Albert launcher
Albert 是一个 Linux 上的启动器,使用 C++ 和 QT 实现,实现了如下的功能:
- Run Applications
- Open files
- Open bookmarks
- Search web
- calculate things
- GPL-licensed
Install
Official Build
通过下面的网站下载官方编译的版本。
从源代码编译安装
从源码编译安装:
git clone --recursive https://github.com/albertlauncher/albert.git
mkdir albert-build
cd albert-build
cmake ../albert -DCMAKE_INSTALL_PREFIX=/usr -DCMAKE_BUILD_TYPE=Debug
make
sudo make install
顺利的话可以走到最后一步,不过大概率会出现各种依赖的问题。
➜ cmake ../albert -DCMAKE_INSTALL_PREFIX=/usr -DCMAKE_BUILD_TYPE=Debug
CMake Error at /opt/qt59/lib/cmake/Qt5/Qt5Config.cmake:28 (find_package):
Could not find a package configuration file provided by "Qt5X11Extras" with
any of the following names:
Qt5X11ExtrasConfig.cmake
qt5x11extras-config.cmake
Add the installation prefix of "Qt5X11Extras" to CMAKE_PREFIX_PATH or set
"Qt5X11Extras_DIR" to a directory containing one of the above files. If
"Qt5X11Extras" provides a separate development package or SDK, be sure it
has been installed.
Call Stack (most recent call first):
lib/globalshortcut/CMakeLists.txt:16 (find_package)
-- Configuring incomplete, errors occurred!
安装缺失的依赖:
➜ sudo apt install libqt5x11extras5 libqt5x11extras5-dev
➜ cmake ../albert -DCMAKE_INSTALL_PREFIX=/usr -DCMAKE_BUILD_TYPE=Debug
CMake Error at /usr/lib/x86_64-linux-gnu/cmake/Qt5/Qt5Config.cmake:28 (find_package):
Could not find a package configuration file provided by "Qt5Svg" with any
of the following names:
Qt5SvgConfig.cmake
qt5svg-config.cmake
Add the installation prefix of "Qt5Svg" to CMAKE_PREFIX_PATH or set
"Qt5Svg_DIR" to a directory containing one of the above files. If "Qt5Svg"
provides a separate development package or SDK, be sure it has been
installed.
Call Stack (most recent call first):
plugins/widgetboxmodel/CMakeLists.txt:7 (find_package)
-- Configuring incomplete, errors occurred!
安装缺失的依赖:
➜ sudo apt install libqt5svg5 libqt5svg5-dev
reference
Moshi : 新一代的 Java 解析 JSON 工具
最近 FastJson 安全问题频发,所以 JSON 解析又被拉到台面上,而正好不久前看 Reddit 看到 Gson 的作者在推荐一个叫 Moshi 的库,这就花点时间看一下。1
Gson 存在的问题
序列化 Date 的时候不包含时区的信息
Date epoch = new Date(0);
String epochJson = new Gson().toJson(epoch);
// "Dec 31, 1969 7:00:00 PM"
RFC 3339 标准 里面规定的日期表示法:
2020-06-12T07:20:50.52Z
其中 T 用来分割前面的日期和后面的时间,而最后的 Z 表示这个时间是 UTC+0,其他人看到这个时间就可以根据自己的时区进行转换。2
Gson 在序列化 HTML 标签时,会进行 HTML escaping 成:
private String e = "12 & 5";
private String f = "12 > 6"
"e":"12 \u0026 5"
"f":"12 \u003e 6"
Moshi 优势
- Moshi 库特别小,对于 Android 来说自然可以减小 APK 大小
- Moshi 自带的 Adapter 可以满足大部分的需求,如果需要扩充也非常方便
- 可以使用
@Json来自定义 Field 名 - Kotlin Support
- 使用类似于
@HexColor int的限定符可以让多个 JSON 映射到同一个 Java Type
Moshi 潜在的问题和 Gson 的差别
- Moshi 只有少量的内置 Adapter,Moshi 不会去序列化平台相关的类型,比如
java.*,javax.*,android.*等等,以防止被 Lock 在某一个特殊 JDK 或者 Android 版本 - Moshi 只有少量的配置选项,没有 field naming strapegy, versioning, instance creator, long serialization policy.
- Moshi 没有
JsonElement模型 - No HTML-safe escaping
使用
更加具体的使用方法可以参考源代码中的实现。
最基本的使用,序列化一个 Java Object 到 JSON,或者将 JSON 映射到 Java Object 里面。
将 JSON 字符串解析成 Java 对象
Moshi moshi = new Moshi.Builder().build();
JsonAdapter<BlackjackHand> jsonAdapter = moshi.adapter(BlackjackHand.class);
BlackjackHand blackjackHand = jsonAdapter.fromJson(json);
System.out.println(blackjackHand);
如果是 JsonArray:
Moshi moshi = new Moshi.Builder().build();
Type listOfCardsType = Types.newParameterizedType(List.class, Card.class);
JsonAdapter<List<Card>> jsonAdapter = moshi.adapter(listOfCardsType);
List<Card> cards = jsonAdapter.fromJson(json);
序列化 Java Object:
Moshi moshi = new Moshi.Builder().build();
JsonAdapter<BlackjackHand> jsonAdapter = moshi.adapter(BlackjackHand.class);
String json = jsonAdapter.toJson(blackjackHand);
System.out.println(json);
自定义 Field
比如有一个 JSON 字符串:
String json = ""
+ "{"
+ " \"username\": \"jesse\","
+ " \"lucky number\": 32"
+ "}\n";
其中的 lucky number 是带空格的,假如要解析到 Java Object
public final class Player {
public final String username;
public final @Json(name = "lucky number") int luckyNumber;
}
可以看到使用 @Json 注解即可。
源码解析
Moshi
Moshi 只能使用 Builder 模式创建,看其源码会发现,构造函数并不是 public 的。唯一一个带参数的
Moshi(Builder builder) {
List<JsonAdapter.Factory> factories = new ArrayList<>(
builder.factories.size() + BUILT_IN_FACTORIES.size());
factories.addAll(builder.factories);
factories.addAll(BUILT_IN_FACTORIES);
this.factories = Collections.unmodifiableList(factories);
}
可以看到 Moshi 有一系列 adapter() 公开方法,通过 adapter() 方法可以返回一个 JsonAdapter<> 对象,之后的操作都在该 adapter 之上进行。
成员变量
private final List<JsonAdapter.Factory> factories;
private final ThreadLocal<LookupChain> lookupChainThreadLocal = new ThreadLocal<>();
private final Map<Object, JsonAdapter<?>> adapterCache = new LinkedHashMap<>();
说明:
factories: 是 JsonAdapter.Factory 数组,工厂模式产生 JsonAdapter- lookupChainThreadLocal 是一个 ThreadLocal 内部存放了
LookupChain adapterCache是一个LinkedHashMap用来保存 Object 到 JsonAdapter 的映射关系
Moshi 类中初始化的时候有 5 个内置的 Adapter Factory.
static final List<JsonAdapter.Factory> BUILT_IN_FACTORIES = new ArrayList<>(5);
static {
BUILT_IN_FACTORIES.add(StandardJsonAdapters.FACTORY);
BUILT_IN_FACTORIES.add(CollectionJsonAdapter.FACTORY);
BUILT_IN_FACTORIES.add(MapJsonAdapter.FACTORY);
BUILT_IN_FACTORIES.add(ArrayJsonAdapter.FACTORY);
BUILT_IN_FACTORIES.add(ClassJsonAdapter.FACTORY);
}
- StandardJsonAdapters.FACTORY 包含了基本类型,包装类型,还有运行时才能决定的 ObjectJsonAdapter
- CollectionJsonAdapter.FACTORY 包含 List, Collection, Set 类型
- MapJsonAdapter.FACTORY 包含将 Map(Key 是 String) 的 JSON 转换成 Object 的 Adapter
- ArrayJsonAdapter.FACTORY 处理包含了原始值或 Object 的 JSON Array
- ClassJsonAdapter.FACTORY
Moshi.Builder
Moshi.Builder 是 Moshi 内部的一个类,用来创建 Moshi,它有一系列方法:
com.squareup.moshi.Moshi.Builder#add(java.lang.reflect.Type, com.squareup.moshi.JsonAdapter<T>)
com.squareup.moshi.Moshi.Builder#add(java.lang.reflect.Type, java.lang.Class<? extends java.lang.annotation.Annotation>, com.squareup.moshi.JsonAdapter<T>)
com.squareup.moshi.Moshi.Builder#add(com.squareup.moshi.JsonAdapter.Factory)
com.squareup.moshi.Moshi.Builder#add(java.lang.Object)
com.squareup.moshi.Moshi.Builder#addAll
com.squareup.moshi.Moshi.Builder#build
可以看到除了 overload 重载的 add() 方法外,就是 build 方法,而 add() 方法可以添加一系列类型。
JsonAdapter 抽象类
JsonAdapter 的公开方法:
com.squareup.moshi.JsonAdapter#fromJson(com.squareup.moshi.JsonReader)
com.squareup.moshi.JsonAdapter#fromJson(okio.BufferedSource)
com.squareup.moshi.JsonAdapter#fromJson(java.lang.String)
com.squareup.moshi.JsonAdapter#toJson(com.squareup.moshi.JsonWriter, T)
com.squareup.moshi.JsonAdapter#toJson(okio.BufferedSink, T)
com.squareup.moshi.JsonAdapter#toJson(T)
com.squareup.moshi.JsonAdapter#toJsonValue
com.squareup.moshi.JsonAdapter#fromJsonValue
com.squareup.moshi.JsonAdapter#serializeNulls
com.squareup.moshi.JsonAdapter#nullSafe
com.squareup.moshi.JsonAdapter#nonNull
com.squareup.moshi.JsonAdapter#lenient
com.squareup.moshi.JsonAdapter#failOnUnknown
com.squareup.moshi.JsonAdapter#indent
JsonAdapter 有两个抽象方法需要实现 fromJson 和 toJson。
大致就能看出 JsonAdapter 的主要功能:
- 一方面提供
fromJsontotoJson的转换 -
另一方面提供转换过程中的一些选项
serializeNullsserializes nulls when encoding JSONnullSafesupport for reading and writing- 比如
nonNull调用时会返回一个不允许 null 值的 JsonAdapter lenient宽容处理 JSONfailOnUnknown在遇到未知的 name 或 value 时抛出JsonDataException异常indent输出的 JSON 是格式化好的
JsonAdapter 主要去处理各个类型的转换,需要实现如下三个方法:
static final JsonAdapter<Boolean> BOOLEAN_JSON_ADAPTER = new JsonAdapter<Boolean>() {
@Override public Boolean fromJson(JsonReader reader) throws IOException {
return reader.nextBoolean();
}
@Override public void toJson(JsonWriter writer, Boolean value) throws IOException {
writer.value(value.booleanValue());
}
@Override public String toString() {
return "JsonAdapter(Boolean)";
}
};
JsonAdapter.Factory 接口
这个接口定义在抽象类 JsonAdapter 中,Factory 只需要实现一个方法:
public interface Factory {
@CheckReturnValue
@Nullable JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi);
}
Factory 看名字也能猜到这是一个工厂方法,用来创造给定 Type 给定 Annotation 类型的 Adapter,如果无法创建则返回 null.
在 Factory 的实现中,可能会使用 moshi.adapter 来构建 Adapter.
Mosh.Builder
再看 Moshi.Builder 类成员
final List<JsonAdapter.Factory> factories = new ArrayList<>();
在源代码的基础上加了一些注释
reference
KIE API 学习笔记
Kie have these concepts which every user need to know.
KieService
通过如下方式产生 KieServices:
KieServices ks = KieServices.Factory.get();
KieService 可以用来创建 KieContainer。
KieContainer 定义了规则的范围。
KieContainer
KieContainer 是所有给定 KieModule 的 KieBases 的集合。
KieContainer 承载了 KieModule 和其依赖,一个层级的 KieModules 结构可以被加载到一个 KieContainer 实例中。
KieContainer 可以拥有一个或者多个 KieBases.
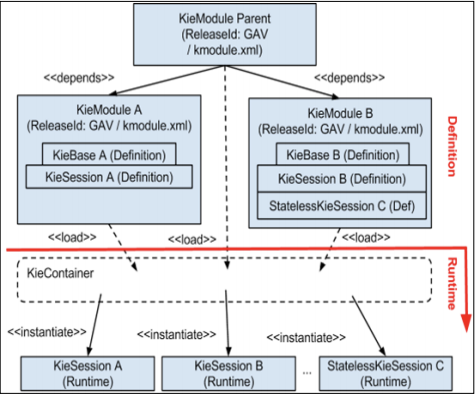
KieContainer 可以通过 KieService 产生:
KieContainer kContainer = ks.newKieClasspathContainer();
KieModule
每一个 KieModule 包含了 business assets(包括了流程,规则,决策表等等)。
一个 KieModule 是一个标准的 Java-Maven 项目。
KieModule 在 org.kie.api.builder 包下,KieModule 是一个存放所有定义好的 KieBases 资源的容器,和 pom.xml 文件相似,定义了其 ReleaseId, kmodule.xml 文件定义了 KieBase 的名字,配置,以及其他用来创建 KieSession 的资源,以及其他用来 build KIEBases 的资源。
指定的文件 kmodule.xml 定义在 META-TNF/ 目录下,一定了内部的资源如何分组如何配置等等信息。
KieModule 用来定义多个 KieBases 和 KieSessions。KieModule 可以包含其他 KieModules.
KieBase
KieBase 是应用所有定义好的 Knowledge 合集,包括了 rules(规则), processes(流程), functions(方法), type models, KieBase 自身不包含任何运行时数据,sessions 可以从 KieBase 中创建,然后运行时数据可以被装入,并且通过 sessions 可以启动一个流程。
KieBase 代表着编译好的资源的版本,可以有 Stateless 和 Stateful Session,一个典型的使用场景是为一个 packages 使用一个 KieBase ,另一个 package 使用另一个 KieBase.
KieSession
KieSession 是和工作流引擎交互的最常用的方式,KieSession 允许应用建立和引擎的交互,session 的状态会在每一次调用的时候保存下来。而流程会在一组相同的变量上触发多次。当应用完成调用,必须调用 dispose() 来释放资源以及使用的内存。
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession();
for( Object fact : facts ) {
kSession.insert( fact );
}
kSession.fireAllRules();
kSession.dispose();
每一个 KieBase 都可以有一个或者多个 KieSessions.
KieSession 是否是线程安全的
KieContainer 是线程安全的。
KieContainer.newStatelessKieSession() 和
KieContainer.newKieSession() 方法是线程不安全的。
有状态 Session 和无状态 Session 区别
Drools 的 Session 分为有状态和无状态。
stateful KieSession 可以在多次和 Rule Engine 交互的过程中保持状态。 而无状态的 KieSession 只允许我们交互一次,并直接获取结果。
StatefulKnowledgeSession
- 与[[规则引擎]]持久交互
- 推理过程多次触发同一个数据集
- 使用完后,要调用 dispose() 方法
- 有状态会话可以随时添加 Fact
Stateful 可以通过 insert 方法插入 Fact,并取得 FactHandle,通过这个 Handle 可以多次更新 Fact 从而触发规则
FactHandle handle = statefulKieSession.insert(factObject);
factObject.setBalance(100.0);
statefulKieSession.update(handle,factObject);
StatelessKnowledgeSession
- 对 StatefulKnowledgeSession 做了包装
- 不能重复插入 Fact
- 执行规则使用 execute() 方法
- insert, fireAllRules 和 dispose 方法
Stateless 类似一次函数调用,通过 execute 方法传入 Fact,匹配规则
session.execute(Arrays.asList(new Object[]{routeResult,featureManager.getFreeFeatures(),accessManager,this}));
// 又或者,执行完获得结果:
List<Command> cmds = new ArrayList<>();
cmds.add(CommandFactory.newInsert(routeResult,"routeResult")); cmds.add(CommandFactory.newInsert(featureManager.getFreeFeatures(),"freeFeature"));
cmds.add(CommandFactory.newInsert(accessManager,"accessManager"));
cmds.add(CommandFactory.newInsert(this,"router"));
ExecutionResults results = statelessKieSession.execute( CommandFactory.newBatchExecution( cmds ) );
KieBuilder
KieBuilder is a builder for the resources contained in a KieModule
KieServices ks = KieServices.Factory.get();
KieRepository kr = ks.getRepository();
InputStream is = new ByteArrayInputStream(bytes);
KieModule kModule = kr.addKieModule(ks.getResources().newInputStreamResource(is));
KieContainer kContainer = ks.newKieContainer(kModule.getReleaseId());
KieResources
KieResources 可以从很多来源构造,字节流 (InputStream),文件系统 (File),ClassPath 等等。
KieModuleModel
KieRepository
KieContainerImpl
KieBase
KieSession
真正用来启动 Process 的类
ksession.startProcess()
reference
JBoss 工作流相关 Docker 镜像整理
源代码地址:
三个可用的镜像:
- business-central-workbench
JBoss Business-Central Workbench 基础镜像,可以根据该镜像来扩展创建自己的镜像。
- business-central-workbench-showcase
继承自 JBoss Business-Central Workbench 镜像,可以直接使用的 Docker 镜像。提供了自定义的配置文件,默认的用户和角色。
- jBPM Server Full distribution
提供了可以立即执行的全部 jBPM 功能的镜像,包含全部必须的配置文件。包括 jBPM Workbench, Kie Server and jBPM Case Management Showcase。可以访问 新手教程 来查看。
Java 查漏补缺:函数式接口
Functional interface is a new feature Java 8 introduced. Functional interfaces provides target types for lambda expressions and method references.
// Assignment context
Predicate<String> p = String::isEmpty;
// Method invocation context
stream.filter(e -> e.getSize() > 10)...
// Cast context
stream.map((ToIntFunction) e -> e.getSize())...
特性
- 函数式接口都是表达一种行为
- @FunctionalInterface 保证了函数式接口只有一个抽象方法,但是注解的使用是不必须的
java.util.function
相关的新的函数式接口定义在 java.util.function 包下 1:
- Consumer,一个参数,无返回,
void accept(T t) - Function,一个参数,一个结果,
R apply(T t) - Supplier,无参数,返回一个结果,
T get() - Predicate 接收一个参数,返回一个 boolean,
boolean test(T t) - BinaryOperator,接收两个相同类型参数,返回一个相同类型
实例
class Test
{
public static void main(String args[])
{
// create anonymous inner class object
new Thread(new Runnable()
{
@Override
public void run()
{
System.out.println("New thread created");
}
}).start();
}
}
使用函数式接口后
class Test
{
public static void main(String args[])
{
// lambda expression to create the object
new Thread(()->
{System.out.println("New thread created");}).start();
}
}
定义和使用
@FunctionalInterface
interface Square
{
int calculate(int x);
}
class Test
{
public static void main(String args[])
{
int a = 5;
// lambda expression to define the calculate method
Square s = (int x)->x*x;
// parameter passed and return type must be
// same as defined in the prototype
int ans = s.calculate(a);
System.out.println(ans);
}
}
reference
在 OpenMediaVault 上使用 SnapRAID 和 MergerFS
首先来介绍一下这两个软件,SnapRAID 和 MergerFS,不同于其他现有的 NAS 系统,可以把 OpenMediaVault 看成一个简单的带有 Web UI 的 Linux 系统,他使用最基本的文件系统,没有 ZFS 的实时文件冗余,所以需要 SnapRAID 提供的冗余来保护硬盘数据安全。SnapRAID 需要一块单独的硬盘来存放校验数据,这个盘的容量必须大于等于其他任何一个数据盘。SnapRAID 采用快照的方式来做数据冗余,这种设计避免了所有硬盘在没有数据操作情况下也要运转来实时数据备份的消耗。
MergerFS 则是一个联合文件系统,可以将多块硬盘挂载到一个挂载点,通过 MergerFS 来自动决定数据该存储在哪块硬盘上。
Prerequisite
先决条件:
- 至少三块硬盘,两块硬盘用来演示 MergerFS 合并,一块硬盘用来作为 SnapRAID 冗余备份
- 一个安装好的 OpenMediaVault 以及安装好 OMV-Extras 相关的插件
- System - Plugin 下安装
openmediavault-snapraid和openmediavault-unionfilesystem插件
MergerFS
MergerFS 是一个联合文件系统 (union file system),MergerFS 会将多块硬盘,或者多个文件夹合并到 MergerFS pool 中,这样一个系统就会有一个统一的文件入口,方便管理。
选用 MergerFS 另外一个理由就是,通过 MergerFS 合并的目录并不会对数据进行条带化的处理,每块硬盘上还是保存原来的文件目录和文件,任意一块硬盘单独拿出来放到其他系统上,不需要额外的逻辑卷的配置,就可以直接挂载读取这个硬盘的数据。
创建 MergerFS pool
通过如下步骤创建 MergerFS 磁盘池:
- Storage > Union Filesystems
- Add
- Give the pool a name
- In the Branches 选项中,选择所有要合并的磁盘,这里不要选 parity 的磁盘
- 在 Create policy 中选择 Most free space
- Minimum free space 中选择一个合适的大小,默认也可以
- Option 中,默认
- Save
- Apply
这样以后在文件系统中就会看到新创建的联合目录。在创建共享文件夹的时候就可以在合并的联合文件系统上进行。
在创建了 MergerFS Pool 后,在 OpenMediaVault 的文件目录 /srv 目录下会多出一个文件夹,这个文件夹就会存放 MergerFS Pool 中的数据。
SnapRAID
SnapRAID 是一个磁盘阵列的冗余备份工具,它可以存储额外的奇偶校验信息用来校验数据,以便在磁盘发生故障时恢复数据。
SnapRAID 适用于家庭媒体服务器,适合于存储多数不经常变动的大文件场景。
特性:
- 所有的数据都经过哈希处理,以确保数据完整性来避免可能的磁盘损坏
- 如果故障磁盘太多而无法恢复,则只会丢失故障磁盘上的数据。其他磁盘中的所有数据都是安全的
- 如果意外的删除了某些文件,可以轻松的恢复
- 可以在已经有数据的硬盘上使用
- 硬盘可以有不同的大小
- 可以在任何时候添加磁盘
- 不会占用数据,可以在任何时候停用 SnapRAID 而不用重新格式化
- 访问数据时,只有一块磁盘会转动,节省电源以及减少噪声
SnapRAID 作为一个备份工具非常强大,强烈推荐阅读官网上关于 SnapRAID 和 [[unRAID]], ZFS 等系统或文件系统提供的备份的对比 1
在 OpenMediaVault 中使用 SnapRAID :
设置需要保护的磁盘
假设三块硬盘中前两块用来存储重要的数据,第三块用来存放奇偶校验信息。那么首先设置数据盘:
- 在 Services > SnapRAID 菜单,click Drives 选项
- 点击 Add
- 选择第一块硬盘
- 起一个友好的名字
- 选择 Content
- 选择 Data
- 不需要选 Parity
- 保存
重复上面的步骤将第二块磁盘也添加进来。
设置奇偶校验盘
添加奇偶校验信息盘的时候,和上面步骤相似。不过要注意的是在添加磁盘时
- 不需要选择 Content
- 不需要选择 Data
- 选择 Parity
然后点击保存。
SnapRAID 操作
在添加完硬盘之后,可以进行同步操作:
- Sync, 同步数据,并更新校验,默认进行差量同步
- Scrub,检查潜在的错误
- Diff,列出和上一次存在的差别
- Fix,尽可能恢复到上一次同步状态
- Fix silent,修复潜在的错误
SnapRAID Scrub
最后设置 SnapRAID Scrub,scrubbing 的目的是检查数据盘和校验信息盘的错误。可以在 SnapRAID 的 settings 界面中启用 Scheduled diff,启用后会自动创建一个周期性 Crontab 任务。
SnapRAID Rules
对于一些不需要 SnapRAID 进行冗余校验的目录,可以在 Rules 选项中进行排除。比如说经常变动的 metadata 信息,Docker 容器配置,虚拟机等等。
SnapRAID Scheduled Jobs
周期性的执行这些命令。
sync 命令会更新 parity 信息,所有磁盘中修改的文件都会被读取,然后对应的 parity 信息都会更新。
touch 命令会将所有拥有 sub-second 时间戳的文件设置为 0,这样提高了 SnapRAID 识别移动和复制过的文件的能力,可以消除可能的重复。
scrub 命令会验证磁盘阵列中的数据和 sync 命令产生的 hash.
# Run this command for the first time
snapraid sync
# Run this command after the sync is completed
snapraid scrub
# Run this command for status
snapraid status
mergerfsfolders vs unionfilesystems
在安装完 OMV-Extras 后会在插件中看到两个相似的插件:
- mergerfsfolders, 利用 mergerfs 将多个文件夹挂载到同一个挂载点
- unionfilesystems,使用 union filesystem mergerfs 来将多块硬盘挂载到一个挂载点
其主要区别就在于一个是合并文件夹,一个是合并硬盘。所以如果对于全新的硬盘,没有任何数据,可以直接利用 unionfilesystems 来将多块硬盘组合成一个 pool.
reference
Linux 设备中的 major 和 minor 数字
Today, when I visit tldr issue and I saw a talk about the command lsblk, although I used a lot before, I really don’t understand the MAJ:MIN in the result. Most time, I use it to check the harddrive disk and partitions.
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 260.7M 1 loop /snap/kde-frameworks-5-core18/32
loop1 7:1 0 253.5M 1 loop /snap/electronic-wechat/7
loop2 7:2 0 69M 1 loop /snap/telegram-desktop/1634
loop3 7:3 0 21.3M 1 loop /snap/communitheme/1987
loop4 7:4 0 55M 1 loop /snap/core18/1754
loop5 7:5 0 93.9M 1 loop /snap/core/9066
loop6 7:6 0 54.8M 1 loop /snap/gtk-common-themes/1502
loop7 7:7 0 93.8M 1 loop /snap/core/8935
loop8 7:8 0 373.5M 1 loop /snap/anbox/158
loop10 7:10 0 397.1M 1 loop /snap/redis-desktop-manager/335
loop11 7:11 0 160.2M 1 loop /snap/gnome-3-28-1804/116
loop12 7:12 0 32M 1 loop /snap/git-fame/15
loop13 7:13 0 149.2M 1 loop /snap/postman/109
loop14 7:14 0 16M 1 loop /snap/communitheme/1768
loop15 7:15 0 55M 1 loop /snap/core18/1705
loop16 7:16 0 374.9M 1 loop /snap/redis-desktop-manager/400
loop17 7:17 0 69M 1 loop /snap/telegram-desktop/1627
loop18 7:18 0 62.1M 1 loop /snap/gtk-common-themes/1506
loop19 7:19 0 32.1M 1 loop /snap/git-fame/23
loop20 7:20 0 310.8M 1 loop
loop21 7:21 0 163.6M 1 loop /snap/postman/110
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 214.9G 0 part
├─sda2 8:2 0 16.3G 0 part [SWAP]
└─sda3 8:3 0 700.4G 0 part /media/Backup
sdb 8:16 0 232.9G 0 disk
├─sdb1 8:17 0 232.9G 0 part /
└─sdb2 8:18 0 2M 0 part
However, when I take a close look at the output, I can see only the disk device output, but also see the snap package output. So I started to search informations about the MAJ:MIN.
Major and minor device number
We all know that under linux, all devices are managed under /dev folder. So lets check the special device first:
ls -al /dev/zero
crw-rw-rw- 1 root root 1, 5 May 29 19:40 /dev/zero
We can see that, ls output is a little bit different from normal output, /dev/zero device’s major number is 1 and minor is 5
Then let’s check /proc/devices:
cat /proc/devices
This file contains the list of device drivers configured into the current running kernal(block and character).1
We can see that under /proc/devices file, there are a list of number and strings. For example:
Character devices:
1 mem
5 /dev/tty
5 /dev/console
7 vcs
Block devices:
8 sd
Each device node’s type (block or character) and numbers serve as identifiers for the kernel.
On Linux, the canonical list of devices, with a brief explanation of their function, is maintained in the kernel.
- major number: identify the driver associated with the device. For example
/dev/nulland/dev/zeroare both managerd by driver 1, whereas virtual consoles and serial terminals are managed by driver 4. Kernal uses the major number at open time to dispatch execution to the appropriate driver. - minor number: refers to an instance, which is used by the driver itself, specified by the major number. Minor number is used for driver to identify the difference between devices.
After version 2.4, the kernel introduced a new feature, the device file system or devfs. But for now most distributions do not add these feature. Read more from here.
When devfs is not being used, adding a new driver to the system means assigning a major number to it. The assignment should be made at driver (module) initialization by calling the following function, defined in <linux.fs.h>:
int register_chrdev(unsigned int major, const char* name, struct file_operations* fops);
Once the driver has been registered in the kernel table, its operations are associated with the given major number.
And a name must be inserted into the /dev directory and associated with your driver’s major and minor numbers.
The command to create a device node on the filesystem is called mknod:
mknod /dev/scull0 c 254 0
Explain:
cmeans: create a char device- with major nubmer 254
- and minor number 0, minor number should be in the range 0 to 255
reference
- 《Linux Device Drivers, Second Edition by Jonathan Corbet, Alessandro Rubini》
利用 AdGuard Home 自建 DNS 服务器过滤广告
AdGuard Home 是 AdGuard 发布的一款借助于 DNS 来实现广告过滤的服务。
过滤广告的方式有非常多的方式,比如加本地 Host,比如浏览器中的 Adblock 插件,或者之前在 OpenWrt 或者其他固件上添加的广告过滤插件,甚至在 Android 上也用过通过在本地设定一个代理,所有的流量走代理,然后在代理中将广告过滤掉的应用,那么这个 AdGuard Home 有什么优势呢?在我看来,吸引我使用它的几个优势是:
- 只需要架设一次,所有局域网中的设备都可以享用,而不需要各个设备单独配置
- 可视化,最早是在 Twitter 上看到有人分享 AdGuard 后台,大部分情况下,广告过滤插件或者应用都是默默在后台工作,AdGuard 让一切变得可见,那这样就可以分析哪些网站在后面偷偷地做坏事
- 占用资源小,一个树莓派即可,并且源代码是开放的
- 支持安全的 DNS 解析
AdGuard 官方的文章也总结了 AdGuard Home 的几大优势:1
- Ad Blocking, 最基础的服务,可以减少网页的体积,加快速度
- Browsing Security
- Parent Control
- Safe Search,可以过滤成人内容
- Custom upstream servers, 可以自定义上游的 DNS 服务器
- Filter lists, 可以自定义过滤列表
- Query Log,也就是我提到的可视化的访问日志
AdGuard vs AdGuard Home
开始之前要先声明一下,这篇文章后面提到的 AdGuard Home 都会是 AdGuard 这个公司提供的一个产品 —- AdGuard Home.1
AdGuard Home 的原理
上面提到过很多不同的广告过滤方式,但是 AdGuard Home 采用完全不同的方式。首先来介绍一下什么是 AdGuard Home,AdGuard Home 是一个过滤全网范围的广告和追踪代码的 DNS Server,它的设计目的是让用户来全权掌握整个网络环境,它不依赖于任何客户端。所以从本质上来讲 AdGuard Home 是一个 DNS 服务器,通过屏蔽掉黑名单的域名来达到过滤广告的目的。
在 Raspberry Pi 中安装使用 AdGuard Home
在树莓派上安装 AdGuard Home 非常简单,安装 wiki 上执行即可。
给 Raspberry Pi 设定静态 IP 地址
Raspberry Pi 的网络配置 /etc/dhcpcd.conf,在下方添加
interface eth0
static ip_address=192.168.2.3/24
static routers=192.168.2.1
static domain_name_servers=192.168.2.1
注意我这里是使用的 eth0 接口,也就是网线连接的,如果使用 WiFi,那么需要设定 wlan0。
然后 sudo reboot 重启树莓派。
之后我的树莓派静态 IP 地址就是 192.168.2.3
验证安装
上面提到过保证树莓派静态地址,然后执行安装向导,设定后台管理页面的端口(一般为 80,可以自行修改),以及 DNS 服务端口(一般为 53)。这样 53 端口就对外提供了 DNS 服务,可以通过
nslookup douban.com 192.168.2.3
来验证 DNS 服务器正常工作,如果正常工作返回
Server: 192.168.2.3
Address: 192.168.2.3#53
Non-authoritative answer:
Name: douban.com
Address: 154.8.131.171
Name: douban.com
Address: 154.8.131.172
Name: douban.com
Address: 154.8.131.165
验证拦截
nslookup doubleclick.net 192.168.2.3
Server: 192.168.2.3
Address: 192.168.2.3#53
** server can't find doubleclick.net: NXDOMAIN
设置路由器和其他设备
如果能够设置路由器,直接去路由器管理后台,将网络的 DNS,改为树莓派的地址,比如我的 192.168.2.3 即可。其他设备直接就生效了。如果改不了路由器就只能每一个设备改了。
其他管理命令
AdGuardHome 安装的命令:
sudo ./AdGuardHome -s install
其他管理命令:
- AdGuardHome -s uninstall - uninstalls the AdGuard Home service.
- AdGuardHome -s start - starts the service.
- AdGuardHome -s stop - stops the service.
- AdGuardHome -s restart - restarts the service.
- AdGuardHome -s status - shows the current service status.
Docker 安装
因为 AdGuardHome 是使用 Go 所写,所以跨平台天然支持,Docker 安装自然也非常容易。
docker pull adguard/adguardhome
docker run --name adguardhome \
-v ~/adguardhome/workdir:/opt/adguardhome/work \
-v ~/adguardhome/confdir:/opt/adguardhome/conf \
-p 53:53/tcp -p 53:53/udp \
-p 67:67/udp -p 68:68/tcp -p 68:68/udp \
-p 8080:80/tcp -p 443:443/tcp \
-p 853:853/tcp -p 3000:3000/tcp \
--restart=always -d adguard/adguardhome
说明:
-p 67:67/udp -p 68:68/tcp -p 68:68/udp用来将 AdGuard Home 作为 DHCP 服务,可不映射-p 443:443/tcp如果要使用 AdGuard Home 作为 HTTPS/DNS-over-HTTPS 服务器-p 853:853/tcp作为 DNS-over-TLS 服务器-p 784:784/udp作为 DNS-over-QUIC 服务器-p 5443:5443/tcp -p 5443:5443/udp作为 DNSCrypt 服务器
参数可以参数官方网站:
设置
所有安装完成之后就可以进入后台进行一番初始化设置,AdGuardHome 默认的设置就已经足够使用了,但假如想更加精细化地设置,比如说上游 DNS,DNS-over-HTTPS,DNS-over-TLS 等等,都可以在后台看到。
AdGuard Home 所有的配置参数都保存在一个名为 AdGuardHome.yaml 的配置文件中。这个配置文件默认路径通常为 AdGuard Home 二进制文件 AdGuardHome 所在的目录。
已知的 DNS 提供商
AdGuard 提供了一份非常详细的 DNS 服务提供商的列表:
进入后台可以看到 AdGuard 默认使用的是
https://dns10.quad9.net/dns-query
不过在国内可能在测试上游 DNS 服务器的时候
服务器 “https://dns10.quad9.net/dns-query”:无法使用,请检查你输入的是否正确
不过问题也不大,勾选“并行请求”,同时用下方的 DNS 提供商的
tls://8.8.8.8
tls://8.8.4.4
tls://dns.google
tls://dns.adguard.com
119.29.29.29
1.2.4.8
tls://1.1.1.1
tls://1.0.0.1
https://dns10.quad9.net/dns-query
8.8.8.8
114.114.114.114
119.29.29.29
223.5.5.5
其他一些
不过这些国内公共 DNS 暂时不支持 DNS over TLS。
Bootstrap DNS 服务器
1.1.1.1:53
1.0.0.1:53
9.9.9.10
149.112.112.10
114.114.114.114:53
2620:fe::10
2620:fe::fe:10
过滤器
AdGuard Home 自身已经内置了一些过滤规则,并且 AdGuard Home 兼容 Adblock 的过滤规则。
- EasyList China 国内网站广告过滤的主规则
https://easylist-downloads.adblockplus.org/easylistchina.txt - Anti Ad 国内过滤规则
https://gitee.com/privacy-protection-tools/anti-ad/raw/master/easylist.txt - neohosts
https://cdn.jsdelivr.net/gh/neoFelhz/neohosts@gh-pages/basic/hosts.txt - EasyPrivacy
https://easylist-downloads.adblockplus.org/easyprivacy.txt - AdGuard Simplified Domain Names filt https://adguardteam.github.io/AdGuardSDNSFilter/Filters/filter.txt
- AdAway https://adaway.org/hosts.txt
- CJX’s Annoyance List https://raw.githubusercontent.com/cjx82630/cjxlist/master/cjx-annoyance.txt
外延
.in-addr.arpa
在运行 AdGuard Home 一天后,观察请求域名排行榜,有一些奇怪的域名请求频率异常高,显示着一个 IP 地址,后面接着 .in-addr.arpa. 这就引起了我的好奇,查询之后发现这一类的地址叫做 Reverse DNS lookup,反向 DNS 查询。都知道 DNS 是将域名转换成 IP 地址,那么反过来查询 IP 地址关联的域名就是反向 DNS 查询。
如果想要反解析一个给定的 IP 地址,需要反转 IP 地址,然后在后面添加一个特殊的域名,比如 in-addr.arpa,比如想要反解析 8.8.4.4 对应的域名,需要构造这样的地址:
4.4.8.8.in-addr.arpa
然后可以使用 dig -x 4.4.8.8.in-addr.arpa @8.8.8.8 来进行反向解析查看结果。
SERVFAIL
观察查询日志,在我的内网里面能看到不少的 SERVFAIL,这里就顺带复习一下 DNS RCODE2,DNS 请求的返回码:
- NOERROR(0),成功响应,解析成功
- SERVFAIL(2), 服务器失败,域名的权威服务器拒绝响应或者响应 REFUSE,递归服务器返回 Rcode 值为 2 给 CLIENT
- NXDOMAIN(3), 不存在的记录,域名在权威服务器不存在
- REFUSE(5),请求的 IP 不在该 DNS 服务器服务的范围
其他更多的码可以参考这里.
AdGuard Home 相较于 Pi-Hole 的优势
AdGuard Home 和 Pi-Hole 利用相似的原理可以达到基本一致的效果,但是 AdGuard Home 相较于 Pi-Hole 有如下几方面的优势:
- AdGuard Home 支持加密的 DNS 上游服务器 Encrypted DNS upstream servers (DNS-over-HTTPS, DNS-over-TLS, DNSCrypt)
- 更加完整的过滤系统,和家长控制
- 安全搜索结果
- 访问控制,可以实现精确的谁能访问 DNS 服务器
Configuration
AdGuard Home 的配置文件是 yaml 格式,格式非常易读。
DNS TTL
在设置里面有一个 DNS TTL 的设置,这里 TTL 是 Time to Live 缩写,指的是 DNS 需要缓存多久然后才去刷新新的解析结果。
当改变 DNS 配置的时候,需要花费一些时间来通知互联网这个修改,比如修改一个域名对应的 IP 地址,修改 MX 记录等等,TTL 配置就是告诉互联网需要缓存这一次的结果多久才需要再来请求信息。
那么在家用环境里面可以根据自己的情况设置一个合理的值,我个人觉得大部分网站设置一个 10 分钟的缓存就可以了。
bind_host: 0.0.0.0
bind_port: 80
users:
- name: admin
password: b2a
http_proxy: ""
language: ""
rlimit_nofile: 0
debug_pprof: false
web_session_ttl: 720
dns:
bind_host: 0.0.0.0
port: 53
statistics_interval: 1
querylog_enabled: true
querylog_interval: 90
querylog_size_memory: 1000
anonymize_client_ip: false
protection_enabled: true
blocking_mode: default
blocking_ipv4: ""
blocking_ipv6: ""
blocked_response_ttl: 10
parental_block_host: family-block.dns.adguard.com
safebrowsing_block_host: standard-block.dns.adguard.com
ratelimit: 100
ratelimit_whitelist: []
refuse_any: true
upstream_dns:
- tls://8.8.8.8
- tls://8.8.4.4
- 119.29.29.29
- 1.2.4.8
- 114.114.114.114
- 223.5.5.5
bootstrap_dns:
- 9.9.9.10
- 149.112.112.10
- 2620:fe::10
- 2620:fe::fe:10
all_servers: true
fastest_addr: false
allowed_clients: []
disallowed_clients: []
blocked_hosts: []
cache_size: 4194304
cache_ttl_min: 600
cache_ttl_max: 0
bogus_nxdomain: []
aaaa_disabled: false
enable_dnssec: false
edns_client_subnet: false
filtering_enabled: true
filters_update_interval: 24
parental_enabled: false
safesearch_enabled: false
safebrowsing_enabled: false
safebrowsing_cache_size: 1048576
safesearch_cache_size: 1048576
parental_cache_size: 1048576
cache_time: 30
rewrites: []
blocked_services: []
tls:
enabled: false
server_name: ""
force_https: false
port_https: 443
port_dns_over_tls: 853
allow_unencrypted_doh: false
strict_sni_check: false
certificate_chain: ""
private_key: ""
certificate_path: ""
private_key_path: ""
filters:
- enabled: true
url: https://adguardteam.github.io/AdGuardSDNSFilter/Filters/filter.txt
name: AdGuard DNS filter
id: 1
- enabled: true
url: https://adaway.org/hosts.txt
name: AdAway
id: 2
- enabled: false
url: https://www.malwaredomainlist.com/hostslist/hosts.txt
name: MalwareDomainList.com Hosts List
id: 4
- enabled: true
url: https://easylist-downloads.adblockplus.org/easylistchina.txt
name: EasyList China
id: 1593851523
- enabled: true
url: https://www.i-dont-care-about-cookies.eu/abp/
name: I don't care about cookies
id: 1593851524
- enabled: false
url: https://gitee.com/privacy-protection-tools/anti-ad/raw/master/easylist.txt
name: anti ads
id: 1593851525
- enabled: true
url: https://filters.adtidy.org/extension/chromium/filters/224.txt
name: AdGuard Chinese filter
id: 1594425715
whitelist_filters: []
user_rules:
- '||open.trackerlist.xyz^$important'
- ""
dhcp:
enabled: false
interface_name: ""
gateway_ip: ""
subnet_mask: ""
range_start: ""
range_end: ""
lease_duration: 86400
icmp_timeout_msec: 1000
clients: []
log_file: ""
verbose: false
schema_version: 6
更加具体的配置选项可以参考:
延伸阅读
- adguard-sync 是一个同步配置的工具。
reference
Flexget 配合 NexusPHP 自动下载
之前整理过一篇文章总结了 Flexget 的一些常用方法,长久以来都是在 avistaz.to 生成 RSS,订阅下载,但后来发现国内的大多数站点都是使用 NexusPHP 运行,并且 RSS 支持(过滤条件)也不是非常完善,于是就发现了 flexget-nexusphp 这个插件。
flexget-nexusphp 是一个 Flexget 的插件,可以用来过滤 NexusPHP 的内容。
安装插件
Flexget 安装插件的方法非常简单,从 GitHub 获取 nexusphp.py 代码。将该文件移动到 Flexget 配置目录。
如果是和我一样使用 Docker 启动的 Flexget,在我上一篇 的配置中,我将 Flexget 的配置文件挂载到了本地目录,所以只要找到 ~/flexget/config 然后在该文件夹下创建 plugins 目录,并放入 nexusphp.py 即可。
注意 plugins 目录需要和 config.yml 这个 YAML 配置文件在同级。
然后重启 Flexget 容器。
配置
完成插件的安装之后就可以在配置文件中使用 nexusphp 选项。
tasks:
hdchina:
rss:
url: http://hdchina.org/rss.xml
other_fields: [link]
download: /data
nexusphp:
cookie: "hdchina=;_GRECAPTCHA=;PHPSESSID="
left-time: 1 hours
discount:
- free
- 2xfree
全部的配置选项:
nexusphp:
cookie: 'a=xxx; b=xxx' # 必填
discount: # 优惠信息 选填
- free
- 2x
- 2x50%
- 2xfree
- 50%
- 30%
seeders: # 做种情况 选填(兼容性较差不建议使用)
min: 1
max: 2
leechers: # 下载情况 选填(兼容性较差不建议使用)
min: 10
max: 100
max_complete: 0.8
left-time: 1 hours # 优惠剩余时间 选填
hr: no # 是否下载HR 选填
adapter: # 站点适配器,自行适配站点,参考最下方常见问题 选填
free: free
2x: twoup
2xfree: twoupfree
30%: thirtypercent
50%: halfdown
2x50%: twouphalfdown
comment: no # 在torrent注释中添加详情链接 选填
user-agent: xxxxxx # 浏览器标识 选填
remember: yes # 记住优惠信息 选填 请勿随意设置
配置解释:
cookie网站cookie 必须填写discount优惠类型 默认不限制优惠类型。
列表类型,Flexget会只下载含有列表内优惠类型的种子。
有效值:free 2x 2x50% 2xfree 50% 30%
注意:x为英文字母seeders做种情况 做种人数超出范围的,Flexget将不会下载注意:此选项兼容性较差min最小做种人数。整数,默认不限制max最大做种人数。整数,默认不限制
leechers下载情况 下载人数超出范围的,Flexget将不会下载注意:此选项兼容性较差min最小下载人数。整数,默认不限制max最大下载人数。整数,默认不限制
max_complete下载者中最大完成度 超过这个值将不下载。 小数,范围0-1.0,默认为1left-time最小剩余时间 当实际剩余时间小于设置的值,则不下载。 时间字符串,例如3 hours、10 minutes、1 days。 例如设置1 hours,优惠剩余59分钟,那么就不下载。默认不限制hr是否下载HR种 默认 yesyes会下载HR,即不过滤HRno不下载HR
adapter站点适配器 站点不兼容时可自定义,具体参考 判断站点以及适配站点comment在torrent注释中添加详情链接yes在torrent注释中添加详情链接,方便在BT客户端查看no默认值
user-agent浏览器标识 默认为Google浏览器remember记住优惠信息 不建议设置为 no,因为会增大站点压力。默认 yes
最后,个人也搭建了一个私人的 PT,分享一些电影、图书、综艺,欢迎来玩。
Obsidian 未来的笔记应用
看过我过去文章的人都知道在此之前我都使用 WizNote 来作为本地笔记应用,但是这两年在记笔记这件事情上出现了非常多的可能性,虽然我本人一直在关注着不同类型的笔记应用,从传统的 Evernote,OneNote 到 Notion 等等模块化的笔记应用,多多少少也尝试了一下,但是一直没有深入的去用,因为就我目前的需求,WizNote + 本地的 markdown + vim + git 基本就满足了,直到昨天晚上我在豆瓣上阅读了 笔记类软件的双向链新浪潮 这篇文章,然后我发现原来我在记笔记的时候遇到的一些问题原来还有这样一种解决方式。
存在的问题
我在用纯手工方式管理笔记的时候遇到的这些问题,中间我也曾想使用 wiki 来代替笔记,尝试了 [[GitBook]], BookStack, [[TiddlyWiki]] 等等,都或多或少的有些问题。
多媒体管理
我用原来 markdown + vim + git 的方式存在的最大的问题就是多媒体文件的管理,如果我只简单的记录文本,没有那么多的媒体(图片,音视频) 需要管理,还是能够非常方便的进行管理的,而一旦图片等等媒体文件成倍增长时,这个时候我就陷入了管理困境。
而 Obsidian 将媒体文件和 markdown 文件存放到一起,并且可以简单的使用名字相互进行关联,这使得管理变的轻松。内建的录音器甚至可以直接录音后在文件中插入音频内容。
链接
关于内链,可能我的思路还停留在上个世纪的“超链接”,我文章的大部分链接都是通过超链接相互关联的,而在 WizNote 中,将不同的笔记内容进行关联,我就只能使用 tag,或者手工进行分类来实现。而分类和 Tag 存在一些缺点,比如有些内容可能并不能以某一个分类概括,又或者可能被划分到多个分类下,而 Tag 虽然可以一定程度上避免分类的问题,但是在确定 Tag 的时候就会遇到如何定义 Tag 的问题,比较笼统的定义还是比较精确的定义。
而在 Obsidian 中,只需要 [[topic]] 就可以非常方便的实现链接到名为 topic 的文章,而这一切都是 Obsidian 做的,并且 topic 的这篇笔记甚至可以不存在,在写的时候写下,然后 Obsidian 会生成链接,只需要点击就可以快速的创建这个 topic. 到这里我才发现原来我那种手工管理内部链接的方式简直太愚蠢了。更甚至通过链入和链出就形成了一个非常庞大完整的网状结构,这样就将历史的笔记也可以以这种形式激活起来,不断的丰富自己的知识网络。
在 Obsidian 中通过 internal link 和 graph view 完美的解决了笔记之间关联的问题。
What is Obsidian?
Obsidian 这样介绍自己:
Obsidian is a both a Markdown editor and a knowledge base app.
直接献上官网地址:
再来看看预览图:
安装
Linux 下官方默认给出的是 AppImage,还可以下载 snap 包,通过如下方式安装:
sudo snap install obsidian.snap --dangerous
如果不添加 --dangerous 可能会报错:
error: cannot find signatures with metadata for snap “obsidian_0.13.19_amd64.snap”
特性
Obsidian 这些功能是吸引我让我尝试的理由。
本地化数据
所有数据都以本地文本形式保存。其他一些软件使用私有的格式保存用户数据是让我避而远之的原因之一。
Obsidian 管理的所有数据都在本地,那也就意味着用户可以选用自己喜欢的任何同步工具进行数据加密,同步等等。比如现成的同步方案 Dropbox 等等,而我选择使用另一款 分布式同步工具 Syncthing
Links 是一等公民
如果上手使用 Obsidian,那么第一感受就是可以在笔记的任何地方非常快速的创建内链,通过内链的方式,系统里面的笔记就形成了网状的结构,这也是 bi-directional linking 双向内链的精髓之处。
| Obsidian 在官方的 Demo 中引述了 [[洛克 | 约翰 洛克]] 在 1690 年发表的 《An Essay Concerning Human Understanding》来解释人类思想形成的方式: |
The acts of the mind, wherein it exerts its power over simple ideas, are chiefly these three:
- Combining several simple ideas into one compound one, and thus all complex ideas are made.
- The second is bringing two ideas, whether simple or complex, together, and setting them by one another so as to take a view of them at once, without uniting them into one, by which it gets all its ideas of relations.
- The third is separating them from all other ideas that accompany them in their real existence: this is called abstraction, and thus all its general ideas are made.
简单的翻译:
- 首先将几个简单的想法组合成一个复杂的想法,从而完成所有复杂的思维过程;
- 第二,是将简单或复杂的两个想法放到一起,相互设置关联,方便查看它们,而同时又不将它们融合到一起,从而可以一眼查看所有想法之间的关联。
- 第三,是将这些想法与实际存在的所有其他思想分开:这称为抽象思维,这是所有普适思想形成的过程。
笔记的层级关系 (Hierarchy) 实现了第一点,而内部链接 (linking) 正是第二点,而第三点如何在笔记中应用, Obsidian 的作者也没有想清楚,但他也说了,这可能是更高阶的抽象 —- but it might have something to do with programming or macros.
用户拥有所有工具链
记笔记是一件非常个人化的事情,这也就意味着不可能有一个包容一切的解决方案适用于所有人。
Note-taking is an incredibly personal thing
所以 Obsidian 并不会武断地尝试去提供一个完整的产品,而是提供一个基础功能以及很多的功能模块,用户可以自己创造并实现自己的需求。
最基础的功能包括,查看文件,编辑文件,搜索文件,而这对于一般的需求也已经完全足够。在此之上,你可以构建独立的功能模块来增加笔记的体验,比如:
- 如果是记录上课的笔记,那么可以使用 audio recorder 和 LaTex math
- 如果是记录工作笔记,可以使用 slides 和手写支持
- 而如果你是研究工作者,backlinks(反向链接)和字数统计就很重要
Obsidian 不期望有一个插件可以解决所有的问题,但 Obsidian 提供了足够的自由度,在能够实现不同需求的时候,也不会搞乱界面。
我的常用快捷键和 remapping
最常用的快捷键整理,下面有一些是我已经 remapping 过的,可以根据自己的习惯重新设置快捷键的。
新建笔记相关:
| Shortcut | description |
|---|---|
| Cmd+n | New note |
| Cmd+Shift+n | New Zettelkasten note |
| Cmd+p | Filter the command |
编辑相关的:
| Shortcut | description |
|---|---|
| Cmd+b | bold |
| Cmd+i | italic selection |
| Ctrl+Alt+L | format markdown (借助 Linter 插件) |
笔记间跳转:
| Shortcut | description |
|---|---|
| Cmd+o | Open quick switcher, jump to different notes by fuzz search |
| Option+Enter | follow the link under cursor |
| Cmd+Option+Enter | Open link under cursor in new pane |
Cmd+[ |
Back |
Cmd+] |
Forward |
| Cmd+hjkl | Navigate to left/below/above/right pane |
| Cmd+w | Close active pane |
Cmd+\ |
Split vertically |
Cmd+- |
Split horizontally |
浏览模式:
| Shortcut | description |
|---|---|
| Cmd+e | Toggle edit/preview mode |
Obsidian 的模板功能非常强大,我自定义了一个快捷键 ⌘ + ⇧ + i 来从模板中快速插入到当前的文档中。
Zettelkasten method
卡片标签式笔记法,Obsidian 也可以兼容,启用插件后侧边栏点击就能够快速建立时间戳开头的笔记迅速进入编写。
延伸阅读
- [[Trilium Notes]] 基于网页的笔记
- [[Logseq]] 开源的基于块的双向链接笔记
- [[TiddlyWiki]] 单文件 Wiki
个人使用技巧
使用 GitHub 作为同步后端
都知道 Obsidian 其实是一个本地的离线客户端,官方截止 11 月份还没有推出同步的功能,但是优先推出了 Publish 服务,可以将笔记一键发布到 Obsidian 提供的网站上。但是对于我而言,我习惯将笔记在本地整理,然后将相关的内容整理成文章发布在这个博客中,所以剩下的问题就是我的本地笔记同步的问题了。
我个人是将 Obsidian 的本地仓库放到一个 Git 仓库中管理,并且每隔一定时间自动提交到 Git 中,这样即使我不在电脑边,也可以第一时间访问到我的内容。我使用 Hammerspoon 提供的 task api,写了一个 简单的脚本 自动提交仓库。
Links
Obsidian 的开发 Roadmap
对比其他产品
在整理了这篇文章半年后,我几乎每条都在使用 Obsidian,甚至用 Karabine 绑定了 ob 的快捷键 ,在任何情况,任何应用中,我只需要按下 o,不松开,然后快速按下 b,就可以 open Obsidian 了。
这是半年后的 Graph
虽然使用过程中从来没有遇到任何问题,但是却一直收到其他产品的推荐,比如 Logseq, RoamEdit 等等,虽然 Obsidian 已经足够满足我的使用了,但也经不住尝试了一下其他的产品,只能说今年因为 Roam Research 的创新激活了笔记应用的市场。
Logseq
[[Logseq]] 在自己的官网将自己描述为一个受到 Roam Research, Org mode, Tiddlywiki, Workflowy 启发的开源的 Roam 笔记应用,我打开官网尝试了一下,虽然双向链,块引用,运行在浏览器,以 GitHub 作为笔记的存储,看起来很美好,似乎是 Roam Research 的代替品,但是我在使用的过程中,不清楚是以为网络问题还是因为我没有登录的关系,体验并不是很好,一来创建新页面的时候卡了,而来默认的显示状态和编辑状态的变化略大,使得视觉上的体验不是很好。在界面交互上甚至并不能和其提到 Workflowy 的网页应用流畅度相比。不过因为其开源属性使得每一个人都可以根据自己的喜好进行扩展和修改,其未来可期。
另外一个需要注意的就是目前的 Logseq 只有网页版,并且因为 Logseq 网络访问需要经过其代理才能将数据保存到 GitHub,相较于 Obsidian 直接使用本地 Markdown 文件保存,Logseq 并不占优势。不过有能力可以自行搭建。
Logseq 目前已经可以使用客户端,所有的数据都可以离线在本地。
RoamEdit
看名字就知道又是一款 Roam Research 的仿作,不过让我惊奇的是其网页的流畅度相较于 Logseq 还是不错。但是问题依然是那样的,官网一行隐私说明都没有,一个备案号,一个交流群,看着就不想深入使用的样子。可能也是某位大神练手之作,值得鼓励。不过我就不去尝试使用了。
Workflowy
Workflowy 和 RoamEdit 比较类似,并且在网页操作上也比较流畅,但两者虽然都支持导出数据,但依然需要联网才能使用,和我个人的情况并不相符,就算了。
往往有些时候鱼与熊掌不可兼得,当选择了网页版,就自然地获得了数据的同步,也自然可以期望未来的多客户端同步,但问题也就是在此,一旦这些网络的服务关闭,或者再一个没有网络的地方,那么一切都没有办法获取了。而 Obsidian 使用纯文本的方式,并且桌面客户端并不会发起网络连接,那么自然就丢失了同步的便利,而与此同时你也就获得了自己笔记的所有权,即使 Obsidian 未来不再更新了,那么也可以使用 Vim 或者 VS Code 的 Foam 获得一份相差不多的体验,并且因为是纯文本,所以那些 终端里的工具 ,比如 fzf , Vim , rg 等等都可以直接拾起来用。这样的体验反而要比等待网络连接,然后才能进行操作要来的快捷方便很多。另外 Obsidian 不能在移动端使用的问题,我通过 Syncthing 加上 Markor 完美的解决了。其他移动端的可以参考官网给出的 建议 。
再就是块应用,Obsidian 不支持,但是 Obsidian 可以对笔记的子标题进行引用,对我来说似乎也已经足够了。毕竟 Zettelkasten 的精髓部分就是每一则笔记的原子性。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。