一键去除网易云音乐广告
前提条件
- Android 手机
- root 权限
- Root Explorer
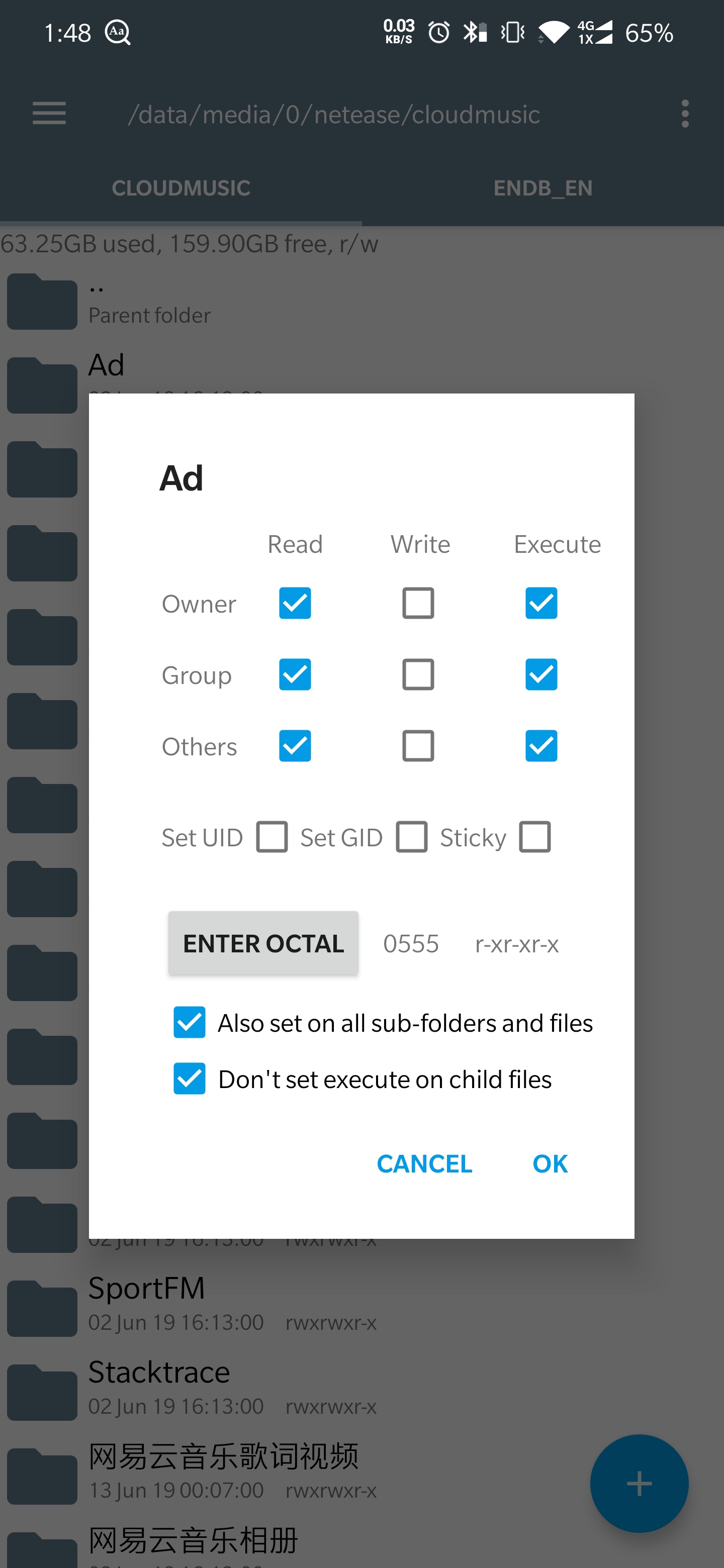
打开目录
/data/media/0/netease/cloudmusic/
看到 AD 目录,去除写入权限即可。
Root Explorer 如果打开的是 /sdcard 下面的目录可能无法设置权限。
Spring 自定义 namespace and handlers
自定义 namespaces 可以让用户有一种更方便的方式来定义 Bean。
Spring 提供了一些开箱及用的方式,比如 <mvc:annotation-driven/> 可以参考这篇文章 来查看该配置的作用。
Spring 从 2.0 开始可以支持自定义扩展 XML Schema。
XML Schema-based configuration
在了解自定义 XML Schema 之前首先要熟悉一下 Spring 的 XML Schema 配置。最简单的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- bean definitions here -->
</beans>
如果要引入 util schema 需要这样修改
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd"> <!-- bean definitions here -->
</beans>
扩展 XML
实现自己的 XML
- 创建 XML Schema 文件
xsd - 自定义处理器,实现
NamespaceHandler接口 - 自定义解析器,实现
BeanDefinitionParser接口,可多个 - 注册到 Spring 容器中
官方文档举了一个简单的例子,比如想要在 context 中定义
<myns:dateformat id="dateFormat"
pattern="yyyy-MM-dd HH:mm"
lenient="true"/>
这样的代码,那么需要做下面一些事情。
定义 XML
定义如下 dateformat.xsd
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.mycompany.com/schema/myns"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:beans="http://www.springframework.org/schema/beans"
targetNamespace="http://www.mycompany.com/schema/myns"
elementFormDefault="qualified"
attributeFormDefault="unqualified">
<xsd:import namespace="http://www.springframework.org/schema/beans"/>
<xsd:element name="dateformat">
<xsd:complexType>
<xsd:complexContent>
<xsd:extension base="beans:identifiedType">
<xsd:attribute name="lenient" type="xsd:boolean"/>
<xsd:attribute name="pattern" type="xsd:string" use="required"/>
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
</xsd:element>
</xsd:schema>
编写 NamespaceHandler
编写 NamespaceHandler 来处理特定 namespace 下的元素。NamespaceHandler 在这个例子中应该处理好 myns:dateformat 的解析工作。
NamespaceHandler 接口非常简单,有三个方法:
init()初始化 NamespaceHandlerBeanDefinition parse(Element, ParserContext)会被 Spring 在顶层元素处理时调用BeanDefinitionHolder decorate(Node, BeanDefinitionHolder, ParserContext)处理属性或者嵌套元素时使用
比如:
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
public class MyNamespaceHandler extends NamespaceHandlerSupport {
public void init() {
registerBeanDefinitionParser("dateformat", new SimpleDateFormatBeanDefinitionParser());
}
}
编写 BeanDefinitionParser
BeanDefinitionParser 会被 NamespaceHandler 内部使用,当解析特定的元素时会对应不同的解析器。比如这个例子中 dateformat 使用了 SimpleDateFormatBeanDefinitionParser 。
import org.springframework.beans.factory.support.BeanDefinitionBuilder;
import org.springframework.beans.factory.xml.AbstractSingleBeanDefinitionParser;
import org.springframework.util.StringUtils;
import org.w3c.dom.Element;
import java.text.SimpleDateFormat;
public class SimpleDateFormatBeanDefinitionParser extends AbstractSingleBeanDefinitionParser { 1
protected Class getBeanClass(Element element) {
return SimpleDateFormat.class; 2
}
protected void doParse(Element element, BeanDefinitionBuilder bean) {
// this will never be null since the schema explicitly requires that a value be supplied
String pattern = element.getAttribute("pattern");
bean.addConstructorArg(pattern);
// this however is an optional property
String lenient = element.getAttribute("lenient");
if (StringUtils.hasText(lenient)) {
bean.addPropertyValue("lenient", Boolean.valueOf(lenient));
}
}
}
Registering the handler and the schema
所有的编程都已经结束,剩下来的就是如何让 Spring XML 感知到所做的修改,将自定义内容注册到 Spring 中。
要实现这一点,需要考虑两点
- 注册自定义的 NamespaceHandler
- 注册 XSD 文件
在 resources 下创建 META-INF 目录,并创建如下两个文件
- spring.handlers 包含对应的 XML Schema URI 到 Handler 类的映射
- spring.schemas 包含 xsd 文件路径
META-INF/spring.handlers
定义 XML Schema 到 Handler 类映射,这个例子中
http\://www.mycompany.com/schema/myns=org.springframework.samples.xml.MyNamespaceHandler
META-INF/spring.schemas
定义 XML Schema 到自定义 XSD 文件映射
http\://www.mycompany.com/schema/myns/myns.xsd=org/springframework/samples/xml/myns.xsd
当做完这些后,那么上面定义的内容就和如下的定义可以实现完全相同的功能。
<bean id="dateFormat" class="java.text.SimpleDateFormat">
<constructor-arg value="yyyy-HH-dd HH:mm"/>
<property name="lenient" value="true"/>
</bean>
使用自定义 XML Schema
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:myns="http://www.mycompany.com/schema/myns"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.mycompany.com/schema/myns http://www.mycompany.com/schema/myns/myns.xsd">
<!-- as a top-level bean -->
<myns:dateformat id="defaultDateFormat" pattern="yyyy-MM-dd HH:mm" lenient="true"/>
<bean id="jobDetailTemplate" abstract="true">
<property name="dateFormat">
<!-- as an inner bean -->
<myns:dateformat pattern="HH:mm MM-dd-yyyy"/>
</property>
</bean>
</beans>
代码见 https://github.com/einverne/thrift-swift-demo/tree/master/spring-mvc-demo
reference
shell script idiom
Bash 命令中一些常见的习惯。
> file redirects stdout to file
1> file redirects **stdout** to file
2> file redirects **stderr** to file
&> file redirects stdout and stderr to file
/dev/null is the null device it takes any input you want and throws it away. It can be used to suppress any output.
Using 2>&1 will redirect stderr to whatever value is set to stdout (and 1>&2 will do the opposite).
MySQL 日期和时间函数
记住一些常用的时间操作函数能够提高 SQL 查询的效率。比如查询过去 30 天的记录,如果不清楚 DATE_SUB() 函数可能需要手动计算一下时间点再查询,但是如果知道 DATE_SUB() 函数就可以
SELECT something FROM tb_name WHERE DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= daet_col;
这个 SQL 同样会查找出来当前时间点未来的记录。
获取时间
获取当前时间
mysql> SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2019-07-01 09:12:46 |
+---------------------+
1 row in set (0.00 sec)
获取时间戳,同义于 NOW()
mysql> SELECT CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP;
+---------------------+---------------------+
| CURRENT_TIMESTAMP() | CURRENT_TIMESTAMP |
+---------------------+---------------------+
| 2019-07-01 09:13:13 | 2019-07-01 09:13:13 |
+---------------------+---------------------+
1 row in set (0.00 sec)
获取 UNIX 时间戳
mysql> select UNIX_TIMESTAMP(NOW());
+-----------------------+
| UNIX_TIMESTAMP(NOW()) |
+-----------------------+
| 1562571055 |
+-----------------------+
1 row in set (0.00 sec)
获取当前的时间 CURTIME(),结果为 hh:mm:ss 格式
mysql> SELECT CURTIME();
+-----------+
| CURTIME() |
+-----------+
| 09:13:53 |
+-----------+
1 row in set (0.01 sec)
或者
mysql> SELECT CURTIME() + 0;
+---------------+
| CURTIME() + 0 |
+---------------+
| 91525 |
+---------------+
1 row in set (0.02 sec)
计算时间
如果能查得当前时间,那么通过计算函数就能够非常快速的得到,比如过去一周,过去三十天的时间戳。
时间转换
从一个时间转换成另外一种表现方式
- 天数 <==> 日期
- UNIX 时间戳 <==> 日期
- 秒数 <==> 时间
TO_DAYS
传入日期,返回一个从第 0 年 ( ‘0000-00-00’) 开始到传入日期的天数
mysql> SELECT TO_DAYS('0000-01-01');
+-----------------------+
| to_days('0000-01-01') |
+-----------------------+
| 1 |
+-----------------------+
同理还有 TO_SECONDS(expr) 方法
FROM_DAYS
给定一个天数,返回日期。
相类似的方法还有 FROM_UNIXTIME(unix_timstamp),接受一个时间戳返回日期
时间到秒
TIME_TO_SEC(time) 传入时间返回秒数
mysql> SELECT TIME_TO_SEC('22:23:00');
-> 80580
mysql> SELECT TIME_TO_SEC('00:39:38');
-> 2378
同理从秒数到时间 SEC_TO_TIME(seconds)
时间日期计算
给日期增加或者减少,加减运算
时间间隔
增加时间
ADDDATE(date,INTERVAL expr unit), ADDDATE(expr,days)
DATE_ADD(date,INTERVAL expr unit), DATE_SUB(date,INTERVAL expr unit)
举例
mysql> select DATE_ADD(NOW(), INTERVAL 1 DAY);
mysql> select DATE_ADD(NOW(), INTERVAL 1 HOUR);
mysql> select DATE_ADD(NOW(), INTERVAL 1 MINUTE);
mysql> select DATE_ADD(NOW(), INTERVAL 1 SECOND);
mysql> select DATE_ADD(NOW(), INTERVAL 1 MICROSECOND);
mysql> select DATE_ADD(NOW(), INTERVAL 1 WEEK);
mysql> select DATE_ADD(NOW(), INTERVAL 1 MONTH);
mysql> select DATE_ADD(NOW(), INTERVAL 1 QUARTER);
mysql> select DATE_ADD(NOW(), INTERVAL 1 YEAR);
mysql> select DATE_ADD(NOW(), INTERVAL -1 YEAR);
同理减时间
SUBDATE(date,INTERVAL expr unit), SUBDATE(expr,days)
DATE_SUB(date,INTERVAL expr unit)
reference
Linux 下执行文件中的每一行
今天想要通过 adb 将盒子中的所有 apk 备份出来,很早之前写过的文章 就提到过如何手动的备份 apk 文件,不过这样很麻烦,需要每一条都手敲,所以想到了使用刚了解到的 xargs 命令,所以想通过几个命令将文件路径全部都拷贝出来,包名也拷贝出来。然后使用 xargs 来批量执行每一行命令。
通过这个拿到所有包名
adb shell pm list packages | cut -d: -f2 | tee pkg.txt
拿到所有文件路径
adb shell pm list packages | cut -d: -f2 | xargs -I {} adb shell pm path {} | tee path.txt
合并文件
paste -d" " path.txt pkg.txt | tee cmd.txt
然后添加
sed -e 's/^/adb pull /' -i cmd.txt
这样就得到了每一行都是一个 adb pull 命令的文件 cmd.txt
bash cmd.txt | bash
就能够快速的备份所有的 apk 文件了。
当然如果你熟悉 bash 可以非常快速的写出
for i in $(adb shell pm list packages | awk -F':' '{print $2}'); do adb pull "$(adb shell pm path $i | awk -F':' '{print $2}')"; mv base.apk $i.apk 2&> /dev/null ;done
reference
Intellij IDEA 中删除所有未使用的类
修改设置
- Press Ctrl+Shift+A
- Enter “unused declar”
- Double-click on “Unused declaration”
- Settings will pop up
设置
- Click on Java/Declaration redundancy/Unused declaration
- on the right bottom select “On the fly editor settings”
- untick check fields, …, check parameters. Only Check Classes should be ticked.
- Press OK
Settings closes
- On the menu bar, click on Analyze / Run Inspection by Name (or Ctrl+Alt+Shift+I)
- Insert text “Unused decla”
-
Select “Unused declaration Java Declaration redundancy” - Search starts
Check the job state on bottom of Idea, when finished: enjoy the results and the great feeling of cleaning up the messed code. :)
reference
Gitlab 中使用命令行提交 merge request
gitlab-cli 是一个用 Javascript 所写的工具,可以用来在命令行中提交 gitlab 的 merge request 等等,作者说收到 hub 工具的启发。
Installation
npm install git-lab-cli -g
Usage
查看帮助
lab -h
通过环境变量全局配置
GITLAB_URL=https://gitlab.yourcompany.com
GITLAB_TOKEN=abcdefghijskl-1230
TOKEN 可以在 https://gitlab.yourcompany.com/profile/account 这个地方找到。
一些常用的选项:
-a, --assignee "username"
-m "merge request message"
-r 标记合并之后删除远端分支
提交 Merge Request
首先将自己的分支 push 到 origin
git push -u origin feature_branch
lab -a "username" -m "Feature" -r
运行结束后会返回 Merge Request 的地址。
相关
每天学习一个命令:xargs 连接输出和输入
xargs 用来把一个命令的结果传递给另外一个命令执行。这是一个日常中经常会遇到的场景。
xargs 会从标准输入读取内容,然后将内容送给其他命令构建其他可执行命令。这意味着可以从一个命令行的输出结果读取内容并作为另一个命令的输入。
xargs 默认读取时按照空白字符分割的输入,输入可以带双引号,单引号,或者反斜杠转义,xargs 也可以读取新行,然后将输入作为参数执行对应的命令一次或者多次,默认是 /bin/echo。空白行输入会被忽略。
Unix 文件系统的文件可以包含空白和新行,这个默认的行为可能造成一些问题,包含空白的文件名可能被 xargs 错误读取。在这个情况下,最好是使用 -0 选项,在使用这个选项之前,同样要保证输出的结果同样是 null 字符分割的字符串,比如 GNU 下 find 命令的 -print0 选项。
如果任何调用产生 255 状态,xargs 会立即结束输入并给出错误。
使用
常用的选项
-o, --null 输入是 null 分割
-a file 从文件读取输入
-d delim 自定义分隔符
-E eof-str 自定义结束字符串
-I replace-str 使用自定义占位符
-t 在命令执行之前打印
-p 交互模式,每一次执行命令会进行确认
查找并删除
删除目录下特定 PATTERN 的文件:
find /tmp -name core -type f -print | xargs /bin/rm -f
find /tmp -name core -type f -print0 | xargs -0 /bin/rm -f # name 可以包含空白
# or not use xargs
find /tmp -depth -name core type f -delete
删除目录下除了固定格式的其他文件
find . -type f -not -name '*.gz' -print0 | xargs -0 -I {} rm -v {}
说明:
-I {}xargs 的-I {}属性会将后面命令中的内容替换为-I {}指定的内容
xargs 执行多个命令
通常情况下 xargs 只会在后面使用一个命令比如说 rm -v {} ,但如果想要在 xargs 后接多个命令则可以使用
< a.txt xargs -I {} sh -c 'echo {}; echo {};'
这样就可以执行多个命令。1
从文件读取
比如文件 links.txt 中每一行都是一个链接,那么可以使用该命令将所有链接下载下来
xargs -a links.txt -I {} wget {}
找出目录下的 png 图片并打包到一个压缩包
首先找出目录下的 png 图片路径,然后打包到一个文件
find /path/to -name "*.png" -type f -print0 | xargs -0 tar czvf photos.tar.gz
解释:
-print0的选项输出文件完整路径,然后紧跟一个空字符 (null), 而不是默认-print选项使用 newline ,该选项使得其他命令可以解析 find 命令的输出,比如xargs的-0选项- 同上一条
-0选项,表示的是输入的内容用null字符来分割,而不是使用空白字符,xargs 在使用该选项时会按照字面接受参数
将 ls 结果输出到一行
将 ls 结果输出到一行
ls -1 | xargs
说明:
ls -1注意这里是-1是数字的 1,不是英文的 L,会一行输出一个文件
自定义定界符
通常情况下 xargs 会使用空格或者空行来分割字符,这也就意味着如果文件名中包含空格,那么在处理时会遇到问题,所以可以使用 -d delim 来指定自己的定界符 (delimiter)。或者使用 xargs -0
输出当前系统中的账号
cut -d: -f1 < /etc/passwd | sort | xargs
说明:
-d:表示按照:分割-f1表示取第一个字段(第一列)
批量重命名
以前一直以为批量重命名得是一个非常高级的功能,在 GNU 下通过 xargs 和 rename 就可以快速实现
find -depth /path/to | xargs -n 1 rename -v 's/origin/after/' {} \;
该命令会把目录下所有文件统一成小写。
说明:
- rename 使用 perl 的正则
接受多个参数
通常情况下 xargs 只会接受一个参数作为命令的输入,如果有多个参数时,可以使用如下方法:
echo "one" "two" "three" | xargs -l sh -c 'echo $0, $1, $2' | xargs
批量替换标签
我一直使用纯文本(markdown)文件来记笔记,所以历史中存在很多没有好好管理的标签,比如有一些笔记使用了 # 加一些中文来标记,这部分内容我想进行管理,批量替换,结合 ripgrep 和 xargs,sed
rg "#要替换的标签" -l |xargs -I {} sed -i 's/#要替换的标签/#之后的标签/g' {}
并行执行命令
通过 xargs 的 man 可以知道
This manual page documents the GNU version of xargs. xargs reads items from the standard input, delimited by blanks (which can be protected with double or single quotes or a backslash) or newlines, and executes the command (default is /bin/echo) one or more times with any initial- arguments followed by items read from standard input. Blank lines on the standard input are ignored.
这意味这 xargs 会等待,并收集所有的输出之后再执行后面的命令。这并不是我们想要的,所以仔细研读 man 文档之后我们会发现 -n 选项和 -P 选项。
printf %s\\n {0..99} | xargs -n 1 -P 8 -I {} sh -c 'echo {}; sleep 2;'
说明:
-n选项会执行每一次命令最多拿多少个参数-P选项会同时开启多少个 processes 来执行命令
这样就能解读这行命令,打印从 0 到 99 这样 100 个数,每次开启 8 个进程,每个命令接受一个参数,执行后停顿 2 秒。看输出就能知道 8 个数同时打印, sleep 2 秒之后继续。这样就做到了并发执行。2
reference
一些 Tmux 使用小技巧
[[Tmux]] 是一个很强大的终端复用工具,下面是日常积累中记录的一些使用经验。
多 Pane 同步输入 Multiple Pane Synchronization
Tmux 一个非常著名的功能就是可以多个 Pane 同步输入,使用方式:
prefix- 输入
:setw synchronise-panes on - 然后在多个 Pane 中就开启了同步
同理配置 :set synchronise-panes off 就可以关闭
我在 ~/.tmux.conf 中配置了:
bind C-x setw synchronize-panes
配合 prefix + Ctrl-x 就可以快速切换多 Pane 同步。
Zooming tmux
tmux 1.8 引入了 Zoom 功能,支持一键最大化当前 Working Pane,使用 prefix + z 来放大,再次按下恢复。
Navigation between Tmux Pane and vim
在 Tmux 和 Vim 之间无缝切换。
更多内容可以参考我的 配置
结合 fzf
结合 fzf 的模糊查询,可以实现对 Tmux 会话的快速创建和搜寻,可以到 fzf 的 Wiki 页面具体查看。
Tmuxinator vs tmuxp
通常情况下创建一个 Tmux session 需要按很多个按键,假如有一个稍微复杂一点的项目,要开多个 Windows,第一个 Window 下开 3 个 Pane,那么每一次重启机器都要恢复这么多状态的话会非常累。有两种解决办法,一种就是在之前 Tmux Plugin 文中提到的 tmux-resurrect 插件。另一种就是使用配置文件,然后利用 Tmuxinator 或者 tmuxp 这两个工具来快速创建 Session。这两个工具可以通过读取配置文件,然后创建一个预设的 Tmux session。
Tmuxinator 是 Ruby 编写的,tmuxp 是 Python 所写,根据自己的环境选择即可。
reference
D-Bus 简单学习
D-Bus 是 Desktop Bus 缩写,是一个 inter-process communication(IPC) 和 remote procedure call (RPC) 机制,用来允许在同一台机器上进行进程间通信,它是 Linux 桌面环境中最重要的产物之一。它被越来越多地被用于应用程序间通信,也被用于应用程序和操作系统内核之间的通信。很多现代的服务进程都使用 D-Bus 取代套接字作为进程间通信机制,对外提供服务。
- 进程间通信
- 大部分 Linux 系统用它将系统事件(比如插入 USB 设备)通知给进程
D-Bus 作为 freedesktop.org 项目的一部分进行开发,由 Red Hat Havoc Pennington 起头,该标准被 Linux 上桌面平台 GNOME 和 KDE 采用。
D-Bus 将所有消息通过总线方式管理、分发,一般采用三层结构:
- libdbus 库,允许应用间通信
- 建立在 libdbus 上的消息守护进程,路由消息
- 封装库,libdbus-glib 或者 libdbus-qt 封装使用细节
D-Bus 的重点是一个叫做 dbus-daemon 的中央槽,需要对某些事件做出反应的进程,可以到 dbus-daemon 上注册,然后就能收到想要的事件通知。进程也可以创建事件,例如,udisks-daemon 进程从 ubus 监听硬盘事件,并发送到 dbus-deamon, 而 dbus-deamon 会把这些事件再转发给那些对硬盘事件感兴趣的应用。
D-Bus 在 Linux 系统中正变的越来越重要,并且从桌面系统中突破出来,systemd 和 Upstart 也同它来通信。但是,在核心系统中加入对桌面工具的依赖,有违 Linux 的设计宗旨。所以 dbus-daemon 进程被分成两类。
- 系统实例,开机时由 init 启动,并带有
--system选项,这个实例通常作为 D-Bus 用户运行,配置文件是/etc/dbus-1/system.conf一般不用修改,进程可以通过/var/run/dbus/system_bus_socket的 Unix 域套接字连接该实例 - 会话实例,和系统实例不同,会话实例只在打开桌面会话时才会运行,运行的桌面应用会连接这种实例
示例
D-Bus python 官方示例
Wiki
监视 D-Bus 消息
监视总线上的消息,监视系统实例:
dbus-monitor --system
可以看到系统实例上的消息,如果输出不多,可以尝试插入一个 USB 设备,再观察日志。
监视会话实例:
dbus-monitor --session
然后在不同的窗口点击,会看到不同的消息输出。
问题
运行在 Ubuntu 上经常遇到这样的问题
Failed to determine seats of user "1000": Too many open files)
目前找到的唯一方法就是重启。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。