IntelliJ IDEA vmoptions 设置
IntelliJ IDEA 运行在 JVM 上,JVM 有很多的选项和开关配置可以用来调整性能,也就是说,可以通过手动的调整这些 JVM 参数来优化 IntelliJ IDEA 的性能。这篇文章主要是总结一下我的学习过程。
打开 memory indicator
首先打开 Memory Indicator
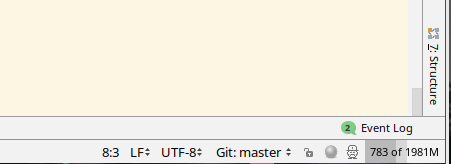
可以在设置中设定:
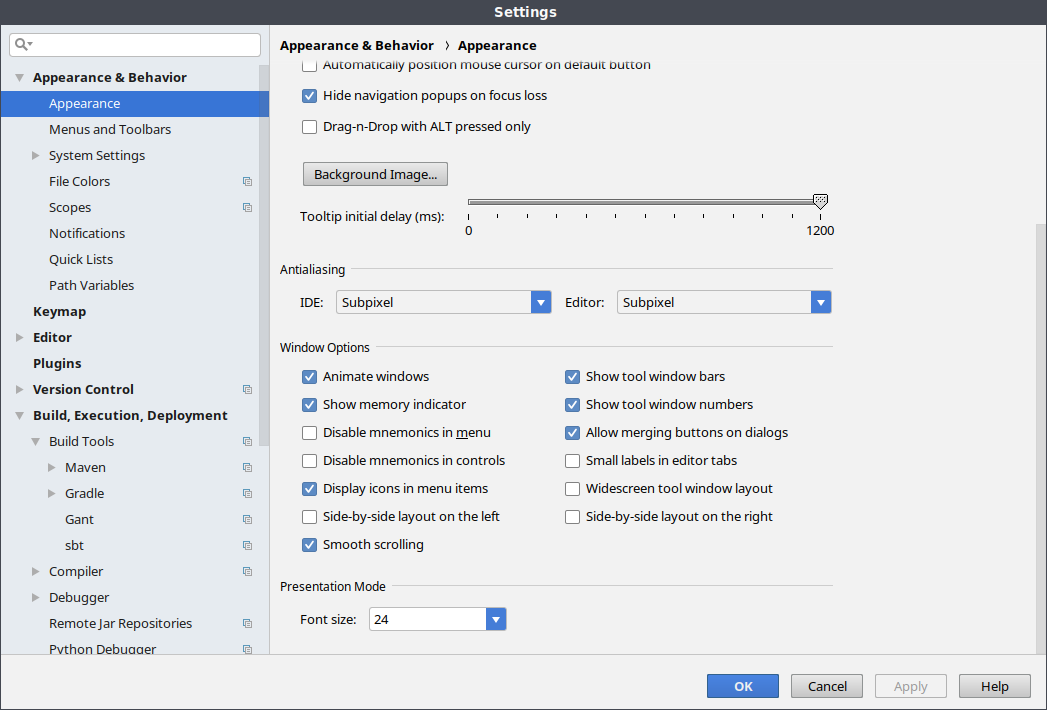
或者新版本中,只需要右击右下角状态栏然后选择 memory indicator 即可。
可以看到普通使用 IntelliJ IDEA 大概就使用了 800M 左右的内存。
Edit VM Options
在菜单 Help | Edit Custom VM Options 中可以设置。
VM options
下载安装包后一定要把压缩包下的 README 读完,里面有详细的路径及配置说明。这里先给一个全部内容的预览,下面再一一解释。
-ea
-Xms2g
-Xmx2g
-XX:ReservedCodeCacheSize=240m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=50
-Dfile.encoding=UTF-8
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-Dawt.useSystemAAFontSettings=lcd
-Dsun.java2d.renderer=sun.java2d.marlin.MarlinRenderingEngine
heap size
-Xms 和 -Xmx 配置堆内存,也就是 IntelliJ 可以使用的内存。
-Xms初始堆内存,调大该内存可以让启动速度更快,以省去分配内存的时间-Xmx最大堆内存,如果遇到OutOfMemoryError可以调大该数值,最大不要超过系统 1/4.
GC Algorithm
-XX:+UseConcMarkSweepGC 参数用来调整 GC 算法。使用该算法利用多个线程在后台进行 GC,以避免应用程序停止。
当分配超过 4GB 的堆内存时,可以尝试使用 -XX:+UseG1GC.
Other
-ea 选项开启 assertions。如果调试 IntelliJ 或者开发插件时可能用到,对 IntelliJ 性能并没有影响。
-server 虚拟机的解释执行模式。
-XX:SoftRefLRUPolicyMSPerMB=[value] 参数用来控制每 M 空间中 soft reference 保证存活的毫秒数。默认的时间是 1000,JetBrains 推荐 50。
-XX:ReservedCodeCacheSize=510m 设置编译器最大的 code cache,另外一个相关的 JVM 参数是 -XX:InitialCodeCacheSize
JetBrains 推荐这里使用 240m. 1
-Dsun.io.useCanonCaches=[boolean] 该参数是否开启文件名及路径缓存,默认 java 会缓存文件名 30 秒 2,JetBrains 建议关闭。
-XX:+OmitStackTraceInFastThrow JetBrains 官方推荐的参数。
-XX:MaxJavaStackTraceDepth=-1 JVM 在实现 java.lang.Throwable.fillInStackTrace() 时把整个调用栈上的所有 Java 栈帧消息记录下来
-XX:+HeapDumpOnOutOfMemoryError 当发生 OutOfMemoryError 时 dump 堆内容。3
reference
每天学习一个命令:使用 rz sz 向服务器发送文件
搜索 rz sz 命令使用方式进来的,可以不用往下看了,直接学习 scp 或者 rsync 吧, rz sz 看了一下还是有很多限制的。
虽然它可以实现向服务器发送文件,或者接受服务器的文件,但是限制条件必须在 screen 中执行,另外如果要在 Tmux 中使用还需要特殊的 hack 1
使用
所以最基本的使用就是:
rz -be
分析家里局域网 WiFI 瓶颈
目前我的情况是,家中有一个千兆主路由放在客厅接外面的宽带,而我自己的房间有一台比较老的 Netgear 3800 路由来无线桥接连接外面的主路由,因为我不想我的 3800 路由中的设备暴露到主路由的设置中,所以用了 OpenWrt 的桥接模式。但是随着我在 3800 这台路下接的设备增多,导致目前 3800 这台路由不堪重负,已经影响到了我日常 streaming 局域网 NAS 中的电影。所以最近想更换一下这台已经 8 年历史的 WNDR 3800 路由器。
首先我了解了一下,WNDR3800 标称的是 300Mbps 双频千兆路由器,WiFi 下 5GHz,理论传输速率应该有 37.5MB/s,但实际应该是达不到的,但即使只有一半的速率 10MB/s ,理论上串流局域网的视频应该是问题不大的,而现在的问题就出现在局域网中用 WiFi 连接的设备,理论上只能达到 4MB/s 的峰值速度。
网线比较老
首先细想了想理论上我的 WNDR3800 路由下面四个 LAN 口都是千兆网口,有线速度不应该那么差的,所以我先用我现有的几根网线连接了设备,但发现速度依然不够理想。
用 iperf 测试两台使用网线连接的设备,测试的速度大致只有在 30~45 Mbits/s 左右,换算成传输的速度除以 8,那就比较可怜了。
我就有点怀疑我的网线,可能是比较老的网线(这几根网线已经跟随我差不多快 6 年了,所以应该就是一个最高百兆的网线),所以立即下单了两根六类网线。
网线区别
如何识别五类网线,超五类网线?
- 五类网线,会标注 「CAT5」字样,传输带宽为 100MHz,用于语音传输和最高传输速率为 100Mbps 的数据传输
- 超五类网线:标注 「CAT5e」 字样,传输带宽可高达 1000Mb/s,但一般只应用在 100Mb/s 的网络中,只实现桌面交换机到计算机的连接,因为超五类非屏蔽网线要借助价格高昂的特殊设备的支持
- 六类网线:标注 「CAT6」字样,一般指的都是非屏蔽网线,主要应用在千兆网络中,在传输性能上远远高于超五类网线标准
设备网卡
在怀疑完网线之后,就想是不是设备接口的限制,于是就从路由器开始排查。
路由器
确定是千兆网口
盒子
查了一下 T1 盒子的无线网卡:
- 双频 WiFi,支持 ac,单天线,2.4G 连接速率 65Mbps,5G 连接速率 433 Mbps
而一查有线网卡,竟然是一个百兆网卡,怪不得比无线还慢。既然有线不能用,那就只能上无线了。
WIFI 带宽不够
首先盒子的无线网卡是支持 802.11 ac 协议的,理论上是没有跑满带宽的,那么就是无线路由器到了上限。300Mbps 是 WNDR3800 标称的传输速度,但是实际即使靠的最近也不大可能达到理论速度的。再者我的 WNDR3800 有线连着一台 NAS,一台 Proxmox 服务器,本来传输压力就有些大,所以我期望无线能达到理论的一半就已经很好了,但实际上我测试,用一台 WNDR3800 有线连接的设备开启 iperf -s,再用一台无线连接,iperf -c IP,测试的结果是 60 Mbits/s 左右。
然后我想起来我还有一台小米路由器 (Mi Wifi 3G),之前因为总是断线所以就收起来了,然后去官网 查了一下配置,发现配置要比我的 WNDR3800 好不少,并且用 Android 连接后可以达到 800Mpbs。
- 处理器 MT7621A MIPS 双核 880MHz
- ROM 128MB SLC Nand Flash
- 内存 256MB DDR3-1200
- 2.4G 2X2(支持 IEEE 802.11N 协议,最高速率可达 300Mbps)
- 5G 2X2(支持 IEEE 802.11AC 协议,最高速率可达 867Mbps)
- 外置全向高增益天线 4 根(2.4G 最大增益 5dBi 2 根 5G 最大增益 6dBi 2 根)
- 1 个 USB 3.0 接口(DC output:5V/1A)
- 1 个千兆 WAN 口,两个千兆 LAN 口,LAN 稍微少了点

所以现在就是要找一个比较稳定的固件了,官方的固件,无疑就是 OpenWrt 了。
IEEE 802.11 a/b/g/n/ac
Protocol
20MHz vs 40MHz 信道宽度
在 OpenWrt
- 对于 2.4 G 和 20 MHz,最好的 channel band 是 1,6,11
- 对于 2.4 G 和 40 MHz,最好的 channel band 是 3,11
- 对于 5G 和 20 MHz, 如果设备都支持最好使用 40 MHz,或者如果路由设备支持可以使用混合模式
- 对于 5G 和 40 MHz,任何少量信道的 channel 都可以。或者考虑让路由器自动选择最好的 Channel。
Further More
- Android 上可以使用 WiFiAnalyzer 查看
- 对于 Windows 可以使用 NetStumbler 来查看附近的网络。
reference
GitLab CI 使用笔记
CI/CD 不必多说。
CI/CD 解决的问题:
- 重复劳动
- 等待时间
- 手工出错
基本概念
gitlab CI 依赖于项目根目录中定义的 .gitlab-ci.yml 文件,这个文件定义了 GitLab CI 应该做的事情。每次提交代码 GitLab 会检查该文件,然后将该文件定义的内容提交给 GitLab Runner 执行。
CI/CD
- CI : Continuous integration,持续集成,代码有改动时触发编译、测试、打包等一系列构建操作,最后生成一个可部署的构件。指开发⼈人员在特定分⽀支(频繁)提交代码,⽴立即执⾏行行构建和单元测试,代码通过测试标准后集成到主⼲干的过程。强调的是分⽀支代码的提交、构建与单元测试。
- Continuous Delivery,持续交付,在持续集成的基础上,将构建的代码部署到「类⽣生产环境」
- Continuous Deployment, 持续部署,CI 之后自动化地部署或交付给客户使用。
pipeline
gitlab-ci 中配置的所有可执行的 job 称为 pipeline,Pipeline 可以认为是一次构建过程。Pipeline 中可以包含多个 stage.
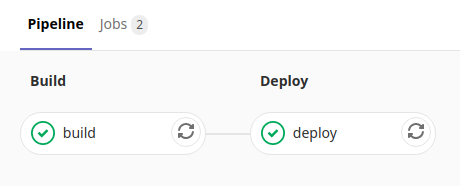
在 GitLab 后台可以看到如图,整个过程称为一个 pipeline,这个 pipeline 包括两个 stage(阶段)。每个阶段就只有一个任务,gitlab-ci 在运行时只有当一个 stage 中所有的任务都执行完成才会进入下一个 stage.
首先来对 .gitlab-ci.yml 文件有一个整体的了解。
# 定义 stages
stages:
- test
- build
# 定义 job
job1:
stage: test
script:
- echo "test stage"
job1_1:
stage: test
script:
- echo "test stage: job1_1"
# 定义 job
job2:
stage: build
script:
- echo "build stage"
stage
stage 可以理解为阶段,是 gitlab-ci 的概念,流程中的阶段,可以包括测试,编译,发布,部署等,在 .gitlab-ci.yml 文件中会用到。
- GitLab CI 文件中必须包含至少一个 stage
- 多个 stage 按照顺序执行
- 如果其中任何一个 stage 发生错误,之后的所有 stage 都不会被执行。
- 同样只有所有的 stage 都成功,Pipeline 才会成功
定义:
- stages:
- build
- deploy
- release
job 或者 app
job 或者又被称为 app,由 job 组成 gitlab-ci 的 stage 阶段,多个 job 可以并发执行。
- 同一个 stage 下的 job 会并行执行
- 同一个 stage 下的 job 都执行成功,该 stage 才会成功
- 如果 job 执行失败, 那么该 stage 失败,pipeline 失败,该次构建过程失败
举例:
build_front:
stage: build
build_backend:
stage: build
上面两个 app (build_front, build_backend) 将会在 build 阶段并发执行。
variables
gitlab-ci 中集成了很多默认的变量,可以通过 variables 关键字来定义自己的变量,也可以在 gitlab 提供的界面上配置。gitlab 提供的 UI 可以配置全组或者 project 级别的环境变量。
- group 级别
- project 级别
比如一些敏感的信息,比如 Nexus 密码,Docker Registry 密码或者密钥之类等等
GitLab Runner
GitLab CI 中是 Runner 真正在执行 .gitlab-ci.yml 中定义的任务,Runner 可以是虚拟机,物理机,Docker 容器或者容器集群。GitLab 和 GitLab Runner 直接通过 API 通信,所以需要保证 GitLab 和 Runner 直接可以通过 HTTP 进行通信。
GitLab Runner 可以分为两种类型: Shared Runner (共享型) 和 Specific Runner(指定)
- Shared Runner: 所有工程都可以使用,只有系统管理员可以创建
- Specific Runner: 只有特定的项目可以使用
Install Runner
GitLab Runner 的安装参考官方网站 即可,代码也是开源的.
常用关键词
全部的关键词可以在官网 查看。
script
最常用的一个关键词了,script 定义具体需要执行的任务。
before_script
before_script 定义在每一个 job 之前的任务,必须是 Array 类型。
after_script
after_script 每一个 job 之后执行,即使 job 失败了也会执行,Array 类型。
cache
定义需要缓存的文件或者路径。
Use case
对部分文件修改判断是否触发该阶段
有时候没有修改一些可能需要重新跑 build 的代码,不想 GitLab Runner 空跑,可以使用 only 关键字,以及 change 关键字实现只有部分文件改动后再触发 build.
only: # 下面的条件都成立
refs: # 下面的分支中任一分支改变
- release
changes: # 下面的文件中任一文件发生改变
- .gitlab-ci.yml
- Dockerfile
当 release 分支改变,同时 .gitlab-ci.yml 文件或者 Dockerfile 文件发生改变时,触发这个阶段的执行。
多个模块编译方式不同
假如一个项目中集成了很多个模块,而每一个模块中的内容编译方式都不同。那么可以使用 gitlab-ci 提供的 include 关键字,对各个模块进行分拆。在每一个模块下放置 .gitlab-ci.yml 文件,然后再到根目录中创建 .gitlab-ci.yml 文件使用 include 关键字引入进来,对各个模块进行解耦。
include:
- local: module1/.gitlab-ci.yml
- local: module2/.gitlab-ci.yml
模板
集成 sonar
Build:
stage: build
script:
- echo 'build projects'
- "mvn $MAVEN_CLI_OPTS clean compile -Dmaven.test.skip=true"
- 'mvn $MAVEN_CLI_OPTS -U clean package -Dmaven.test.skip=true'
- 'mvn $MAVEN_CLI_OPTS sonar:sonar -Dsonar.projectKey=projectname -Dsonar.host.url=http://url -Dsonar.login=xxxxx'
Test:
stage: test
script:
- echo 'test projects'
- 'mvn $MAVEN_CLI_OPTS clean test'
only:
- master
- staging
reference
使用命令行远程网络唤起主机
在 Linux 下可以通过 etherwake 命令来网络唤醒设备。
sudo apt install etherwake
检查主机是否支持网络远程唤醒
首先检查 BIOS 中设置,Wake on LAN 是否开启。一般在 BIOS > Power Management > “Wake On LAN” 这个选项下。然后重启进入系统,用如下命令查看网卡 eth0 是否开启了 Wake on LAN:
ethtool eth0
输出:
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: off (auto)
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
结果中可以一眼就看到:
Supports Wake-on: pumbg
Wake-on: g
如果没有看到这个字样,或者是 off 状态,需要手动启动一下:
ethtool -s eth0 wol g
说明:
-s NIC, 我这里的 eth0 是网络接口的设备名,根据不同的设备填写不同,可以通过ifconfig来查看wol g表示设置 Wake-on-LAN 选项使用 MagicPacket.
使用命令远程唤醒
在 Linux 下执行如下命令唤醒设备:
sudo apt install wakeonlan
wakeonlan MAC_ADDRESS
或者
etherwake MAC_ADDRESS
可以通过 ping 命令和 arp 命令来获取局域网中的设备 MAC 地址:
ping -c 4 SERVER_IP && arp -n
reference
Cloud-init 初始化虚拟机配置
在安装 Proxmox 后在它的文档中了解到了 cloud-init。所以就来梳理一下,什么是 cloud-init,它解决了什么实际问题,以及最重要的它该怎么用。
cloud-init 是什么
cloud-init 是一套工业标准为的是统一不同操作系统发行版在跨平台的云端服务器上初始化安装的流程。 cloud-init 是运行在 Guest machine 中,并在初始化时将一些自定义的配置应用到 Guest machine 中的应用程序。想象一下,假如你是一个云主机提供商,每天都需要为客户初始化成千上万台虚拟主机,这些机器可能使用不用的操作系统,可能根据客户需求设定不同的 IP 地址,不同的 SSH key,以及设置不同的 hostname 等等,这个时候需要怎么办,cloud-init 就是为了解决这个问题而诞生的。
cloud-init 最早由 Ubuntu 的开发商 Canonical 开发,现在已经支持绝大多数 Linux 发行版和 FreeBSD 系统。而目前大部分的公有云都在用 cloud-init 初始化系统配置,cloud-init 也支持部分私有云 (KVM, OpenStack, LXD 等等) 1,已经成为了事实上的标准。而这里就回到了 Proxmox,因为 Proxmox 是用来部署和管理虚拟机的平台,所以天然的适合 cloud-init 的使用场景,甚至可以说是不可或缺的一部分。
当我们在 AWS,或者 Google Cloud 这些公有云中申请计算资源的时候,云服务的提供商总是会叫我们选择一个系统镜像,然后做一些基础设置 (Hostname, SSH key 等等),然后在此基础上进行系统创建。cloud-init 正是在这个背景下诞生,自动化将用户数据初始化到系统实例中。
cloud-init 的主旨是定义一些独立于操作系统的配置,比如 hostname, networking configuration 等等。
cloud-init 特性:
- 设置默认的 locale
- 设置 hostname
- 生成并设置 SSH 私钥
- 设置临时的挂载点
Boot Stages
cloud-init 对系统的初始化分为这几个阶段:
- Generator
- Local
- Network
- Config
- Final
Generator
当系统启动的时候,generator 会检查 cloud-init.target 是否需要启动。默认情况下,generator 会启动 cloud-init. 但是如下情况 cloud-init 不会在开机运行:
/etc/cloud/cloud-init.disabled文件存在时- 当内核命令发现文件
/proc/cmdline包含cloud-init=disabled时,当在容器中运行时,内核命令可能会被忽略,但是 cloud-init 会读取KERNEL_CMDLINE这个环境变量
Local
Local 阶段会在挂载根分区 / 时,立即执行
cloud-init-local.service
Local 阶段的目的是:
- 查找
localdata source - 将网络配置应用到本地
大多数情况下,这个阶段就只会做这些事情。它会在 datasource 中查找,并应用网络配置。网络配置可能从这些地方来:
- datasource: 云端通过 metadata 提供
- fallback: 通过
dhcp on eth0,在虚拟机内自行通过 DHCP 获取 IP - none: 网络配置可以通过
/etc/cloud/cloud.cfg中配置network: {config: disabled}来禁用
如果是该实例的第一次启动,那么被选中的网络配置会被应用,所有老旧的配置都会会清除。
该阶段需要阻止网络服务启动以及老的配置被应用,这可能带来一些负面的影响,比如 DHCP 服务挂起,或者已经广播了老的 hostname,这可能导致系统进入一个奇怪的状态需要重启网络设备。
cloud-init 然后再继续启动系统,将网络配置应用后启动。
Network
在 local 阶段后,网络服务启动后,启动
cloud-init.service
该阶段需要所有的网络配置已经被应用,并且网络在线,然后才会应用所有的 user-data
- 递归检索任何
#include或者#include-once包括 http - 解压缩任何压缩的内容
- 运行任何找到的 part-handler
该阶段运行 disk_set 和 mounts 模块,可能会分区并格式化任何配置挂载点(比如 /etc/fstab中)的磁盘。这个模块不能再早运行,因为有可能有些信息来源于网络,只有等网络信息获取到后才能执行。比如用户可能在网络资源中提供了挂载点配置信息。
在一些云服务中,比如 Azure,这个阶段会创建可以被挂载的文件系统。
part-handler 也会在这个阶段运行,包括 cloud-config bootcmd。
Config
在网络启动后运行:
cloud-config.service
这个阶段只会运行 config 模块,不会对其他阶段产生影响的模块在这里运行。
Final
启动的最后阶段运行:
cloud-final.service
用户登录系统后习惯于运行的脚本在这个阶段运行,包括:
- 包安装
- 配置管理的插件 (puppet, chef, salt-minion)
- 用户脚本(包括
runcmd)
Install and use cloud-init under Proxmox
cloud-init 一般是安装在虚拟机中的,Ubuntu 系的系统直接安装即可:
apt install cloud-init
绝大部分的发行版会提供开箱即用 (ready-to-use) 的 Cloud-Init 镜像(一般以 .qcow2 文件发布),所以你可以下载这些文件,然后直接导入。比如说 Ubuntu 提供的镜像:https://cloud-images.ubuntu.com/
虽然大部分发行版都提供了开箱即用的 Cloud-Init 镜像,但还是推荐如果要更高的定制化需求可以自己来制作符合自己需求的镜像。
在 Proxmox 下,一旦制作好了 Cloud-Init 镜像,推荐将该镜像转换成 VM template, 通过 template 可以快速创建虚拟机。
# download
wget https://cloud-images.ubuntu.com/bionic/current/bionic-server-cloudimg-amd64.img
# create a new vm
qm create 9000 --memory 2048 --net0 virtio,bridge=vmbr0
# import the downloaded disk to local-lvm storage
qm importdisk 9000 bionic-server-cloudimg-amd64.img local-lvm
# finally attach the new disk to the VM as scsi drive
qm set 9000 --scsihw virtio-scsi-pci --scsi0 local-lvm:vm-9000-disk-1
Add cloud-init CDROM drive
qm set 9000 --ide2 local-lvm:cloudinit
为了从 Cloud-Init 镜像直接启动需要设置 bootdisk 参数到 scsi0,然后设置 BIOS 从 disk 启动
qm set 9000 --boot c --bootdisk scsi0
然后配置 serial console 将其作为显示输出,这是 OpenStack 镜像必须设置的内容
qm set 9000 --serial0 socket --vga serial0
Prepare template
最后就可以将 VM 转换成 template,然后通过该模板就可以快速创建 clones,从 VM templates 部署系统要远远快于一个完整的 clone:
qm template 9000
Deploying Cloud-Init Templates
可以使用如下命令从 template 中克隆系统:
qm clone 9000 123 --name ubuntu2
设置 SSH,及网络(这里的 IP 地址需要改成自己的网络环境的地址):
qm set 123 --sshkey ~/.ssh/id_rsa.pub
qm set 123 --ipconfig0 ip=10.0.10.123/24,gw=10.0.10.1
配置文件地址
cloud-init 配置文件在:
/etc/cloud/cloud.cfg
/etc/cloud/cloud.cfg.d/*.cfg
cloud-init 在配置文件 /etc/cloud/cloud.cfg 中定义了各个阶段需要执行的任务,任务以 module 形式组织。
cloud.cfg 中指定了 set_hostname 这个 module, 则表示 cloud-init 会执行设置 hostname 的任务,但是具体设置的内容由 metadata 指定。
cloud-init 的日志在:
/var/log/cloud-init-output.log: 每一个阶段的输出
/var/log/cloud-init.log: 每一个操作更详细的调试日志
/run/cloud-init: contains logs about how cloud-init decided to enable or disable itself, as well as what platforms/datasources were detected. These logs are most useful when trying to determine what cloud-init ran or did not run.
数据存放在:
/var/lib/cloud
在 Ubuntu Server 18.04 中设置静态 IP 地址
在安装 ubuntu server 18.04 的时候没有选择用静态地址,所以路由器 DHCP 随机分配了一个,然后进系统才想起来配置一下静态地址。传统的做法是修改 /etc/network/interfaces 文件,配置接口的静态地址即可。不过网上搜索一番学习之后发现了一个新方法,使用 netplan 来做修改。2
修改 /etc/netplan/50-cloud-init.yaml 文件,原来的 DHCP 配置可以看到 dhcp4: yes 这一行配置的是 yes,现在修改成这样:
network:
ethernets:
ens18:
dhcp4: no
addresses: [192.168.2.10/24]
gateway4: 192.168.2.1
nameservers:
addresses: [114.114.114.114, 8.8.8.8]
version: 2
然后应用到接口:
sudo netplan --debug apply
sudo netplan apply
这里千万要小心配置,如果配错可能导致无法连上系统的!
reference
BitTorrent 协议中的 BenCode 编码
在了解 BitTorrent 协议的时候,想着 .torrent 文件是如何生成的,所以就找了几个 CLI,比如 transmission-cli 和 mktorrent这两个开源的制作 torrent 文件的开源项目,发现他们就是按照一种约定的格式来生成文件。而这个约定的结构中就少不了现在要谈的 BenCode 编码。
BitTorrent 协议使用 .torrent 文件来描述资源信息。.torrent 文件使用一套 BenCode 编码来对信息进行描述。
What is BenCode
BenCode 是用于编码 torrent 文件的一种编码格式。BenCode 支持四种数据类型:
- 字符串 String
- 整数 Integer
- 数组 List
- 字典 Dictionary
需要注意的是 BenCode 只用 ASCII 字符进行编码,如果是非 ASCII 码,BenCode 会用一种编码方式将其转换成 ASCII 码。
字符串
在编码字符串时 BenCode 选择将字符长度编码在其中:
<Length>:<Content>
比如 6:string 就表示 string 本身。其中 6 表示的是字符串长度。长度使用十进制表示。
整数
整数编码时在前后加 i 和 e,比如:
i123e
表示整数 123 . 这种方式也可以表示负数:i-1e.
不过需要注意的是 i-0e, i03e 这样的表示是非法的,但是 i0e 是合法的,表示整数 0 .
数组
列表前后用 l 和 e 标识。列表中的元素可以是 BenCode 支持的任何一种类型。比如要编码字符串 content 和数字 42:
l7:contenti42ee
注意这里每个类型的边界都有定义清楚。字符串可以用长度来限定边界,但是整数一定需要 i 和 e 来限定边界。
字典
字典类型可以保存一对一的关系,在 BenCode 中 KEY 必须为字符串类型,而 VALUE 可以是 BenCode 支持的任意一种类型。字典编码时用 d 和 e 限定范围。
另外需要注意,字典中 KEY 和 VALUE 必须相邻,字典依照 KEY 的字母序排序。
比如要定义 “name” -> “Ein Verne”, “age” -> 18, “interests” -> [“book”, “movie”]
首先要到 KEY 进行排序 “age”, “interests”, “name”
3:age9:Ein Verne
9:interestsi18e
4:namel4:book5:moviee
然后把上面的 KEY VALUE 连接起来,并在前后加上字典的 d 和 e 限定。
d3:age9:Ein Verne9:interestsi18e4:namel4:book5:movieee
总结一下
| 类似 | 数据 | 编码 |
|---|---|---|
| int | -42 | i-42e |
| string | ‘span’ | 4:spam |
| list | [‘XYZ’, 432] | l3:XYZi432ee |
| dict | {‘XYZ’: 432} | d3:XYZi432ee |
torrent 文件
在了解了 BenCode 的编码后,用纯文本文件打开 .torrent 文件就能知道一二了。本质上 torrent 文件就是一个用 BenCode 编码的纯文本文件,torrent 在 BitTorrent 协议中又被称为 metainfo。
metainfo 是一个 BenCode 编码的字典:
announce
tracker 的地址
info
字典,单文件和多文件略有不同
torrent 文件中的所有字符串必须是 UTF-8 编码的。
单文件
我在本地新建了一个 README.md 文件,然后用如下命令创建一个 torrent 文件 “test.torrent”.
mktorrent -a http://announce.url -c "This is comments" -l 18 -o "test.torrent" -p -v README.md
然后查看 cat test.torrent 内容:
d8:announce19:http://announce.url7:comment16:This is comments10:created by13:mktorrent 1.013:creation datei1585360743e4:infod6:lengthi5e4:name9:README.md12:piece lengthi262144e6:pieces20:h7@xxxxxlxx]7:privatei1eee
拆解这个编码,先分段开。
d
8:announce -> 19:http://announce.url
7:comment -> 16:This is comments
10:created by -> 13:mktorrent 1.0
13:creation date -> i1585360743e
4:info
d
6:length -> i5e
4:name -> 9:README.md
12:piece length -> i262144e
6:pieces -> 20:h7@xxxxxxxxx
7:private -> i1e
e
e
拆解后可以看到 info 字典中有这么几项:
- length 指的是整个文件的大小
- name 下载的文件名
- piece length 整数,BitTorrent 文件块大小
- pieces 字符串,连续存放所有块的 SHA1 值,每一个块的 SHA1 值长度都是 20,这里因为文件本身比较小所以只有一块
- private 整数,标记 torrent 是否私有
注:pieces 中有些特殊字符,在文章中用其他字符替换了。
多文件
多文件时 info 字典中会有一个 files 列表,这个列表由字典组成,每一个字典中是文件的内容,包括文件名和文件长度。
比如对当前文件夹下 README.md 和 README1.md 两个文件制作 torrent.
mktorrent -a http://announce.url -c "This is comments" -l 18 -o "test.torrent" -p -v .
得到的 torrent 文件:
d8:announce19:http://announce.url7:comment16:This is comments10:created by13:mktorrent 1.013:creation datei1585361538e4:infod5:filesld6:lengthi5e4:pathl9:README.mdeed6:lengthi0e4:pathl10:README1.mdeee4:name1:.12:piece lengthi262144e6:pieces20:rhr7r@rorrrlrrrrrrrr7:privatei1eee
拆解一下:
d
8:announce -> 19:http://announce.url
7:comment -> 16:This is comments
10:created by -> 13:mktorrent 1.0
13:creation date -> i1585361538e
4:info ->
d
5:files -> l
d
6:length -> i5e
4:path -> l 9:README.md e
e
d
6:length -> i0e
4:path -> l 10:README1.md e
e
e
4:name -> 1:.
12:piece length -> i262144e
6:pieces -> 20:rhrxxxxxxxxrrrrrr
7:private -> i1e
e
e
多文件时 info 字典中的内容稍微多一些。
- files 是多个文件的信息,其中包括了文件长度和路径。
相关库
构造好字典之后,使用如下库调用即可。
- PHP:sandfoxme/bencode、rchouinard/bencode、dsmithhayes/bencode、bhutanio/torrent-bencode
- Python:amyth/bencode、utdemir/bencoder、jcul/bencode、fuzeman/bencode.py
- Node.js: themasch/node-bencode、benjreinhart/bencode-js
客户端
可以对 torrent 文件进行编辑的客户端:
- Torrent File Editor Windows, macOS
- BEncode Editor
reference
在 Proxmox VE 上使用 qm 命令管理虚拟机
qm 是 [[Proxmox VE]] 系统上用来管理 Qemu/Kvm 虚拟机的命令。可以用这个命令来创建,销毁虚拟机,也可以用它来控制虚拟机的启动,暂停,继续和停止。另外也可以用 qm 命令来设定虚拟机的配置。qm 命令也可以用来创建和删除虚拟磁盘 (virtual disks).
Usage
使用已经上传到 local storage 的 iso 文件来在 local-lvm storage 上创建一个 4G IDE 的虚拟磁盘。
qm create 300 -ide0 local-lvm:4 -net0 e1000 -cdrom local:iso/proxmox-mailgateway_2.1.iso
启动 VM
qm start 300
发送一个停止请求,并等待 VM 停止:
qm shutdown 3000 && qm wait 300
等待 40 秒:
qm shutdown 3000 && qm wait 300 -timeout 40
Configuration
虚拟机的配置文件可以在 /etc/pve/qemu 文件找到。
配置文件都是纯文本,你可以用任何编辑器来编辑。不过建议用 qm 命令或者通过界面来进行修改。对配置的任何修改都需要重启 VM 才能生效。
如何根据自身情况选购硬盘
因为加入了一些 PT 的关系,本地的硬盘空间立即捉襟见肘,毕竟有些蓝光原盘动不动就 40+GB,所以陆陆续续给威联通也加了一些硬盘,之前一直买的是酷狼的 4T 盘,但是用了一年快两年的样子竟然挂了,这是我最初买的那一块所以也折腾了一下,因为系统和一些配置都在这一块盘上。所以强烈建议重要资料一定多处备份,不仅需要通过本地冗余备份,最好也多地备份,比如本地和其他云端备份服务实时同步。
再回到这次的主题,关于如何选购一块硬盘。打开京东能看到主流的硬盘厂商提供了种类丰富的各种用途的磁盘。但对于消费者而言,很多人其实并不知道其中的具体技术细节。很多人可能知道酷狼是 NAS 盘,酷鱼是普通家用盘,但谁也没有具体分析过这二者的区别,商家宣传也不会刻意宣传技术细节。
硬盘技术
硬盘的技术最早在 1956 年被 IBM 发明,之后便迅速成为了 60 年代通用计算机的组成部分 1。 历史上最多的时候有超过 200 家硬盘制造厂商 2,经过兼容合并后目前市场上比较著名的就只有 Seagate, Toshiba 和 Western Digital 了。再之后的故事大家都知道了,随着 SSD(Solid-state Drive) 的兴起,尤其是 NAND 技术的发展,HDD 逐渐式微,但不可否认的是 HDD 目前依然保留着自己在计算机领域的地位。
目前市场是两个主要的硬盘大小就是 3.5 寸,主要给台式机用,和 2.5 寸主要给笔记本用。HDD 通过 PATA(Parallel ATA), SATA(Serial ATA, 600MB/s), USB 和 SAS(Serial Attached SCSI, 12Gb/s) 接口和其他硬件系统连接。
主要构造
我们知道计算机的世界其实是一个二进制的世界,底层都是 0 和 1 的无尽组合,对于数据来说也是,那么作为二进制数据的存储设备硬盘而言,就是要记录下 0 和 1 的组合。在网上可以看到很多的硬盘拆解的图片,能看到一个大大的一个像 CD 一样的盘片,在盘片上会有很多磁性物质,通过盘片的快速旋转和磁头的移动来读写数据。但实际上可能要更加复杂一些。
硬盘的主要构造:

说明:
- Platter: 磁盘盘片,真正用来存储数据的地方,磁盘由非磁性材料制成,通常为铝合金、玻璃或陶瓷。它们被涂上一层浅浅的磁性材料,深度通常为 10-20 纳米,外层有一层碳保护层。盘片在硬盘正常工作时以非常高的速度旋转。
- HEAD: 磁头,盘片高速旋转时用来读取或者写入数据,磁头和盘片之间有一个纳米级别的空隙,所有的磁头连接在一个控制器上,控制器负责磁头的运动,磁头可以沿着盘片的半径方向(斜切向)运动。每一个磁头同一时刻必须是同轴的(也就是从上问下看磁头任何时候都是重叠的,一起移动)
- Spindle: 主轴
- Actuator: 读写臂,操作硬盘磁头在介质表面进行数据读写的组件,每一个记录磁头位于移动读写臂的尾端
- Actuator Arm: 磁头臂
- Actuator Axis: 磁头轴

上面也提到盘片是真正用来存储数据的地方,那么盘片是如何做到的呢?盘面和磁带的原理比较相似,在磁盘的表面有一层磁性材料,而磁头通常是线圈缠绕在磁芯上
- 在写入数据时,磁头线圈通电,周围产生磁场,电流的方向改变会引发磁场的变化,磁场会磁化磁盘表面的磁性物质。切换不同的磁场方向,磁性颗粒的方向也会不同。那么其方向的不同就可以来代表二进制世界的 0 和 1。
- 写数据时同理,磁头线圈切割磁感线产生了感应电流,磁性材料的磁场方向不同,电流方向也不同,磁头通过感应旋转的盘片上磁场的变化来读取数据
虽然原理很简单,但是盘片,磁头,以及机械内部的制作都是需要非常精密的工艺和材料的。
盘片
具体再看纵向每一个盘片之间。
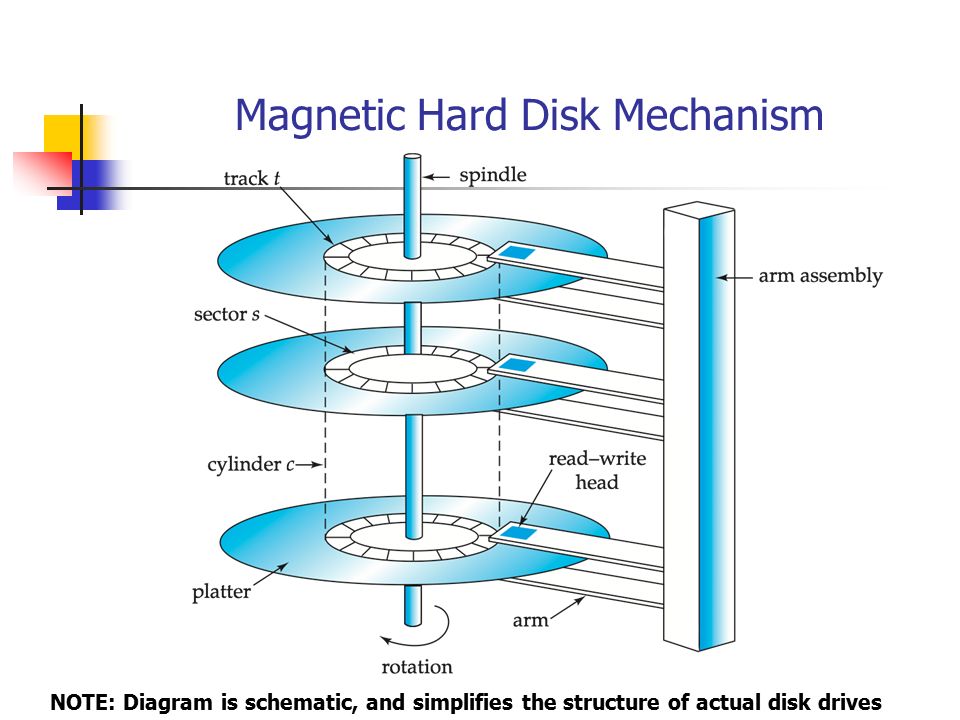
图片源自 Cameron Hart
说明:
所有的盘片都固定在主轴上,所有盘片之间都是平行的,每一个盘片的存储面都有一个磁头,现在主流的硬盘盘面都会有上下两面。
- Arm assembly 组合臂,控制磁头的机械结构
- track 磁道,盘片上的同心圆叫做磁道,磁道从外向里进行编号,从 0 开始,大容量的磁盘可能有更多的磁道。 磁头靠近主轴的最内圈,线速度最小,不存放任何数据,称为 Landing Zone。离主轴最远的就是 0 磁道,数据从最外圈开始存储。
- sector 扇区,每一段圆弧叫做扇区
- cylinder: 柱面,所有盘面上同一磁道构成的一个圆柱称为柱面,每个圆柱上的磁头从上到下,从 0 开始编号。数据的读写在柱面进行,磁头读写数据首先在同一柱面 0 磁头开始,依次向下在同一柱面不同的盘面的磁头上操作,同一柱面所有的磁头全部读写完后磁头才转移到下一个柱面。
操作系统以扇区的形式将信息存储在硬盘上,每个扇区包括 512 字节的数据和一些其他信息。每一个扇区有两个部分数据:
- 存储数据的地点标识符
- 存储数据的数据段,包括数据和数据校验 ECC 纠错码
扇区头标,包括:
- 盘面号(或者又叫做柱面号),在第几个盘面的位置;
- 柱面号(又被称为磁头号),用来确定磁头径向,在盘面中的位置;
- 扇区号,在磁道上的位置
这三个部分可以唯一确定一块数据的具体地址。
盘面区域
盘片盘面区域
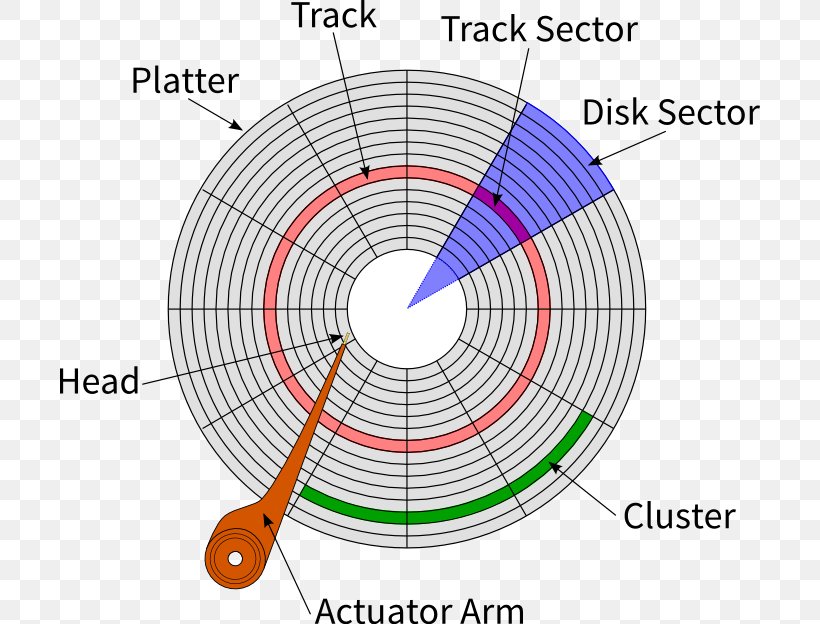
- Disk Sector 扇面
- Cluster 簇,物理相邻的几个扇区称为一个簇,操作系统读写磁盘的基本单位是扇区,但文件系统的基本单位是簇。簇的大小一般 4K, 8K ,16K,32K, 64K 等,簇越大存储性能越好,但空间浪费严重;簇越小性能相对越低,空间利用率高。
硬盘读写数据过程
在了解了硬盘的物理结构后,再来看真实过程中硬盘如何读写数据。
当系统需要从磁盘读取数据时,系统将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将地址翻译成物理地址,确定要读取的数据在哪一个盘面,哪一个磁道,哪一扇区。为了读写这个扇区的数据需要做以下步骤:
- 磁头沿着半径移动到要读取的扇区所在磁道上方,这段时间称为寻道时间 (Seek time),一般为 2~30ms,平均为 9ms 左右
- 磁头到达磁道后,通过盘片旋转使得要读取的扇区旋转到磁头下方,这段时间叫旋转延迟时间 (Rotational latencytime)
- 定位具体可读写的扇区后,如果是读数据,控制器计算此数据 ECC 码,然后将 ECC 码和磁盘记录的 ECC 码比较;如果是写数据,控制器计算此数据的 ECC 码与数据一起存储。
一个 7200 转 / 每分钟的硬盘,旋转一周所需时间 60*1000/7200 = 8.33ms,平均旋转延迟时间,假设为半圈也就是 4.17ms。平均寻道时间和平均旋转时间称为平均存取时间。
磁盘单次 IO 时间 = 寻道时间 + 旋转时间 + 存取时间
总结上面磁盘的读写可以知道数据的读写是按照从上到下,在盘面上从外向内进行。
局部性原理
因为硬盘的这种机械构造,所以磁盘本身的存取速度要比内存慢很多,再加上机械运动更加耗时。
预先读
所以为了提高硬盘的效率,减少磁盘 IO,磁盘往往不是严格的按需读取,而是每次都预先读取,即使只需要一个字节,磁盘也会从这个位置开始,顺序读取后面一定长度的数据放入内存。这样做的依据是计算机科学中著名的局部性原理,当一个数据被用到时,其附近的其他数据通常也会马上被用到。
页 (Page) 是许多计算机存储管理器的逻辑块,硬件和操作系统往往将主存和磁盘存储区域分割为连续的大小相等的块,每一个存储块称为一页(通常为 4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中,会产生一个缺页异常,系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
延迟写
一般硬盘上都会带一个比较小的磁盘缓冲存储器,将要写的数据缓冲,进而减少磁头移动,再一次性写入。
保护磁盘的方法
减小震动
硬盘内部因为是机械结构,在磁头和盘片之间有一个很小的空隙,如果硬盘有震动或者抖动,那么就可能造成磁盘数据损毁,所以在硬盘通电后就尽量不要移动硬盘,并且要尽量减缓硬盘转动可能带来的共振。
防尘
机械硬盘的内部构造必须保证觉得无尘,一旦有小的灰尘进入硬盘密封层,和磁头与盘片发生碰撞就可能造成机械设备的损坏。
使用 UPS 不间断电源
另外也不要对正在运行的磁盘突然断电,用正常的方式关闭系统,等待系统将缓存数据写回磁盘,然后再断电。所以如果家里有 NAS,建议还是购入 UPS,以免家中停电或者跳闸时可能对数据造成损害。
存储与分区
介绍了硬盘物理的构成,现在回到操作系统软件层面,相信装过机的人一定知道分区,在安装系统的时候要给系统划分一个系统分区。那么硬件启动的时候引导然后在硬盘上对应的地方启动系统。那么这里就需要知道整个磁盘的第一个扇区。
每一块物理硬盘的第一个扇区记录了整块磁盘的重要信息,包括:
- 主引导分区 (MBR, Master Boot Record),安装引导程序的地方,446bytes。系统开机时会去读取这个分区
- 分区表 (Partition Table),记录整块硬盘分区,64bytes
以前在使用 Windows 的时候有一个不小的疑惑,一块硬盘只能够划分四个分区(主分区 + 扩展分区),原因就在这里,分区表只有 64 bytes 大小,最多只能容纳四个分区。但实际上 Windows 可以通过逻辑分区来划分更多的分区。
PMR vs SMR
再上面说了那么多原理之后,假如硬盘厂商要提高硬盘的容量会怎么做呢?数据是存放在盘片上的,而具体数据是存在扇区上的。所以很自然的会想到:
- 增加盘片数量
- 增加磁盘面积
- 增加磁盘盘片上存储数据的密度
前两者会增加硬盘的体积和重量,而现在的硬盘标准是固定的,随意改变硬盘大小必然会引起问题。所以目前大部分的解决方案就是提高单个磁盘数据存储的密度。于是这个公司的硬件工程师就提出了各种各样的办法。
LMR
最早期磁性颗粒平铺在盘片上,磁感应的方向是水平的,这类技术被称为 LMR(Longitudinal magnetic recording, 水平磁性记录)。这种方式有一个缺点,盘片利用率不高,当磁力颗粒很小,相互靠近时,容易受到干扰,方向发生混乱。所以 LMR 时代,单盘存储的数据有限。
PMR
为了解决 LMR 容量的限制,工程师们又想出了让磁性颗粒和磁感应方向相对盘片垂直。这个就叫做 PMR(Perpendicular Magnetic Recordking, 垂直磁性记录)。
在 PMR 技术下,3.5 寸盘,单碟磁盘的容量可以达到 1TB 左右。
SMR
不过随着互联网发展人们要存储的东西越来越多,PMR 逐渐不够用了,所以硬件工程师又想出了 SMR(Shingled Magneting Recordking,叠瓦式磁记录技术)。
SMR 利用了磁道与磁道之间的距离,通常硬盘的磁道与磁道之间存在一个保护距离,保护不同磁道直接的磁性颗粒不造成干扰。另外一个现实情况便是,硬盘信息的读取和写入是两个不同的操作,读取磁头和写入磁头也是不一样的。现代硬盘读写的磁头不同,写入磁头是传统的磁感应磁头,比较宽,读取磁头是新型的 MR 磁头,比较窄,磁道在划分的时候,需要满足最宽的标准。但是写入磁头在工作的时候,实际上对于每一个磁道,写入的信息宽度和读取的宽度是一样的,那么,磁道的空间就造成了浪费。于是工程师想到,把这部分浪费的磁道重叠起来,和房屋的瓦片一样,写入的时候沿着每条磁道上方写入,中间留下一小段保护距离,然后接着写另一条磁道。
使用 SMR 技术的硬盘又被网友称为叠瓦盘。
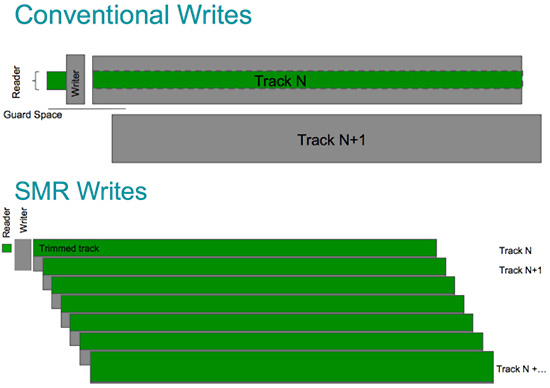
在 SMR 技术的帮助下,磁盘存储的容量大大增加了,但是缺点也很明显。首先是磁盘信息密度高,转速不能太快。另外 SMR 硬盘,单纯读问题不大,但是如果要修改某个磁道上的数据就比较麻烦,磁道间隙小,磁头比较宽,修改相邻磁道数据必然会相互影响。
解决这个问题的方法就是,每重叠一部分磁道时,隔开一些,另外就是设置专用缓冲区,当修改磁道 2 数据时,把磁道 3 的数据先取出来放到缓冲区,等磁道 2 数据改完再将磁道 3 数据写回。
也正是因为这个原因,一般的 SMR 硬盘具有大缓存的特点,一般可以达到 256MB,而普通的硬盘 64MB 足够。因为这样特殊的设计,在修改大量数据时会比较慢,时间久了会对硬盘读写性能造成影响。
总结
相较于 PMR 硬盘,SMR 硬盘不适合用来当作系统盘或者需要频繁读写的硬盘来使用
- 更适合当作仓储盘,用来备份数据
- 冷数据存储盘
NAS 盘与普通盘的区别
NAS 盘和普通盘的本质区别在于 Time Limited Error Recovery,TLER 技术(希捷叫 ERC,ErrorRecovery Control)3。
一块硬盘长时间运行过程中,可能会因为各种情况出现读写错误,并且运行时间越长,出现的可能性越大,但是出现错误后,硬盘不会因此而损坏,硬盘内部的控制器会尝试进行修复,转移,纠错等操作,这一过程根据修复的难度,会用时几秒到几百秒左右,在这期间,硬盘会处于一个停止响应的状态。
在 RAID 中,一旦发现一块硬盘在一定时间内无响应,就会认为硬盘损坏,剔除该硬盘。如果硬盘硬因为一个可恢复的读写错误进入无响应状态,而刚好这个硬盘处于一个 RAID 阵列,无响应时间一旦超过 8 秒的阈值,RAID 控制器自然会认为硬盘损坏,并开始一系列恢复操作。这时 TLER 就派上了用场,有 TLER 功能的硬盘将执行正常的错误恢复,但 7 秒后,会向 RAID 控制器发出错误消息,并将错误恢复任务推迟到稍后的时间。通过协调错误处理,硬盘驱动器不会从 RAID 阵列中删除,从而避免了整个 RAID 恢复、替换、重建和返回操作。也就是说有 TLER 功能的硬盘,在硬盘恢复期间,会每隔 7 秒向 raid 控制器报告一次”正常”从而阻止阵列的重建。
有 TLER 功能的 NAS 盘更加适合在 RAID 阵列中工作,TLER 不会减少读写时可能造成的错误,也不会加快错误恢复速度,但可以在纠错中保护未响应的硬盘不被 RAID 控制器因为超时而误判为硬盘损坏。
NAS 盘只有在 RAID 阵列中才能体现其价值。
总结
在看了硬盘的工作原理,再回到如何选购一块硬盘的主题上。相信到这里,再去看硬盘的配置信息,比如转速 5400 RPM,7200 RPM,缓存 64MB, 256MB ,使用的 PMR, 还是 SMR 技术,就比较清楚了,然后再根据自身的情况酌情选购即可。
reference
- 《Visual Inspection Technology in the Hard Disk Drive Industry》Paisarn Muneesawang && Suchart Yammen
- https://zhuanlan.zhihu.com/p/27926239
- https://blog.csdn.net/hguisu/article/details/7408047
- http://products.wdc.com/library/other/2579-001098.pdf
- https://www.ithome.com/0/436/608.htm
如何查找链到某个链接的页面
有的时候想要查看一个网页有多少其他的页面链接过来,这个搜索语法似乎在 Google 上没见过,平时用的比较多语法也就是用 site: 来查看某个站点中的关键字。
那有什么方法可以查看某一个页面有谁链接过来了呢?
Google Search Console
在 Google Search Console 中可以查看到:
Search Console > choose your property > Links > External links > Top linking sites
ahrefs
ahrefs 是一个逆向链接的索引,可以简单的查看一些,但如果要查看完整的报告则需要订阅。
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。