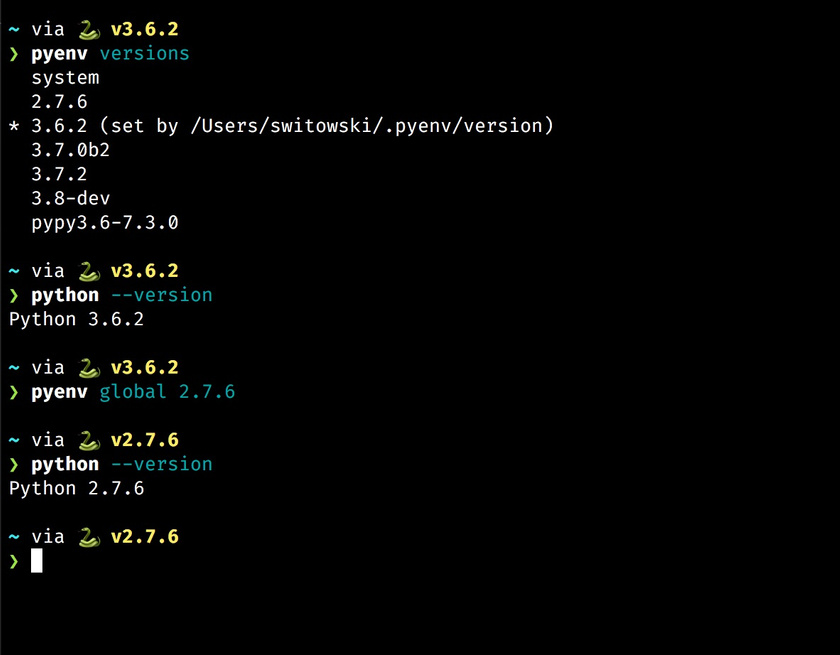
最近我又发现了一个叫做 asdf 的工具, 可以用来代替 pyenv, nodenv, rbenv, 和其他 envs 工具。它提供了几乎任何语言的版本控制。
pipx
virtualenv 解决了 Python 包管理的问题,但还剩下一个问题。如果我想全局安装一个 Python package (因为这是一个独立的工具,比如 glances)。在虚拟环境之外安装包是一个不好的主意,可能导致未来的问题。但换一个角度,如果我决定使用 virtual environment, 那么每一次我想使用这个工具,我都需要重新激活这个 virtual environment。这不是一个方便的解决方法。
那么 pipx 解决的就是这样的问题,它会将 Python 安装到一个独立的环境中(这样他们的依赖就不会冲突)。但是,与此同时,CLI 工具是全局可访问的。我不需要激活任何东西,pipx 帮我完成了一切。
如果想要了解更多 Python 工具的使用,以及作者如何使用它们,作者在 PyCon 2020 会议上做了一次分享 “Modern Python Developer’s Toolkit”,这是伊恩两小时的教程,如果感兴趣可以观看这个录制的视频。
ctop and lazydocker
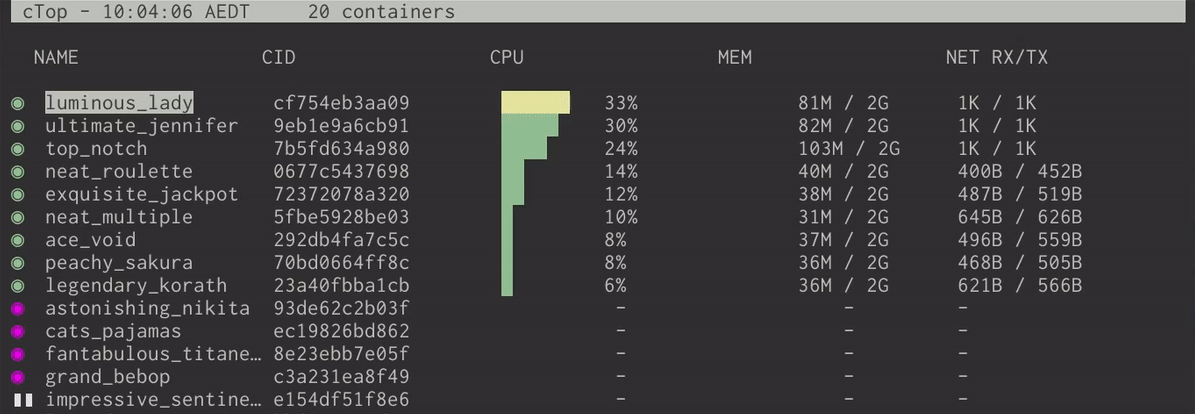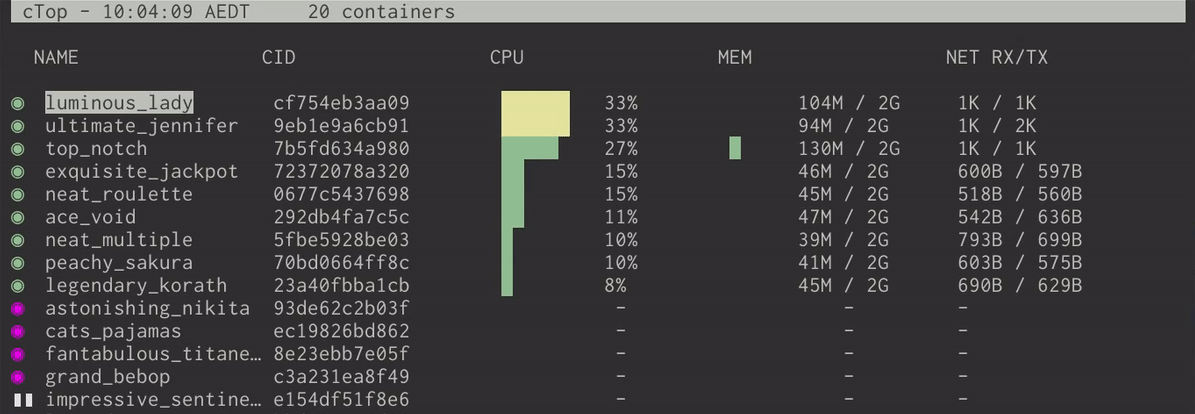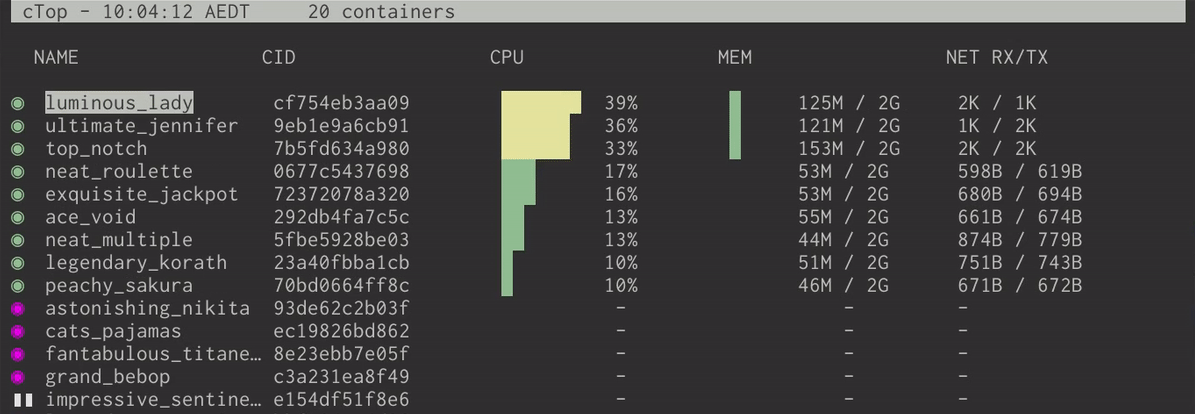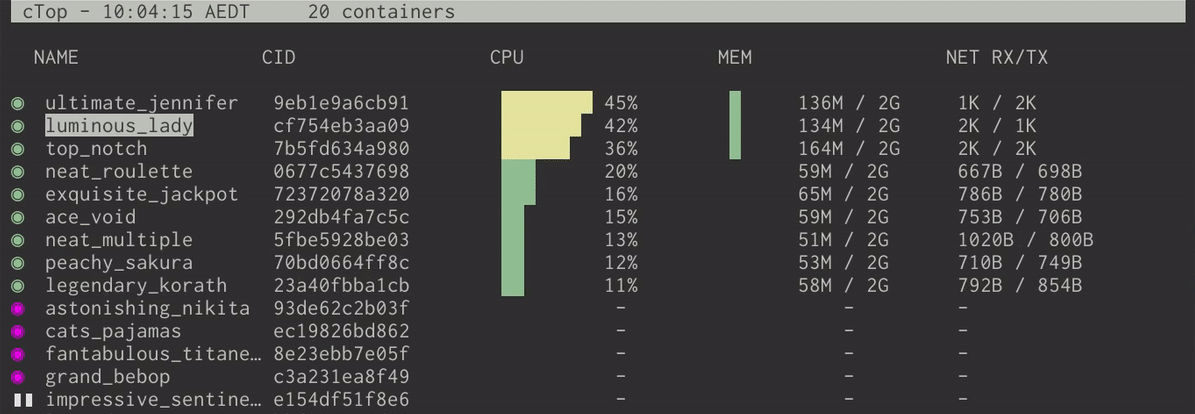
当你使用 Docker 时,你会发现这两个工具非常有用。ctop 是一个给 Docker 容器的 top-like 界面,它可以:
- 显示当前正在运行或者已经停止的容器
- 每一个容器的内存,CPU 等等信息
- 一个快速的菜单来停止,杀死,或者显示给定容器的日志
这要比使用 docker ps 来显示这些信息来得方便许多。
如果你觉得 ctop 很 cool,那么尝试一下 lazydocker 吧!这是一个用来管理 Docker 成熟的终端 UI 界面。
一些我不是每天使用的工具 Tools that I don’t use every day
除了上面提到的这些我每天在使用的工具,还有一些我收集了数年,并且发现在特定场景非常有用的工具。比如说录制终端的 GIF(可以让你暂停并且复制文字),显示文件夹结构,连接数据库的工具等等。
Homebrew
如果你使用 Mac ,那么 Homebrew 自然无须多言,这是一个事实上的 macOS 包管理。它甚至还有一个 GUI 的版本 Cakebrew.
asciinema
asciinema 是一个可以用来录制终端会话的工具。但是不像其他的 GIF 录制工具,它可以允许观看的人选择并复制录制过程中的代码。
这对于录制编程教程非常有用,没有什么能比敲入一大串长长的命令要令人沮丧的了。
colordiff and diff-so-fancy
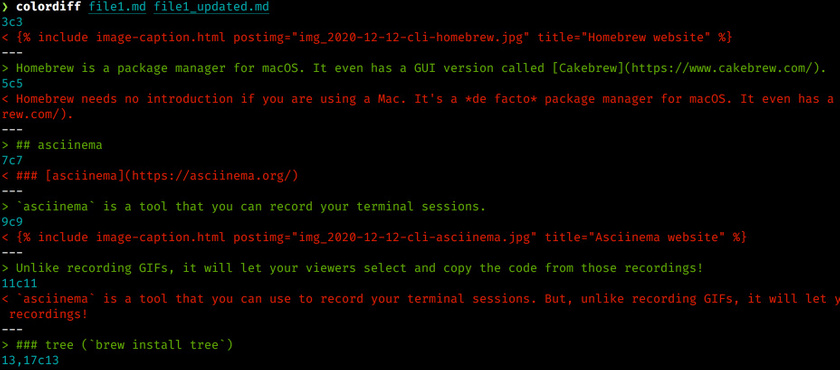
我现在很少在终端中比较两个文件的差异了,但是如果你经常做,那么尝试用 colordiff 代替 diff 命令。colordiff 命令会给结果着色,这样就非常容易文件的差异了。
如果运行 git diff 或者 git show,那么还有一个更好的工具叫做 diff-so-fancy,它提供了:
- 高亮变化的单词,而不是整行
- 简化了变化文件的 headers
- 省去了加号和减号,已经有了颜色
- 显示新增和删除的空行
tree
如果你想要展示给定文件夹的内容,tree 是一个首选的工具 (go-to tool)。它会显示所有的子目录和其中的文件,并以 tree 的显示显示。
bat
和 cat 类似用来显示文件内容,但是更好,增加了语法高亮,git gutter marks(当可用的时候), 自动翻页(如果文件很大的话),最后就是让文件更易读。
httpie
如果你需要发送一些 HTTP 请求,你可能会发现 curl 不是非常易用,那么尝试一下 httpie.
tldr
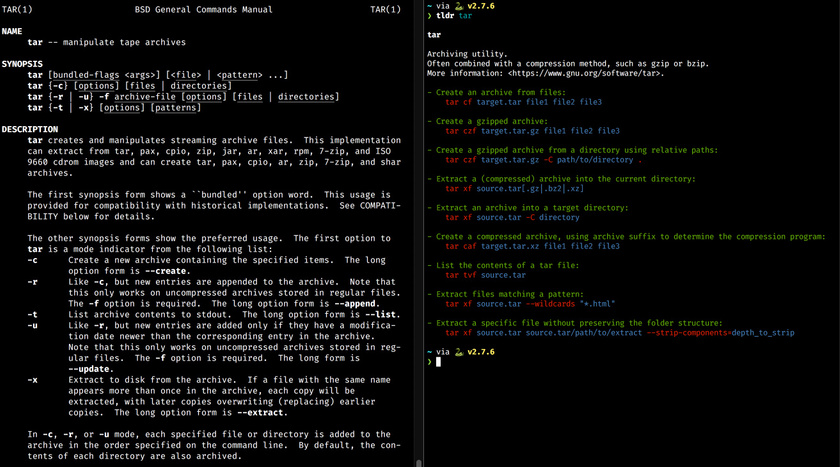
更简单的 man pages,”man pages” 是 Linux 软件的手册,解释了如何使用这些命令。尝试一下运行 man cat 或者 man grep。但是 man 手册通常非常详细,并且有些复杂一些的命令可能需要花一些时间来理解。tldr 是一个社区驱动的项目,提取了 man page 中重要的内容提供一些简洁的例子。
tldr 提供了大部分的命令行工具例子,这是社区的力量,但是也有很小的可能其他人编写的文档可能会误导你。但是大部分的情况下,还是能够找到你想要的内容。
比如你想要 gzip 压缩一些文件,man tar 大量的说明可能使得你无从下手,但是 tldr tar 显示了常用的例子,你可以立刻知道你想要的内容。
exa
exa 是一个 ls 的代替。
彩色的显示输出,将文件大小转换成可读的,并且保持了 ls 的速度。
litecli and pgcli
地址:https://litecli.com/ 和 https://www.pgcli.com/
SQLite 和 PostgreSQL 的首选 CLI 工具,它提供了自动补全以及语法高亮,他们比默认的 sqlite3 和 psql 好用多了。
另外感谢 laixintao 在留言中推荐的 dbcli 一整套数据库 CLI 工具链,包括了 PostgreSQL, MySQL, SQLite, MS SQL Server, Redis, AWS Athena, VerticaDB 等等数据库的 CLI 客户端连接工具。
mas
地址:https://github.com/mas-cli/mas
mas 是 App store 的命令行版本。它用来初始化的时候设置 Macbook,并且可以写成脚本来复用。
mas 可以让我自动安装命令,而不需要在 App Store 中点点点。既然你在阅读 CLI 相关的文章,那么我假设,你和我一样,不喜欢 Click。
ncdu
官网地址:https://dev.yorhel.nl/ncdu,也可以参考之前的文章。
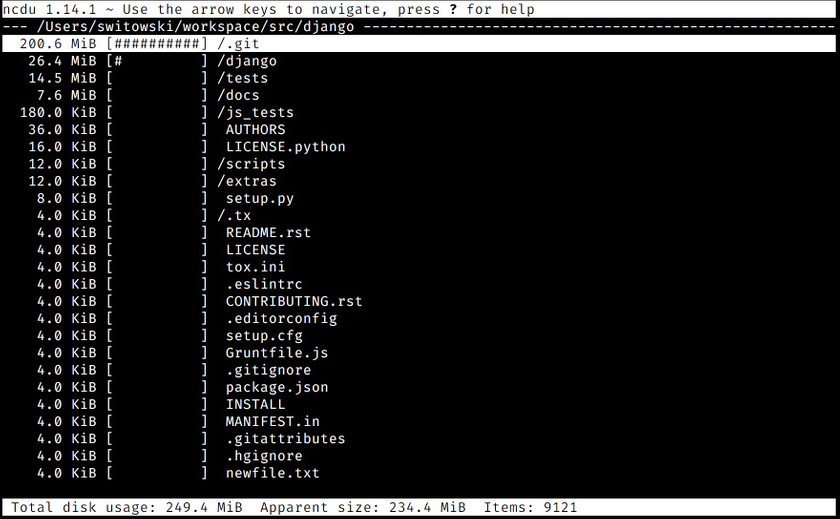
ncdu 是终端中的磁盘分析工具。快并且易用。
最后
本文的作者叫做 Sebastian,是一位 Python 开发者,我征得其同意后 翻译了这篇文章。作者介绍了不少很好的工具,我之前也有再用,同时也介绍了不少我第一次听说的工具,比如 SQLite 和 PostgreSQL 的连接工具。总之这是一篇不错的文章,分享一下。
使用 Clonezilla 将硬盘中系统恢复到虚拟机中
今年陆陆续续将工作的环境迁移到了 macOS,虽然已经把日常的资料迁移到了 macOS,但是之前的 Linux 上还有一些配置,以及可以的一些测试还需要用到 Linux 虚拟机,所以我就想能不能用 Clonezilla 将磁盘中的系统备份然后恢复到虚拟机里面。因为我发现 macOS 下的 Fusion 还是很强大的。
之前已经写过使用 Clonezilla 备份和恢复系统、使用 Clonezilla 克隆系统, Clonezilla 恢复系统时可能遇到的问题 ,这里关于备份的部分就不再赘述。
准备工作
开始之前需要先准备几个东西:
- 备份好的系统镜像,最好是能放到移动硬盘中
- Clonezilla ISO 镜像
- 安装好的 Fusion 软件
- 足够的空间可以恢复系统镜像
恢复工作
通过 Clonezilla 将整块硬盘备份成为 Images,然后在 Fusion 中新建虚拟机 Ubuntu 64 bit 类型。
- 在新建的虚拟机设置中,CD/DVD (SATA) 中装载 Clonezilla 的 ISO 镜像。
- 在 USB & Bluetooth 中,Advanced USB options,将 USB Compatibility 选为 USB 3.1
- 在 Startup Disk 中选择 CD/DVD 作为启动设备
- 启动虚拟机
- 这个时候会进入 Clonezilla 的界面,之后的步骤就和在 Clonezilla 中恢复一个 Image 一样了。等待恢复一段时间即可完成。
问题
问题: The device ‘xxx’ was unable to connect to its ideal host controller.
在虚拟机设置 USB 设置里面,确保使用 USB compatibility 3.0 以上。
具体解决方法:
- 关闭虚拟机
- 到 Settings -> USB & Bluetooth 设置中,可以看到插入的 USB 设备
- 在 Advance USB options 中
- USB compatibility: USB 3.1
- 启动虚拟机,启动后在 UBS 设置中勾选需要分享的 USB 设备
from: https://communities.vmware.com/t5/VMware-Fusion-Discussions/USB-3-0-support/m-p/1288281
kindlepush_bot 机器人使用指南
这是一篇 Telegram kindlepush_bot 机器人绑定邮箱的教程。
推送邮箱绑定指南。
使用 163 邮箱作为推送邮箱
使用电脑登录 https://mail.163.com ,右上角「设置」,选择「POP3/SMTP/IMAP」设置。
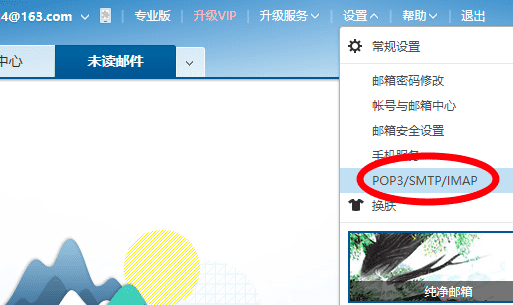
在设置中,勾选 「POP3/SMTP 服务」,这个时候会弹出一个确认界面,点击确认,设置授权码。
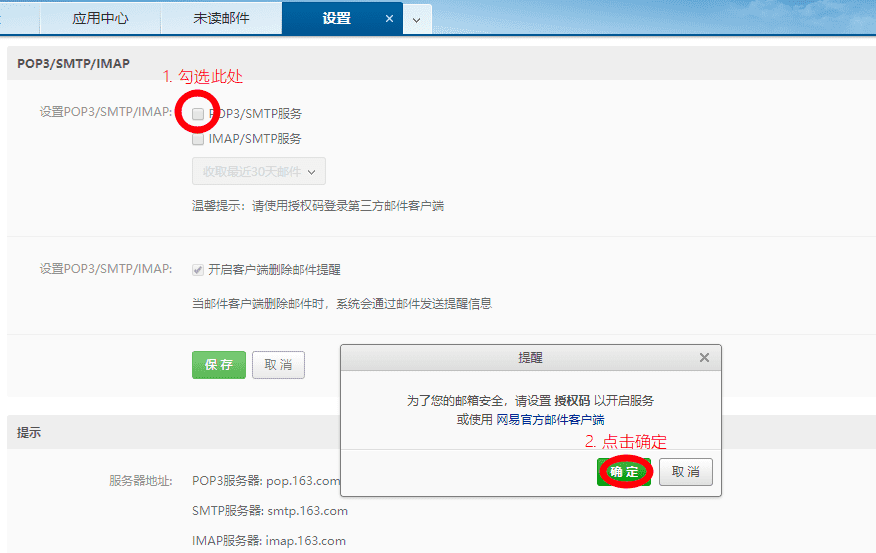
开启「设置客户端授权码」,这个时候绑定的手机会收到一个短信。记住该授权码。
将完整的邮箱和授权码,作为发送者邮箱和发送者密码发送给机器人即可。
最后不要忘了到 Amazon 后台将自己的发送邮箱设置为可信邮箱。
在设置的时候如果遇到 (550, b’User has no permission’) 错误。需要设置:
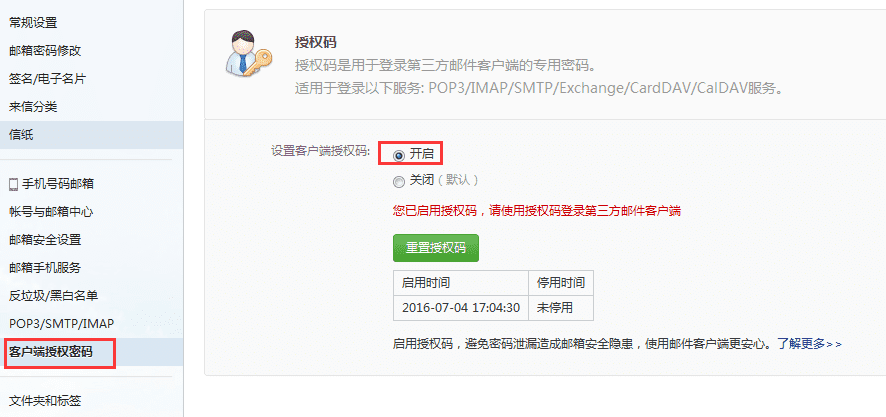
如果遇到 (535, b’Error: authentication failed’) 错误,同样需要使用 163 邮箱的授权码,而不是密码。
使用 QQ 邮箱作为推送邮箱
为了你的帐户安全,更改 QQ 密码以及独立密码会触发授权码过期,需要重新获取新的授权码登录。
进入设置 -> 账户,开启 POP3/SMTP 服务。

根据提示验证密码。
获取授权码。
使用 Gmail 作为推送邮箱
建议开启二步验证后使用专有密码来设置 kindlepush_bot 的发送密码。
首先登录:
选择「安全性]
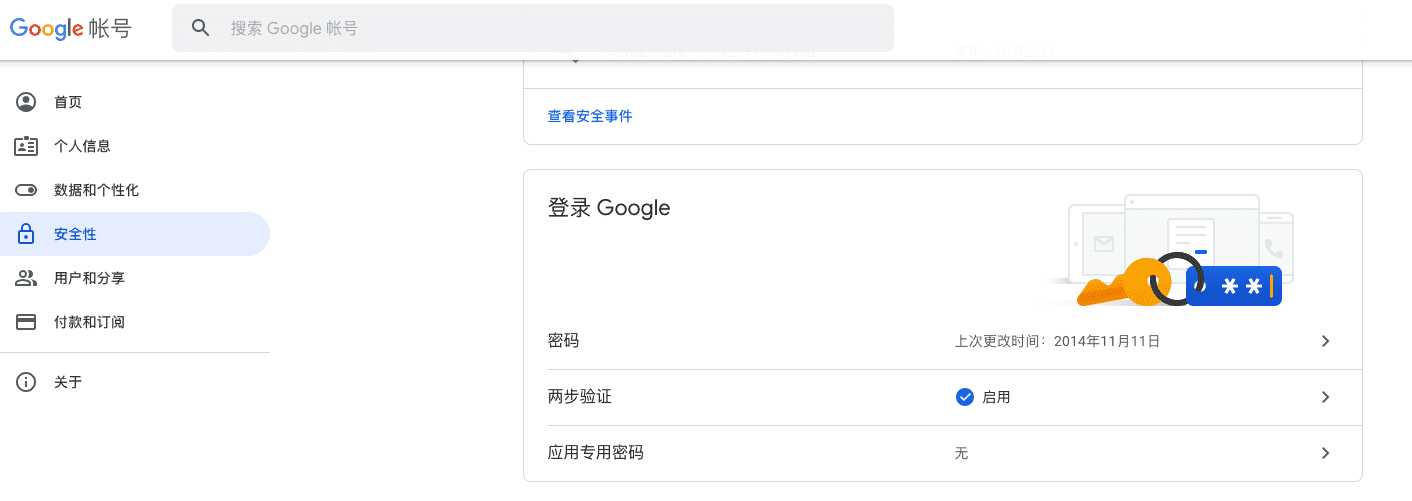
点击应用专用密码。中间可能需要重新输入密码。
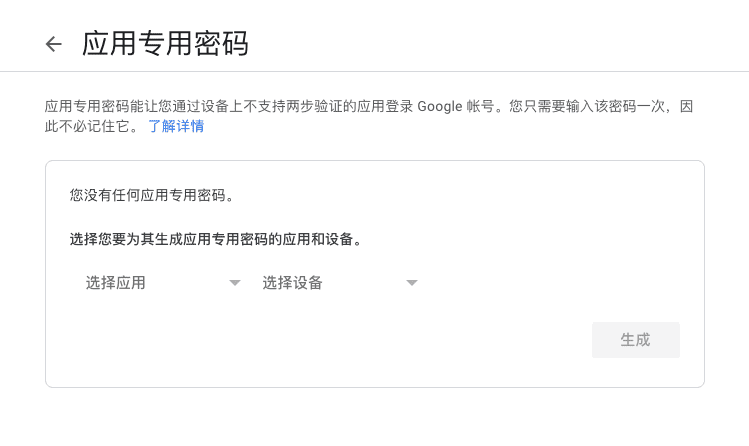
选择自定义名称:
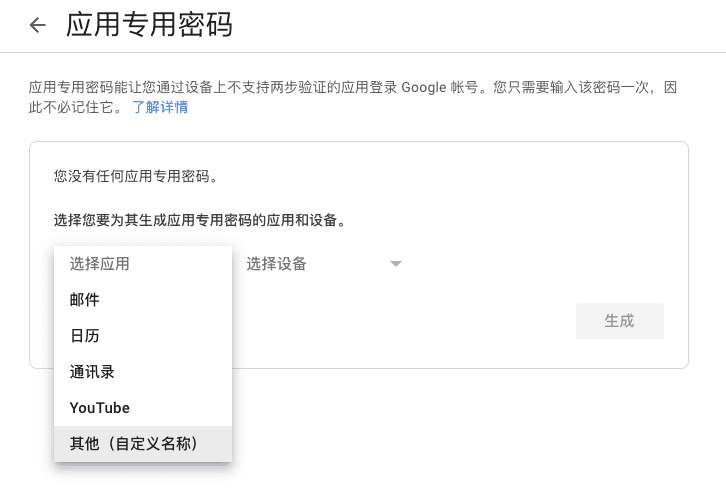
输入 kindlepush_bot,获取一次性的验证码。
使用 Gmail 密码
登录 Gmail 账户
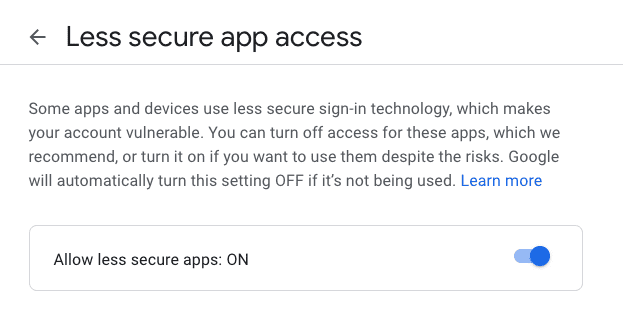
在设置页面开启 less secure apps https://www.google.com/settings/security/lesssecureapps
然后登录 https://accounts.google.com/DisplayUnlockCaptcha 根据提示进行设置
通用文档转换工具 Pandoc
如果要在不同格式的文档文件之间转换,pandoc 就是你的瑞士军刀。Pandoc 支持非常多的文档转换。从最简单的纯文本 markdown, AsciiDoc, reStructuredText 到 LaTeX,到 docx,甚至 jira wiki 的格式,也都可以相互转换。具体可以参考官网。
IPFS 介绍
IPFS 的全称是 「InterPlanetary File System」,直译过来叫做「星际文件系统」,这是一个点对点的媒体传输协议,作者创建这个项目的目的是为了建立一个持久的,分布式的文件系统。1
A peer-to-peer hypermedia protocol designed to make the web faster, safer, and more open.
IPFS 白皮书由Juan Benet 发表于 2014 年。
IPFS 允许用户不仅可以接受文件,还可以托管文件内容,类似 BitTorrent 协议的方式,网络节点中的每一个节点都可以既是客户端也是服务端。
和中心化的系统不一样的地方在于,IPFS 构建了一个去中心化的系统,任何用户都可以存储所有数据中的一部分,IPFS 网络创建了一个可以快速恢复的文件存储和分享系统。
任何用户都可以通过内容地址来分享文件,网络中的任何对等节点都可以通过分布式散列表 (Distributed Hash Table DHT) 来查找和请求文件内容。
IPFS 项目源码:https://github.com/ipfs
IPFS 设计前提
在白皮书中,作者概括了 IPFS 的设计:
- peer-to-peer; no nodes are privileged
- IPFS nodes store IPFS objects in local storage
- Nodes connect to each other and transfer objects
- objects represent files and other data structures
IPFS 网络和传统网络的区别
首先,让我们来看一下目前的互联网,现在互联网上的大部分内容都依赖于一些大型或小型的服务器托管商。如果你要架设一个网站,你需要花钱购买一个服务器,或者找能够托管内容的提供商,然后将产生的内容放置到服务中,这样当你提供内容时,别人都可以访问这一个中心化的节点来获取。而对于 IPFS ,任何人都可以注册一个节点,开始托管自己的内容,不管是在 Raspberry Pi 上,还是跑在世界上最大的服务器集群中,你自己的节点都可以成为一个非常高效的节点。因为即使你这个节点宕机了,只要在网络上还有地方存储着这部分内容,其他人都可以获取到。
IPFS 网络和普通网络的第二点区别在于,IPFS 的数据是内容寻址 (content-addressed),而不是地址寻址 (location-addressed). 这是一个微妙的区别,但是结果却是巨大的。
目前如果你打开浏览器,输入 example.com,你是告诉浏览器「帮我获取存放在 example.com 的 IP 地址的数据」,这可能存放在 93.184.216.34 这台服务器中,然后你就请求这个 IP 地址的内容,然后服务器会将相关的内容返回到浏览器。(当然现代网络依赖的 DNS 系统,以及浏览器内部的实现细节这里就略过)。所以基本的逻辑是,你告诉网络你要查找地址,然后互联网会将找到的内容返回。
但是 IPFS 扭转了这一逻辑。
在 IPFS 网络中,每一个存放在系统的单一区块数据都会生成一个由自身内容产生的密码散列 (Hash),也就是说,每一个块都会有一个唯一的由字符串和数字组成的串。当你想要在 IPFS 网络中获取数据时,你会请求这一个 HASH,所以并不是请求网络说「告诉我存放在 93.184.216.34 这个地址的内容」,而是说「请将 Hash 值为 QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy 的内容告诉我」,而 QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy 正好是一个包含了 “I’m trying out IPFS” 的 .txt 文件的 Hash。
那这样做有什么好处呢?
首先,这使得网络更有弹性,Hash 值是 QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy 的内容可能被存放在成千上万的节点中,即使有一个节点 Crash 或者下线了,也不影响其他缓存过这个 Hash 的其他节点。
第二,这个方式提高了安全级别。比如说你想要某一个 Hash 的文件,所以你向网络请求,给我 Hash 值是 QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy 的内容,然后网络响应请求,然后发送数据。当你接受了所有的数据,你可以重新计算 Hash,如果数据在传输的过程中被更改了,那么你重新计算的 Hash 就和请求的 Hash 不一致。你可以想象 Hash 就像是文件的唯一指纹。如果你接收到了一个和希望的不一致的内容,他们将拥有不同的指纹。这意味着这个方式实现的网络会知道这个内容是否被篡改了。
IPFS 解决的问题
和传统的互联网相比,IPFS 不仅解决了内容从互联网消失的问题,并且在抵抗审查,抵抗大规模监控等等方面都要比传统的互联网要有优势。
IPFS 地址和密码散列
既然上面提到了 content-addressed 系统的独特性,这就值得再来聊一聊 IPFS 地址是如何产生的。
每一个 IPFS 地址都是一个 multihash,这意味着每一个地址既包含了 Hash 算法也包含了 Hash 值。
IPFS multihashes 有三个不同的部分:
- multihash 的第一个字节 (byte) 表示产生这个 Hash 的算法
- 第二个 byte 表示 Hash 的长度
- 剩下的 byte 表示 Hash 的结果
默认情况下,IPFS 使用 SHA-256 Hash 算法,会产生一个 32-byte 的 Hash。然后使用 Base58 来表示,这也就是为什么每一个 IPFS 地址都以 Qm... 开头。
虽然 SHA-256 算法是当今的标准,但是这个 multihash 格式允许 IPFS 协议自由的更改 Hash 算法。这就使得 如果在未来发现了 SHA-256 算法的缺陷,IPFS 网络可以迁移到另外的算法。如果有人使用其他的 Hash 算法,那么最后的地址可能就不是以 Qm 开头了。
IPFS 可以做什么?
经过上面这么多解释可以知道,IPFS 本质上是一个分布式的文件共享系统,所以互联网能用来做什么,IPFS 也能做到。并且 IPFS 可以做的更好。
适合下面的场景:
- 归档文件,IPFS 自身会进行去重,并且提供了非常庞大的存储能力,适合归档文件
- 提供服务,IPFS 提供了安全的点对点文件传输,非常适合文件的分发,尤其是在分发大文件时可以节省大量的带宽。
IPFS Gateway
IPFS Gateway 网关提供了互联网用户访问托管在 IPFS 网络上内容的一种能力。ipfs.io 网关是由社区运营由 Protocol Labs 资助以帮助开发者的工具。
- Cloudflare 提供的网关 https://cloudflare-ipfs.com/
其他一些公共的网关可以在这个列表里面找到
如果想要了解更多 IPFS Gateway 相关的内容,可以到 https://docs.ipfs.io/concepts/ipfs-gateway/ 了解。
上传文件到 IPFS
上传到 IPFS 网络的第一张图。
https://ipfs.io/ipfs/QmcTzSJspTbafYWR1B8RqncNcvsaxnKQJmbtTU6GUkLJ8j
在 目录 中。
IPNS
IPFS 使用基于文件的寻址,这就使得分享文件的时候会有一大串的 Hash,并且一旦更新文件后,就会产生一个新的 Hash 值。
IPNS 全称是 The InterPlanetary Name System,IPNS 就是用了创建可以用于更新的地址。
IPNS 中的名字是一个公开密钥的 Hash,它会和一条记录相对应,这条记录被对应的私钥签名。新的记录可以被多次发布。
ipns 的地址会有一个前缀:
/ipns/yourname
拥有这样一个机制后就可以通过自己设定绑定到 IPFS Hash 的记录,然后通过该记录来访问。
使用如下命令会返回节点 ID
ipfs name publish QmQsLcmxzAh7Y6Ho1Nt8bispVmeHqjzdGBjG5m8KoGYjGi
使用 ipfs id 查看节点 ID。复制这一步的节点 ID,验证
ipfs name resolve your_ID
同样的 ID 可以使用 IPNS 来访问。
注意这里 URL 的 ipns 区别。
DNSLink
如果想要发布一个友好的地址,也可以使用 DNSLink
IPFS 允许用户直接使用现有的域名,这样就可以用一个简单的域名来访问。
只需要在 DNS 解析里面增加一条 TXT 记录,指向:
dnslink=/ipns/12D3KooWMrZpzzoSA2uxZiQ8NSizEK9A8SduhxcAc4yUB8imxXqU
Pin files
IPFS 节点默认情况下会将文件认为是缓存 (cache),这意味着 IPFS 不会一直保存着文件。Pinning 一个文件就是告诉 IPFS 节点将这个文件视为重要的文件,不要抛弃这个文件。
常见的 ipfs 命令
将本地文件添加到 IPFS
ipfs add filename
同理增加文件夹
ipfs add -r directory
获取一个远程的文件,并指定一个名字,但是不 pin 它:
ipfs get hash -o outputname
pin 一个远程的文件
ipfs pin add hash
显示本地 pin 过的文件
ipfs pin ls
从本地 unpin 一个文件
ipfs pin rm hash
移除本地 unpinned 的文件:
ipfs repo gc
IPFS 私人网络
使用密钥工具,创建密钥:
<https://github.com/Kubuxu/go-ipfs-swarm-key-gen>
然后将密钥放到 IPFS 默认配置下 ~/.ipfs/
然后启动 ipfs init,默认情况下连接的是公网节点,如果要连接私有网络,删除所有的启动节点,然后手动添加自己的节点:
ipfs bootstrap rm --all
ipfs bootstrap add node
查看节点:
ipfs swarm peers
在 IPFS 网络镜像本网站
最后借助 fleek 可以快速的将 GitHub 中托管的静态网站镜像一份到 IPFS 网络。
reference
- IPFS 文档
- https://blog.cloudflare.com/distributed-web-gateway/
- https://pinata.cloud/
- https://fleek.co/
gitconfig includeIf 管理多用户配置
~/.gitconfig 配置用来存储用户相关的配置,当 git 在提交或其他操作时,如果找不到项目目录下的 .git/config 文件时会回退到使用该全局配置文件。
大部分的配置可以通过 git config 来配置,比如常见的设置用户名和密码。
git config user.name "Ein Verne"
git config user.email "some@one.com"
通常情况下只需要维护一份全局的 ~/.gitconfig 然后在各自的项目中维护自己的 gitconfig 即可,但是我最近遇到一个问题便是,我迁移了几十个项目到另外一台机器中,这些项目我需要一个 ~/.gitconfig-work 的配置,用来区别和其他 git config 配置中使用的用户名和邮箱。
比如经常见到的 work 中有一个工作邮箱,自己在使用 GitHub 时有一个自己的邮箱,另外在其他开源项目中有一个独特的用户名和邮箱。这个时候就需要使用到 git 配置中的 includeIf 配置。
一份正常的 ~/.gitconfig 配置可能是这样的:
[user]
email = someone@gmail.com
name = Ein Verne
signingkey = 92
[push]
default = matching
[alias]
unstage = reset HEAD --
a = add
b = branch
[commit]
gpgsign = true
[gpg]
program = gpg
[includeIf "gitdir:~/play/"]
path = .gitconfig-play
[includeIf "gitdir:~/projects/"]
path = .gitconfig-wk
中间略有省略,不过大致的格式是这样。注意到最后的 includeIf 配置。
上面两行表示的意思就是对于 ~/play/ 下面的项目,使用 ~/.gitconfig-play 配置。
看一下 ~/.gitconfig-play 的配置。
[user]
email = some@play.com
name = Alex
然后对于 ~/projects/ 下面的项目,就使用 ~/.gitconfig-wk 配置。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。