OmniEdge 虚拟组网工具使用及原理简介
[[OmniEdge]] 是一个可以用来快速组建点对点私有网络的工具,也可以用来做内网穿透。
官方提供 Starter 套餐,可以供一个用户,最多创建 1 个虚拟网络,连接 20台设备。
2023 年更新
OmniEdge 已经停止运营。
安装
一键安装脚本:
curl https://omniedge.io/install/omniedge-install.sh | bash
Linux
curl https://omniedge.io/install/omniedge-install.sh | bash
omniedge login -u yourname@youremail.com
omniedge login -s yoursecuritykey
omniedge join -n 'virtual-network-id'
Run OmniEdge as a Service
在用 CLI 登录 OmniEdge 之后,推荐在后台运行。
创建 service:
vi /etc/systemd/system/omniedge.service
填入信息:
#/etc/systemd/system/omniedge.service
[Unit]
Description=omniedge process
After=network-online.target syslog.target nfw.target
Wants=network-online.target
[Service]
Type=simple
ExecStartPre=
#Replace to your real virtual network id(can be found by run omniedge join) and auth.json path
ExecStart=/usr/local/bin/omniedge join -n "your_virtual_network_id" -f your_auth_file_path
Restart=on-abnormal
RestartSec=5
[Install]
WantedBy=multi-user.target
Alias=
上面的配置中有两个地方需要修改一下:
- 一个是网络ID,可以通过命令
omniedge join获取,或者直接在管理后台获取 - 一个是
auth.json在登录成功之后会在/root/.omniedge/auth.json目录中
激活服务:
systemctl daemon-reload
systemctl enable omniedge.service
systemctl enable omniedge.service
为什么不使用 WireGuard
[[WireGuard]] 作为一个现代的 VPN 解决方案,简单,快速,并且易于维护,OmniEdge 官方的博客 也说过曾经尝试过使用 WireGuard,但是 WireGuard 存在的一个问题是,当构建一个具有庞大数量节点的网络的时候,管理和维护成本会成倍增加。
为什么不选择 n2n
[[n2n]] 1 是一个轻量、开源的用来组件点对点网络的工具,n2n 让 Super Node 处理节点的管理工作,这也就意味着这些节点可能需要处理大量流量,并且可能影响网络的性能。这使得 n2n 不适合构建一个完善的稳定的企业网络。
架构
OmniEdge 为了解决上面的问题,指定了一些基本的原则:
- 足够简单,对于用户和网络管理都要足够简单
- 基于 Zero-trust security model,用户可以通过类似于 Okta, G Suite 等等的验证工具来组件安全的网络
- 使用 Peer-to-peer 网络通信,提升网络速度,避免单点故障
基于上面的设计目标,收到 n2n 架构的影响,设计了如下的 OmniEdge 架构。
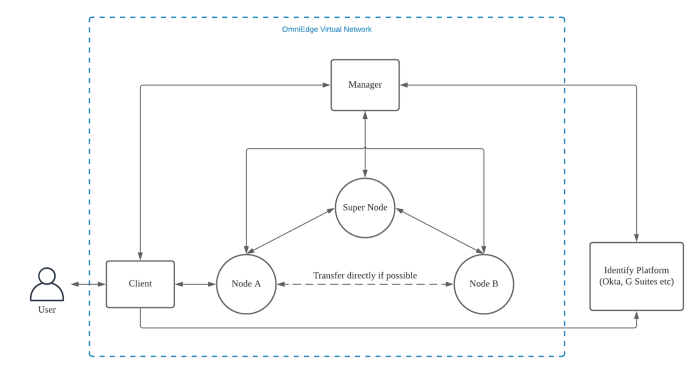
Super Node: 用来协调虚拟网络节点和节点之间的通信
- 协调节点和节点之间的网络通信
- 舱室在节点和节点之间建立直接连接;如果不行,则作为节点和节点通信的 relay 节点
Node: 虚拟网络中的具体的节点
- 保存、管理虚拟网络的信息,比如 keys, network node public keys 等等
- 在虚拟网络上直接或间接转发 TCP 和 UDP 流量
- 提供本地的 DNS 解析
Manager: 管理虚拟网络
- 管理网络节点数据,包括设备ID,公钥,IP 数据,网关,路由表等等其他信息
- 验证节点,返回网络信息给节点
- 管理网络的改变,比如节点加入,节点删除
- 管理节点的生命周期
- 和用户验证服务交互,管理 ACL 信息
Client: 这是用户用来管理虚拟网络的工具
- 和节点通信,配置管理节点
- 处理用户注册,登录流程
利用 supernode 加速
前两天看到 omniedge GitHub 发布了 supernode ,可以用来加速虚拟网络的网络状况。
有兴趣可以自行编译 Docker 镜像:
需要注意的是如果要使用 Sueprnode 必须使用 Pro 或者 Team 套餐。
reference
Linux 下 journal 日志清理
Linux 在运行的过程中会产生很多日志文件,一般存放在 /var/log 目录下,而其中 journal 目录中存放的是 journald daemon 程序生成的日志,其中包括了所有 kernel, initrd, services 等等产生的日志。这些日志在系统发生状况排查问题的时候非常有用。
jounrnald daemon 程序会收集系统运行的日志并存储到二进制文件中。为了查看这些二进制文件通常会使用到 journalctl 命令。但是默认情况下这些日志文件会占用磁盘空间的 10%,而大部分情况下这些日志文件是不需要查看的。所以可以配置减小一些 journal 日志的占用。
默认的日志文件保存在 /var/log/journal 下,可以使用 du 查看。不过我个人推荐使用可视化的 gdu 来 查看 。
du -sh /var/log/journal查看占用磁盘空间
查看 journal 日志占用大小
可以使用 journalctl 命令查看日志占用:
sudo journalctl --disk-usage
手动清理 journal 日志
如果要去清理 journal 日志,可以先执行 rotate 命令:
journalctl --rotate && \
systemctl restart systemd-journald
删除两天前的日志:
journalctl --vacuum-time=2days
删除两个礼拜前的日志:
journalctl --vacuum-time=2weeks
或者删除超出文件大小的日志:
journalctl --vacuum-size=20M
journalctl --disk-usage
# OR
du -sh /run/log/journal
journalctl --verify
ls -l /run/log/journal/*
systemctl status systemd-journald
修改配置文件限制 journal 日志最大占用
修改配置文件:
sudo vi /etc/systemd/journald.conf
修改其中的两项:
SystemMaxUse=100M
RuntimeMaxUse=100M
SystemMaxUse 设置 /var/log/journal
RuntimeMaxUse 设置 /run/log/journal
然后使设置生效:
sudo systemctl daemon-reload
journal 日志过大可能产生的问题
问题
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
原因是:
the disk usage of the log files for journald journal 日志空间达到了上限
Proxmox VE 备份和恢复虚拟机
数据是最重要的,本着系统可以挂,但是数据不能丢的原则,这里就整理一下在 Proxmox VE 系统中,直接备份虚拟机,和恢复虚拟机的过程。
为什么需要备份
- 保证数据的安全性
- 硬件故障
- 服务器升级或迁移
- 恶意软件破坏了系统
准备工作
设置备份存储
设置 Storage,允许保存 VZDump backup 文件:
- 转到 Datacenter > Storage。
- 选择备份存储位置。
- 单击编辑选项卡。
- 确保有一个 Storage 已经选择了 Content 下的 VZDump backup file
- 单击确定。
在执行备份之前,需要通过上面的设置设定一个允许备份的 Storage,然后之后的备份文件会存放到该 Storage 中。备份文件以文件形式存储。在大部分的情况下,可以使用 NFS 服务器作为存储备份。
Backup Modes
Proxmox VE 备份服务提供了三种不同的备份模式,在备份菜单中可以看到:
- stop mode,这个模式以短暂停止 VM 的代价提供了高一致性备份。这个模式会先关闭 VM,然后在后台执行 Qemu 进程来备份 VM 数据,一旦备份开始,如果之前 VM 在运行会继续 VM 的运行状态
- suspend mode,因兼容原因提供,在调用 snapshot mode 之前 suspend VM,因为 suspend VM 会导致较长时间的停机时间,所以建议使用 snapshot mode
- snapshot mode,不需要很长的停机时间,代价为可能的一小部分数据不一致,执行 Proxmox VE Live backup,当 VM 在运行的时候拷贝 data blocks
Back File Compression
对于备份的文件,Proxmox VE 提供了多种压缩算法,lzo, gzip, zstd。
目前来说,Zstandard(zstd) 是三种算法中最快的,多线程也是 zstd 优于 lzo 和 gzip 的地方。但 lzo 和 gzip 通常来说更加常用。可以安装 pigz 来无缝替换 gzip 以提供更好的性能。
使用了不同的压缩算法的备份文件的扩展名如下:
| file extension | algorithms |
|---|---|
| .zst | Zstandard(zstd) compression |
| .gz or .tgz | gzip compression |
| .lzo | .zo compression |
Backup
备份可以通过 GUI 或者 命令行工具来进行。
备份虚拟机
首先关闭虚拟机
CLI
通过命令行备份:
cd /var/lib/vz/dump
vzdump 101
说明:
- 以上的命令会在
/var/lib/vz/dump目录中备份 101 号虚拟机
GUI
通过 UI 界面备份数据:
- 数据中心> Backup。
- 转到 添加>创建备份作业。
- 选择详细信息,例如节点,目标存储,星期几,时间等。
- 确保备份作业已启用。
备份时跳过特定的目录
在备份虚拟机时有些时候不想要备份虚拟机中的特定目录,比如说缓存目录,这样可以加快备份的速度,以及减小备份文件的体积。
在 Datacenter -> Backup 中建立备份任务之后,会在系统中新建一个 cron,在 /etc/pve/vzdump.cron 文件中:
PATH="/usr/sbin:/usr/bin:/sbin:/bin"
15 2 * * 6 root vzdump 100 101 102 --mailnotification always --compress zstd --mode snapshot --quiet 1 --storage local --exclude-path /mnt/ --exclude-path '/dev/disk/by-id/ata-HGST*'
可以看到,实际使用了 vzdump 命令,直接在后面添加 --exclude-path 并加上不需要备份的目录即可。
更多的用法可以参考 vzdump 命令的使用。
备份时跳过 Disk
配置了备份之后查看日志可以看到:
INFO: Backup started at 2021-10-23 16:59:05
INFO: status = running
INFO: VM Name: ubuntu20.04
INFO: include disk 'scsi0' 'local:101/vm-101-disk-0.qcow2' 64G
INFO: include disk 'scsi1' '/dev/disk/by-id/ata-HGST_HUS726020ALA610_K5HWJ6NG' 1953514584K
INFO: include disk 'scsi2' '/dev/disk/by-id/ata-HGST_HUS726020ALA610_K5J0ZUWA' 1953514584K
INFO: include disk 'scsi3' '/dev/disk/by-id/ata-HGST_HUS726020ALA610_K5HW9RJG' 1953514584K
INFO: backup mode: snapshot
INFO: ionice priority: 7
INFO: creating vzdump archive '/var/lib/vz/dump/vzdump-qemu-101-2021_10_23-16_59_05.vma.zst'
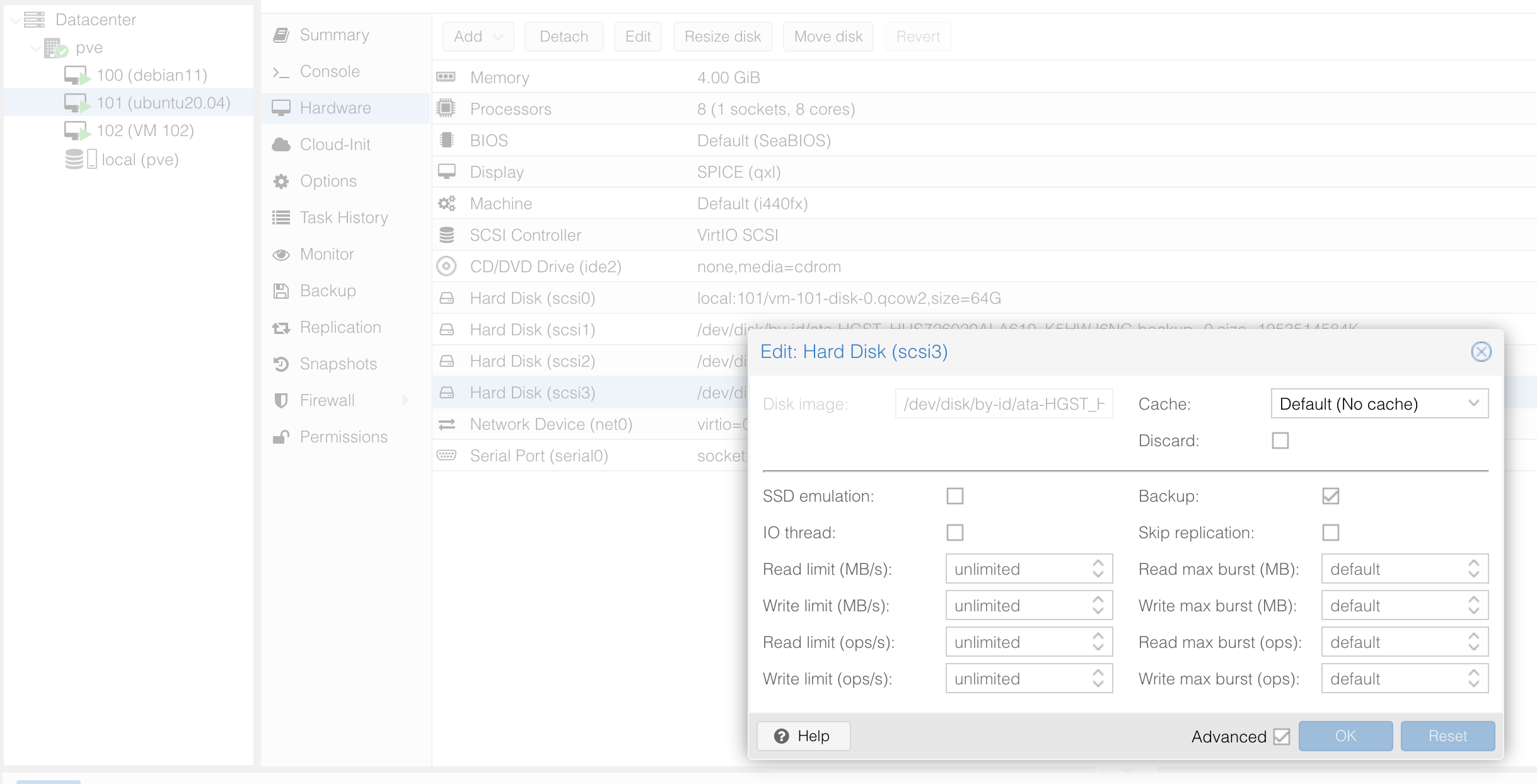
我的虚拟机挂载了三块硬盘,而备份的时候会包括这三块 2T 的硬盘,这是没有必要的,可以通过如下的方法跳过备份挂载而硬盘。
在虚拟机的设置中,点击 Hard Disk,在 Advance 高级选项中可以将 Backup 取消选中,然后保存,在备份的时候就不会保存该设备了。
定时清理过期的备份
随着虚拟机备份文件的增多,可以占用的本地文件会越来越多,所以定时清理必不可少。
在界面上设置
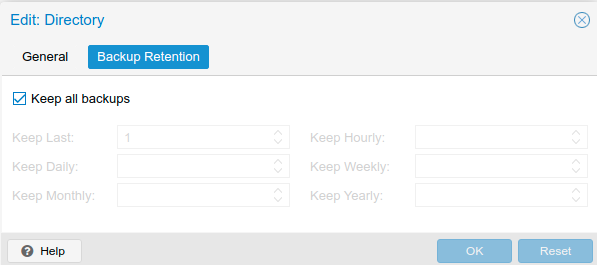
在 Datacenter -> Storage 在备份的 Storage 中双击进行设置,在 Backup Retention 中可以去掉勾选 Keep all backups 然后进行设置。
执行命令
crontab -e 然后编辑:
10 2 * * * find /var/lib/vz/dump/ -mtime +14 -delete
Restore
我们使用 qmrestore 命令从备份中还原 KVM VM 101。
pct restore 600 /mnt/backup/vzdump-lxc-777.tar
qmrestore vzdump-qemu-019-2018_10_14-15_13_31.vma 101
要从GUI还原VM,请执行以下步骤。
- 浏览到要移动的VM。
- 单击 Backup。
- 选择生成的备份文件,然后单击“还原”。
- 在 Restore 字段中,指定还原虚拟机的位置。
- 单击 restore 。
reference
Linux 虚拟化技术 OpenVZ KVM LXC 对比
介绍一下 Linux 下常见的虚拟化技术。
- OpenVZ
- KVM
- LXC
- Xen
OpenVZ
OpenVZ 是一种基于 Linux 内核的虚拟化技术,它允许在单个物理服务器上运行多个独立的 Linux 系统实例,每个实例都可以拥有自己的 IP 地址、文件系统、进程等。OpenVZ 使用容器技术实现虚拟化,相比于传统的虚拟机技术,它的性能更高、开销更小,因为它不需要模拟硬件,而是直接利用宿主机的资源。OpenVZ 还提供了一些管理工具,如 vzctl 和 vzlist,方便用户管理和监控容器。
OpenVZ(通常简写成 [[OVZ]]) 只能虚拟化 Linux 操作系统,但是 KVM 可以虚拟化 Linux,Windows,和其他操作系统。
OpenVZ 使用共享的 kernel,所有虚拟化 VPS 中的用户都使用同一个 kernel,因此 kernel 是不可自定义的。
一旦你使用的 RAM 达到了 host 分配的额度,那么剩下的 RAM 就是自由竞争的。如果你运行一些小型程序可能不是问题,但是一定你运行资源密集型程序就可能产生问题。
KVM
KVM 是 Kernel-based Virtual Machine 的缩写,是一个基于内核的虚拟化技术。借助 KVM 可以将 Linux 主机隔离成多个可以独立运行的虚拟环境,即虚拟机。
KVM 允许在单个物理服务器上运行多个独立的虚拟机,每个虚拟机都可以运行不同的操作系统。KVM 使用硬件辅助虚拟化技术,即 Intel VT 或 AMD-V,来提高虚拟机的性能和安全性。KVM 还提供了一些管理工具,如 virt-manager 和 virsh,方便用户管理和监控虚拟机。由于 KVM 是一种完全虚拟化技术,因此它可以运行几乎所有的操作系统,包括 Windows 和其他非 Linux 操作系统。
KVM 是 Linux 的一部分,Linux 2.6.20 版本及之后的版本包含了 KVM。KVM 在 2006 年首次公布,并且之后持续在更新和维护。
与 VMwareESX/ESXi、微软 Hyper-V 和 Xen 等虚拟化产品不同,KVM 的思想是在 Linux 内核的基础上添加虚拟机管理模块,重用 Linux 内核中已经完善的进程调度、内存管理、IO 管理等代码,使之成为一个可以支持运行虚拟机的 Hypervisor。因此,KVM 并不是一个完整的模拟器,而只是一个提供了虚拟化功能的内核插件,具体的模拟器工作需要借助 QEMU 来完成。
KVM 允许你设置使用资源的最小和最大值,这样虚拟化的系统就只能使用这些资源。并且在 KVM 下,RAM,CPU 和硬盘资源都是直接分配给用户,用户可以完全使用这些资源,而不用担心其他虚拟化机器的竞争。
KVM 提供了一个隔离的环境,用户可以自行替换 kernel。
QEMU
KVM 不是一个完整的虚拟机,而是借助 QEMU 来完成虚拟化过程。KVM 是 Linux kernel 的一个模块,通过命令 modprobe 去加载 KVM 模块。加载模块之后,才能通过其他工具创建虚拟机。仅有 KVM 模块不行,用户还需要开源的虚拟化软件 QEMU。
LXC
LXC,一般指 Linux Container,即内核容器技术的简称。LXC 将 Linux 进程沙盒化,使得进程之间相互隔离,并且能够控制各进程的资源分配。
LXC(Linux Containers)是一种基于 Linux 内核的容器化技术,它允许在单个物理服务器上运行多个独立的 Linux 系统实例,每个实例都可以拥有自己的文件系统、进程等,但它们共享宿主机的内核。LXC 使用轻量级的虚拟化技术,相比于传统的虚拟机技术,它的性能更高、开销更小,因为它不需要模拟硬件,而是直接利用宿主机的资源。LXC 还提供了一些管理工具,如 lxc-start 和 lxc-stop,方便用户管理和监控容器。LXC 可以用于构建轻量级的虚拟化环境,比如用于开发、测试、部署等场景。
Linux 容器项目(LXC)提供了一组工具、模板、库和语言绑定。LXC 采用简单的命令行界面,可改善容器启动时的用户体验。
LXC 提供了一个操作系统级的虚拟化环境,可在许多基于 Linux 的系统上安装。在 Linux 发行版中,可能会通过其软件包存储库来提供 LXC。
在 Linux 内核中,提供了 cgroups 功能,来达成资源的区隔化。它同时也提供了名称空间区隔化的功能,使应用程序看到的操作系统环境被区隔成独立区间,包括进程树,网络,用户 id,以及挂载的文件系统。但是 cgroups 并不一定需要引导任何虚拟机。
LXC 利用 cgroups 与名称空间的功能,提供应用软件一个独立的操作系统环境。LXC 不需要 Hypervisor 这个软件层,软件容器(Container)本身极为轻量化,提升了创建虚拟机的速度。软件 Docker 被用来管理 LXC 的环境。
Xen
Xen 最初是剑桥大学 Xensource 的开源项目,2003 年发布首个版本,2007 年 Xensource 被 Citrix 公司收购,开源 Xen 由 xen.org 继续维护。
Xen 是一种基于虚拟机监控器(Hypervisor)的虚拟化技术,它可以在一台物理服务器上运行多个独立的虚拟机,每个虚拟机都可以运行不同的操作系统。Xen 使用硬件辅助虚拟化技术,即 Intel VT 或 AMD-V,来提高虚拟机的性能和安全性。Xen 的虚拟机监控器可以直接访问物理硬件,而虚拟机则运行在虚拟化的环境中,因此可以获得接近于原生系统的性能。Xen 还提供了一些管理工具,如 xm 和 xl,方便用户管理和监控虚拟机。Xen 可以用于构建高性能、高可用性的虚拟化环境,比如用于云计算、虚拟桌面、数据库等场景。
我所购买的 servaRICA 就是 Xen 的虚拟化计数。
Xen 是运行在裸机上的虚拟化管理程序(HyperVisor)。
Xen 会在 Guest VM 边上运行着管理端 VM,Xen 称这个 VM 为 Dom0,虚拟机操作系统叫做 DomU。这个管理 VM 会负责管理整个硬件平台的所有输入输出设备,半虚拟化中 Hypervisor 不对 IO 设备做模拟,只对 CPU 和内存做模拟。
半虚拟化还有一个叫法:操作系统辅助虚拟化(OS Assisted Virtualization),这是因为 Guest VM 自身不带设备驱动,需要向“管理 VM”寻求帮助。这种虚拟化技术允许虚拟化操作系统感知到自己运行在 XEN HyperVisor 上而不是直接运行在硬件上,同时也可以识别出其他运行在相同环境中的虚拟机。
使用 Ansible Roles 结构化并复用 playbook
之前简单的了解过一下 Ansible,但没怎么具体使用起来,这两天因为要管理的机器多了起来,所以又把 Ansible 学了起来。这篇文章就主要了解一下 Ansible Roles 的使用。
之前的文章简单的知道在 Ansible 中可以使用 playbook 来组织一系列的任务。但如果要复用这些任务,并且更加模块化的花,那就离不开 Ansible Roles。
Role 用来解决的问题
之前的文章中也说过可以使用 playbook 来管理一系列的任务,但随着使用 playbook 就不可以免的膨胀,可能会出现上百行的 playbook,那为了复用和结构化地组织 playbook, Ansible 在 1.2 版本引入了 Roles 的概念。
- 层次化、结构化组织 playbook
- 复用任务
Roles
Ansible 中的 Roles 是 Ansible 的另一个重要的概念,通过 Roles 可以通过文件结构自动加载相关的 vars, files, tasks, handlers, 或者其他 Ansible 组件。这样说可能比较抽象,可以理解成通过在文件系统上的文件分类,可以自动让 Ansible Roles 去加载相关的内容。一旦通过 Roles 组织了内容就可以非常简单地复用和分享给其他人。
Role directory structure
Ansible Role 定义了一个目录结构,包括了8大类标准的结构,一个 Role 必须包含至少其中一个文件夹,其他没有使用的文件夹可以省略:
# playbooks
site.yml
webservers.yml
fooservers.yml
roles/
common/
tasks/
handlers/
library/
files/
templates/
vars/
defaults/
meta/
webservers/
tasks/
defaults/
meta/
默认情况下 Ansible 会自动寻找每一个目录下的 main.yml 文件(main.yaml 或者 main)。
tasks/main.yml,role 需要执行的主要任务handlers/main.yml,可能会被使用的 handlers,可以由该 role 使用,也可以被 role 之外的其他任务使用library/my_module.pymodulesdefaults/main.yml默认变量vars/main.ymlrole 的其他变量files/main.ymlfiles that the role deploys,role 需要使用的文件templates/main.ymltemplates that the role deploysmeta/main.ymlmetadata,角色依赖
Storing and finding roles
默认情况下 Ansible 会在下面两个位置寻找 Roles:
- 相对于 playbook 的目录
roles中 /etc/ansible/roles中
也可以通过 roles_path 的方式指定 Role 的位置。更多可以参考 Configuring Ansible。
在 ansible.cfg 中定义:
roles_path = /etc/ansible/roles:/usr/share/ansible/roles
或者也可以直接指定具体的 path:
---
- hosts: webservers
roles:
- role: '/path/to/my/roles/common'
使用 Roles
可以通过三种方式使用 Roles:
- 在 play 层级使用
roles选项,最常用的方式 - 在 tasks 级别使用
include_role,可以动态使用 - 在 tasks 级别使用
import_role,静态使用
Using roles at the play level
在 playbook 中,可以这样使用role:
- hosts: webserver
roles:
- common
- webserver
可以传递参数:
---
- hosts: webservers
roles:
- common
- role: foo_app_instance
vars:
dir: '/opt/a'
app_port: 5000
tags: typeA
- role: foo_app_instance
vars:
dir: '/opt/b'
app_port: 5001
tags: typeB
也可以向 roles 传递参数,例如:
- hosts: webserver
roles:
- common
- { role: foo_app_instance, dir:'/opt/a',port:5000}
- { role: foo_app_instance, dir:'/opt/b',port:5001}
甚至也可以条件式地使用roles,例如:
- hosts:webserver
roles:
- { role: some_role, when: "ansible_so_family == 'RedHat" }
Including roles: dynamic reuse
include_role 会按照定义的顺序执行,如果之前有定义其他的任务,会先执行其他任务。
---
- hosts: webservers
tasks:
- name: Print a message
ansible.builtin.debug:
msg: "this task runs before the example role"
- name: Include the example role
include_role:
name: example
- name: Print a message
ansible.builtin.debug:
msg: "this task runs after the example role"
Importing roles: static reuse
行为和上面的一样。
---
- hosts: webservers
tasks:
- name: Print a message
ansible.builtin.debug:
msg: "before we run our role"
- name: Import the example role
import_role:
name: example
- name: Print a message
ansible.builtin.debug:
msg: "after we ran our role"
使用 ansible-galaxy 创建 role
可以使用 ansible-galaxy role init role_name 来创建 role,这个命令会创建一个目录结构。
- 创建以roles命名的目录
- 在roles目录中分别创建以各角色命名的目录,如webserver等
- 在每个角色命名的目录中分别创建files、handlers、meta、tasks、templates和vars目录;用不到的目录可以创建为空目录,也可以不创建
使用 ansible-galaxy 创建的 role 会有一些初始化的设定,在 meta/main.yml 中可以看到基础的 galaxy_info 配置,包括了作者信息,协议等等。
role内各目录中可应用的文件
- task目录:至少应该包含一个为main.yml的文件,其定义了此角色的任务列表;此文件可以使用include包含其它的位于此目录中的task文件;
- file目录:存放由copy或script等模板块调用的文件;
- template目录:template模块会自动在此目录中寻找jinja2模板文件;
- handlers目录:此目录中应当包含一个main.yml文件,用于定义此角色用到的各handlers,在handler中使用include包含的其它的handlers文件也应该位于此目录中;
- vars目录:应当包含一个main.yml文件,用于定义此角色用到的变量
- meta目录:应当包含一个main.yml文件,用于定义此角色的特殊设定及其依赖关系;ansible1.3及其以后的版本才支持;
- default目录:应当包含一个main.yml文件,用于为当前角色设定默认变量时使用此目录;
通过 ansible-galaxy 认识 Roles
ansible-galaxy list # 列出已经安装的galaxy
ansible-galaxy install geerlingguy.redis # 安装一个galaxy role
ansible-galaxy remove geerlingguy.redis # 删除一个galaxy role
reference
如何发现 CPU steal 并解决
什么是 CPU 窃取
CPU 窃取(CPU steal)指的是一个虚拟 CPU 核心必须等待物理 CPU 的时间百分比。通常 CPU 窃取发生在共享主机上,简短地来说就说当共享主机去处理一个请求时发生延迟。这种情况通常会发生在资源争夺的时候,当处理 CPU 密集型任务时。
为什么会发生 CPU 窃取
在共享主机、或云主机中,虚拟机管理程序会安装在物理硬件和虚拟机化化境之间,然后将 CPU 时间、内存等等资源分配给虚拟机。
当进程准备好由虚拟 CPU 执行时,等待管理程序分配物理 CPU,而如果管理程序将此 CPU 已经分配给了另一个虚拟机时,就会发生等待。
CPU 窃取时间长的原因:
- 虚拟机进程计算任务繁重,分配的 CPU 周期不足以处理工作负载
- 物理服务器被虚拟机超载,云服务器提供商超额出售了虚拟机,使得物理 CPU 无法处理进程
当发生请求处理缓慢时如何查看 CPU streal
当检测到共享主机性能无故受到影响时,怀疑可能出现 CPU steal。最好的排查方法就是使用 iostat 命令。
iostat 1 10
for x in `seq 1 1 30`; do ps -eo state,pid,cmd | grep "^D"; echo "-"; sleep 2; done
top -bn 1 | head -15
拆分开每一行命令进行解释:
iostat 1 10
每隔 1s 执行一次 iostat 命令,一共执行 10 次。
其结果可能是这样的:
avg-cpu: %user %nice %system %iowait %steal %idle
5.29 2.12 12.17 46.03 0.53 33.86
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 1.00 4.00 0.00 0.00 4 0 0
dm-1 19.00 760.00 6144.00 0.00 760 6144 0
loop0 0.00 0.00 0.00 0.00 0 0 0
loop1 0.00 0.00 0.00 0.00 0 0 0
loop2 0.00 0.00 0.00 0.00 0 0 0
loop3 0.00 0.00 0.00 0.00 0 0 0
loop4 0.00 0.00 0.00 0.00 0 0 0
loop5 0.00 0.00 0.00 0.00 0 0 0
loop6 0.00 0.00 0.00 0.00 0 0 0
loop7 0.00 0.00 0.00 0.00 0 0 0
loop8 0.00 0.00 0.00 0.00 0 0 0
loop9 0.00 0.00 0.00 0.00 0 0 0
xvda 34.00 1412.00 0.00 0.00 1412 0 0
xvdb 30.00 1124.00 0.00 0.00 1124 0 0
xvdc 161.00 964.00 5440.00 0.00 964 5440 0
从结果上来看,上面的结果只有一点儿的 CPU steal,来看看一个存在 CPU steal 的结果。
avg-cpu: %user %nice %system %iowait %steal %idle
0.39 0.00 12.74 0.00 37.84 49.03
注意到 %steal 值,这么高的值则表示正在发生 CPU steal。一般来说这个值低于 15% 算是比较正常,如果一直比较偏高则需要 open a ticket 给虚拟机提供商请求调查了。
for x in `seq 1 1 30`; do ps -eo state,pid,cmd | grep "^D"; echo "-"; sleep 2; done
这一行命令则是检查状态在 D 状态的进程,D 状态意味着进程在 uninterruptible sleep,这一行命令每隔 1s 执行一次,执行 30 次。
正常的结果应该是只输出 - 行。而如果输出的结果中包含 D 状态的进程:
# for x in `seq 1 1 30`; do ps -eo state,pid,cmd | grep "^D"; echo "-"; sleep 2; done
-
D 2169 [jbd2/sda-8]
-
D 2169 [jbd2/sda-8]
-
D 2169 [jbd2/sda-8]
这意味着特定的进程在 uninterruptible sleep。调查该特定的进程,查看是否因为其他的,比如 IO 等待而造成系统卡顿。
D 状态进程通常在等待 IO,但这也常常意味着会发生 CPU steal,所有的系统资源都会被绑定到 D 状态的进程上,导致系统无法处理其他任务。
D 状态的进程无法被通常的方法 kill,因此一个完整的系统重启才可能清除掉此类进程。另一个方法就是等待 IO ,直到进程自己解决问题。但缺点也是在整个等待 IO 的过程中会持续造成系统问题。
top -bn 1 | head -15
top 命令是用来监控系统进程资源使用情况的命令,上面的命令则是打印资源使用最多的 15 个进程。
注意:超出 100% 使用率的进程不是问题,一个 8 CPU 核心的虚拟机可能会有 800% 的 CPU 使用率
在查看 top 的结果时,如果 top 命令结果中有占用 CPU 异常的进程,可以进行相关的处理。
mpstat
另外一个查看的命令是 mpstat
mpstat -P ALL 1 10
每隔 1s 时间打印一次,在结果中可以查看 %steal 的数值。
sar
在 sysstat 包中的 sar 命令也可以查看 steal 情况。
reference
自行搭建 ZeroTier Network Controller 组件虚拟局域网
之前的一篇文章简单的通过内网穿透,异地组网的概念介绍过 ZeroTier,过去几年里面几台设备也一直陆陆续续地在使用着,虽然中间也短暂切换成 frp,也尝试过 [[Tailscale]],但 ZeroTier 一直是候选方案中排名在前的。
ZeroTier 官方默认免费的方案可以支持最多 50 台设备的连接,我陆陆续续也用不超过 20 台。所以使用官方提供的基本服务是丝毫没有任何问题的。但就是本着折腾的态度,也是学习一下 ZeroTier network controller 相关的内容,记录一下如何自建 ZeroTier network controller。
概念介绍
ZeroTier
ZeroTier 是一个虚拟组网工具,他可以让设备和设备之间通过互联网的帮助,就像是在局域网(LAN)之间通信一样。通过 安装 ZeroTier One 客户端,并加入一个 16 位数字的 ZeroTier 网络就能实现。
ZeroTier network controller
ZeroTier 网络是通过 ZeroTier network controller 来完成配置的。用户既可以使用 ZeroTier 官方 提供的 network controller,也可以使用自己搭建的独立网络控制器(standalone network controller)。
如何设置自己独立的网络控制器就是这篇文章的重点。
ztncui
ztncui 是一个开源的 ZeroTier 网络控制中心的用户界面。
代码地址:https://github.com/key-networks/ztncui
ZeroTier 网络实现原理
ZeroTier 的网络 Controller 是一个控制节点,该节点会通过 roots (根节点)来发现彼此。可以和 DNS 根服务器类比。
ZeroTier 的 Network ID 由两部分组成:节点 ID + 其他字符。
每一个 ZeroTier 节点(Nodes)会通过 Network ID 的前 10 位来发现 network controller,然后通过 networking controller 来发现局域网中的其他节点。
然后每一个节点可以通过 zerotier-cli peers 来查看匹配网络中的节点。
如果 network controller 离线了,那些已经建立连接的节点会保持连线,但是无法再往网络中添加新的节点。
如何搭建独立的 ZeroTier 网络控制器
上文提及的 ztncui 就是一个开源的 ZeroTier 网络控制器界面,通过他可以快速搭建自己的 ZeroTier 网络控制器,这里我们使用 Docker 镜像快速搭建。如果需要手工搭建,可以直接参考官网。
本文使用的镜像是:
这里直接贴出 docker-compose.yml 文件:
version: '3.3'
services:
ztncui:
container_name: ztncui
image: keynetworks/ztncui
restart: always
volumes:
- ~/ztncui/ztncui:/opt/key-networks/ztncui/etc
- ~/ztncui/zt1:/var/lib/zerotier-one
environment:
- NODE_ENV=${NODE_ENV}
- HTTP_PORT=${HTTP_PORT}
- HTTP_ALL_INTERFACES=yes
- ZTNCUI_PASSWD=${ZTNCUI_PASSWORD}
- MYADDR=${MYADDR}
ports:
- '3443:3443'
- '3180:3180'
说明:
HTTP_PORT:后台端口ZTNCUI_PASSWD:后台默认密码MYADDR: VPS 的网络地址,公网 IP 地址
然后在同级目录新建文件 .env:
# more https://github.com/key-networks/ztncui-aio
NODE_ENV=production
HTTP_PORT=3443
ZTNCUI_PASSWD=
MYADDR=your.ip
后续更新会在 dockerfile。
然后使用 docker-compose up -d 启动。
启动之后可以访问 IP:3443 可以访问管理后台。
独立网络控制器的优劣
优点
自建 ZeroTier network controller 可以提升节点建立连接的稳定性,同时也解除了官网的设备连接数限制。
但 network controller 自身并不能提升节点和节点之间的连接速度。
缺点
一旦使用了自建的 ZeroTier 网络,便需要一定精力去维护 network controller 的稳定性。
并且如果 network controller 挂掉可能无法再新增加节点。不过新增节点的操作也不是高频操作,对我个人使用而言问题不大。
外延
除了 ztncui 这一个用户界面,还有一些在逐渐发展的,可以根据自己需要挑选:
- thedunston/bash_cli_zt - Command Line interface for self-hosted ZeroTier.
- dec0dOS/zero-ui - GUI for self-hosted ZeroTier.
- mdplusplus/zerotier-network-controller-ui - Docker image for self-hosted ZeroTier.
reference
-
[[2018-06-14-zerotier 使用 Zerotier 组建虚拟局域网实现内网穿透]] - https://docs.zerotier.com/self-hosting/network-controllers/
- https://blog.ogarcia.me/zerotier/
- ZeroTier Self-hosting ZeroTier Network Controllers 官网文档
- https://github.com/zerotier/awesome-zerotier#self-hosting
- https://github.com/key-networks/ztncui-containerized
究竟什么是「内卷」
过去的这一年里,不断的有人在我耳边说起一个词「内卷」,但是我让说这个词的人解释一下自己所说的这个词的含义,却没有人能够用一句话解释清楚这个词。所以在我的笔记中就一直留着这一个词条,让我不断的去思考「内卷」一词的含义。一般来说,我在没有弄明白某一个概念之前,不会在日常生活中反复的去使用。但周围反复在用的人实在太多了,所以整理一下过去我听到的,以及看到的。
内卷的几个表达场景
我周围的人通常在这几个场景中会用到「内卷」这个词:
- 在大多数的语境中,我们会说互联网行业的竞争,以及在这个竞争下的程序员为主体的人形成了内卷的趋势,表现形式就是加班越来越严重
- 我也听到有人形容《鱿鱼游戏》说是反应韩国的内卷
- 同样在学习,比如高考的竞争中也有「内卷」的趋势
但究竟什么是内卷,如果是恶性竞争,那么我们为什么要发明一个词来表达重复的含义?
什么是内卷
那接下来我们就从最原本的含义来探究一下「内卷」。
字典上的定义
内卷对应的英文单词是 involution。involution 在 American Heritage English 上的解释:
- the state of being involved 被卷入的状态
- intricacy, 复杂性,复杂化的状态和过程
- 在医学上:
- A decrease in size of an organ, as of the uterus following childbirth.(器官在大小上的萎缩,例如生育之后女性子宫的萎缩。)
- A progressive decline or degeneration of normal physiological functioning occurring as a result of the aging process.(因年龄增长而出现的身体正常功能的持续衰退或退化。)
- 在植物学上:
- Having the margins rolled inward,边缘内卷,形容植物枝叶内卷的特性
英文单词 involution 有内卷,退化的含义。
哲学定义
在哲学领域,内卷化一词最早被提及是 18 世纪德国哲学家 [[康德]] 的《批判力批判》,康德将 involution 和 Entwicklung(演化)进行了区分。
他在《批判力批判》中将「内卷化」定义成与「演化」相对的概念,「演化」形容事物从无到有、从低级到高级的发展过程,而「内卷化」则指的是事物在原有的基础之上,不断向内发展,不断复杂化的过程,这个过程中,并没有新事物诞生。1
人类学家定义
美国人类学家 Goldennweiser(Alexander Aleksandrovich Goldenweiser) 将内卷化定义成在某一个状态下,无法稳定,也无法转变为新的状态,只能不断内部运动,变得复杂的文化模式。2
农业领域
美国人类学家 Clifford Geertz ,在《农业内卷化——印度尼西亚的生态变化过程》(Agricultural Involution: The Processes of Ecological Change in Indonesia)中,借用 Goldenweiser 内卷化的概念研究爪哇岛的水稻农业,提出了 agricultural involution(农业化内卷)的概念。他认为水稻种植造成了社会复杂性,但没有促成技术或政治的变革,这个过程被他称为「内卷化」,Geertz 的使用,使得「内卷化」一词在人类学家和社会学家之间广为流传。
Geertz 在书中提到,1830 年以后爪哇受到了两方面的限制:
- 增长的人口压力
- 阻碍本地经济作物种植和商业部门发展的帝国主义
面对土地短缺采用了共同分担贫穷的模式,引起工业变革的失败3。
国内学者的研究
而在国内对「内卷」一词的引用则是在黄宗智的《长江三角洲小农家庭与乡村发展》中,作者把内卷化这一概念用于中国经济发展与社会变迁的研究,他把通过在有限的土地上投入大量的劳动力来获得总产量增长的方式,即边际效益递减的方式,将一种没有发展的增长称为「内卷化」。
内卷化含义的扩大
但是在「内卷化」一词进入公众领域之后,其含义发生了巨大变化,在网络上,随着传播,内卷一词的语义发生了偏差。人们往往用其来指代恶性竞争、过度竞争,底层淘汰等现象。
内卷和形式主义的关系
形式主义是严格意义上的内卷,即通过做没有实际意义的事情对有限资源进行零和博弈,形式主义的唯一产出是上位者的情绪价值。所以,反对形式主义的本质是减少上位者获得的情绪价值。这就是为什么反对形式主义很难。

总结
总结上面的这些定义,尽管在哲学、社会学等等不同领域中,不同学者都对内卷化展开了研究,但是对内卷化都有各自不同的定义,这些定义不尽相同,目前也没有一个统一的定义。
但是能看到一些统一性的地方:
- 复杂化,相同的一件事情不断发展越来越复杂
- 不断发展,却不会产生新的事物、思想
对于社会整体而言,内卷是一个停滞不前,无法转变的状态,虽然看着再不断发展,但是无法产生新的事物。而对于社会中的个体而言,内卷则使得个体投入更多,但却收获相同的结果,在边际效应上退化,对个体而言不管如何努力、改变都无法促进变革。
造成内卷的原因
信息不对称
在这里我无法再进一步探究内卷的原因,我也无法得知为什么整个社会会掉进这样的陷阱,我知道只有当市场上的人能够充分的去发明新的事物,能够自由的表达自己的观点,即使这个事物的发明可能带来灾难,即使这个观点可能是错误的,但只有这样的自由,才能不让社会陷入一潭死水,只有自由的讨论才能使得真理在辩论中脱颖而出。在信息公开透明、可以自由交流的社会中,信息的流动会弥补信息的不对称,从而使得社会中的个体能够根据自己所获得的信息做出决策,从而提高生产效率,从而发展出新的理论。就像[[密尔]]在[[论自由]]一书中所说,迫使意见不能被表达这是对整个人类的掠夺。
内卷化的误读
在我们日常生活中所讨论的内卷一词早已超出了其原本的含义,甚至在某一些地方的使用是错误的,只掩盖了原来的一些问题。很多人所说的「内卷」,其实并不是「内卷」。
就像之前看到的豆瓣短文:
有人将职场学历要求越来越高视为内卷。事实上,这并不是内卷。例如一个工程师、银行经理的招聘要求从本科到硕士,从硕士到名校硕士,这其实是社会对岗位人才的要求越来越高,而不是内卷。 一个单位加班越来越严重,只要加班是有效的,这也不叫内卷,这属于劳动剥削。 将资本、风投偏爱低技术含量产业(例如共享单车、社区团购、滴滴这种的),而非原研药、精密机床、机器人这些高技术产业视为内卷。其实这也不是内卷。热钱真正偏爱的,是收益周期短的服务行业,“共享经济”、滴滴、美团、拼多多、游戏产业……这些看上去是互联网科技产业,其实它们是互联网加持的服务业,它们提供的是交通、配送、游戏娱乐、餐饮、购物等等服务。资本热钱真正偏爱的收益周期短、好讲故事的服务业。而这些生活服务产业又都是大众化服务,所以我们经常会在媒体宣传上、身边生活中看到这些服务产品(例如共享单车、美团骑手、游戏广告等),于是就会形成了资本只喜欢这种产业的错觉。实际上,高技术产业——造精密机床、造飞机、造机器人……这些技术产业都有它们自己的体系,只是它们离我们的生活较远,我们不太了解而已。所以这也算不上内卷。这属于是风投资本倾向于收益周期短、曝光率较高的服务业。如果真要靠投资共享单车那点钱去研究飞机、造芯片,那国家怎么可能发展呢?高科技企业自有其发展的政策、金融、市场体系。 将所有的加班都视为「内卷」这实际上掩盖了劳动法保障不健全的问题。假如劳动法保障够刚性,当暗示加班成为一种人人鄙视的违法行为时,加班生态是绝对可以好转的。而乱用内卷概念,则会把责任归于员工身上,反而忽略了法律制度、企业的问题,这就掩盖了真实的问题所在。
正确的使用「内卷」一词,才能让我们有针对性的解决问题,而不是像现在这样任其随意被滥用,从而掩盖真正能够被解决的问题。
related
- [[躺平]]
reference
-
康德.判断力批判·第 2 版[M].北京:人民出版社,2002. ↩
-
McGee, R. Jon; Warms, Richard L. Critical Contributions to Anthropology. Theory in Social and Cultural Anthropology: An Encyclopedia. SAGE Publications. 2013-08-28. ISBN 9781506314617 ↩
-
Cohen, Jeffrey H.; Dannhaeuser, Norbert. Involution and modernisation. Economic Development: An Anthropological Approach. Rowman Altamira. 2002-04-23. ISBN 9780759116696 ↩
zinit 作者删库事件以及后续代替方案
前两天在新机器上使用我的 dotfiles 配置的时候,本来会自动安装 zinit,并进行一些初始化配置,但突然发现卡在了 zinit 配置拉取的过程中,还以为 GitHub 权限配置的问题,但仔细看了一下发现作者把整个仓库,以及个人页面都给删除了。 https://github.com/zdharma/zinit 这个仓库显示 404,我还以为产生了错觉,因为刚刚从 Google 点击跳转过来,Google 的结果还在,但自己一搜就发现原来真的是作者本人把仓库删除了。
所以也没有办法,除了我本地的一份缓存,最近一次提交还是 6 月份,所以只能搜索一下看看还有没有人有最新的备份,然后就看到了 GitHub 上之前贡献者新建的社区维护的仓库。把我 dotfiles 中的地址替换成该仓库目前暂时没有遇到任何问题。
另外要注意如果用到了如下的插件也要响应地替换:
zdharma/zinit -> zdharma-continuum/zinit
zdharma/fast-syntax-highlighting -> zdharma-continuum/fast-syntax-highlighting
zdharma/history-search-multi-word -> zdharma-continuum/history-search-multi-word
我个人也备份了一份代码 https://github.com/einverne/zinit 有兴趣可以看看。
不过我个人还是建议切换到社区维护的版本上。
一点感想
我不对作者的行为做任何评价,因为我并不清楚发生了什么,但是无疑这种删库的行为已经伤害了曾经的使用者,以及曾经贡献过代码的开发者。代码容易恢复,当作者仓库的 wiki 内容已经只能从 Google Cache 中恢复了,这无疑会对使用者造成一些困扰。
从这件事情延伸到生活中,以及这两天刚刚发生的 [[Notability]] 买断制更改为订阅模式造成的恶劣舆论影响,让我不经去思考,在如今这样的严重依赖数字化的生活中保持安定。在过去的经历中,已经让我渐渐地养成习惯,尽量去使用[[自由软件]](能够获取源码),尽量去使用跨平台能导出可使用数据的软件(比如 Obsidian 即使再用不了,我还可以用任何编辑器去编辑我的笔记),如果有离线可用的,绝不用在线服务(Obsidian 相较于 Notion,Notion 开始就不在我的备选方案)。虽然已经这样的做法已经渐渐地让我不会再受到服务关闭的影响,但于此同时我需要考虑的东西就变得多了,数据安全问题,数据备份的问题,这只是涉及数字资产。
但生活中比数字资产重要多的东西也非常多,要做好任何重要的东西可能丢失的备份策略,如果丢失身份证呢,如果在旅行的过程中丢失了护照呢,或者手机失窃了呢? 去备份任何你生活需要依赖的东西,不要将手机和身份证放到一起,不要将银行卡和任何证件放到一起,去备份你生活中产生的任何个人的数据。
reference
- 使用 zinit 管理 zsh 插件 代替 Antigen
- [[2020-10-17-use-zinit-to-manage-zsh-plugins]]
- Reddit discuss
- https://github.com/nuta/nsh
升级 Gogs(Docker) 从 0.11.91 到 0.12.3
很早之前在 QNAP 上就已经安装过老版本的 Gogs,一路升级到 0.11.91 之后很久没有更新,看了一下用的镜像还是 2020 年 2 月份的,看到 Gogs 也已经迭代了好几个版本,正好这一次做迁移,把 Gogs 从 QNAP 迁移到 VPS 上,随便想着也升级一下 Gogs 的版本。
因为之前使用 Docker 安装的,所以迁移的步骤也比较简单,两个部分数据,一部分是 MySQL 数据库,mysqldump 迁移导入即可,另一部分是写的磁盘持久化部分,tar 打包,scp 或 rsync 传输也比较快。
修改配置文件
Gogs 升级到 0.12.x 的时候官方有一些配置发生了变化,我的所有配置文件都在 ~/gogs 文件夹下,所以我需要修改:
vi ~/gogs/gogs/conf/app.ini
然后修改其中的配置。官方的 0.12.0 的 changelog 已经写的非常清楚了,将这些修改都更改了。
❯ cat ~/gogs/gogs/conf/app.ini
BRAND_NAME = Gogs
RUN_USER = git
RUN_MODE = dev
[database]
TYPE = mysql
HOST = db_host:3306
NAME = gogs
USER = gogs
PASSWORD = BTxax
SSL_MODE = disable
PATH = data/gogs.db
[repository]
ROOT = /data/git/gogs-repositories
[server]
DOMAIN = git.example.com
HTTP_PORT = 3000
EXTERNAL_URL = https://git.example.com
DISABLE_SSH = false
SSH_PORT = 10022
START_SSH_SERVER = false
OFFLINE_MODE = false
[mailer]
ENABLED = false
[service]
REQUIRE_EMAIL_CONFIRMATION = false
ENABLE_NOTIFY_MAIL = false
DISABLE_REGISTRATION = false
ENABLE_CAPTCHA = true
REQUIRE_SIGNIN_VIEW = false
[picture]
DISABLE_GRAVATAR = false
ENABLE_FEDERATED_AVATAR = false
[session]
PROVIDER = file
[log]
MODE = file
LEVEL = Info
ROOT_PATH = /app/gogs/log
[security]
INSTALL_LOCK = true
SECRET_KEY = Mj
可以大致参考我的,但不是每一个选项都要一致,最好自行查看每个选项的含义。
cp app.ini app.ini.bak
sed -i \
-e 's/APP_NAME/BRAND_NAME/g' \
-e 's/ROOT_URL/EXTERNAL_URL/g' \
-e 's/LANDING_PAGE/LANDING_URL/g' \
-e 's/DB_TYPE/TYPE/g' \
-e 's/PASSWD/PASSWORD/g' \
-e 's/REVERSE_PROXY_AUTHENTICATION_USER/REVERSE_PROXY_AUTHENTICATION_HEADER/g' \
-e 's/\[mailer\]/\[email\]/g' \
-e 's/\[service\]/\[auth\]/g' \
-e 's/ACTIVE_CODE_LIVE_MINUTES/ACTIVATE_CODE_LIVES/g' \
-e 's/RESET_PASSWD_CODE_LIVE_MINUTES/RESET_PASSWORD_CODE_LIVES/g' \
-e 's/ENABLE_CAPTCHA/ENABLE_REGISTRATION_CAPTCHA/g' \
-e 's/ENABLE_NOTIFY_MAIL/ENABLE_EMAIL_NOTIFICATION/g' \
-e 's/GC_INTERVAL_TIME/GC_INTERVAL/g' \
-e 's/SESSION_LIFE_TIME/MAX_LIFE_TIME/g' \
app.ini
使用命令 sed 替换。1
修改 Docker Compose 配置
然后在新的 VPS 上使用 docker-compose:
version: "3"
services:
gogs:
image: gogs/gogs:0.12.3
container_name: gogs
restart: always
volumes:
- ~/gogs:/data
ports:
- "10022:22"
environment:
VIRTUAL_HOST: git.example.com
VIRTUAL_PORT: 3000
LETSENCRYPT_HOST: git.example.com
LETSENCRYPT_EMAIL: admin@example.info
networks:
default:
external:
name: nginx-proxy
因为我使用 Nginx Proxy 做反向代理,如果需要可以去除掉。
然后直接 docker-compose up -d 启动即可。
这个时候我遇到一些问题。查看日志
less ~/gogs/gogs/log/gogs.log
2021/10/30 07:35:18 [ INFO] Gogs 0.12.3
2021/10/30 07:35:18 [FATAL] [...o/gogs/internal/route/install.go:75 GlobalInit()] Failed to initialize ORM engine: auto migrate "LFSObject": Error 1071: Specified key was too long; max key length is 767 bytes
会发现报错,这个错误 GitHub issue 上面也有人报错,之前因为迁移,没有来得及查看,后来仔细查看 Gogs 其他日志:
less ~/gogs/gogs/log/gorm.log
发现 gorm 日志中在创建 lfs_object 表的时候发生了错误。
2021/10/30 07:33:49 [log] [gogs.io/gogs/internal/db/db.go:166] Error 1071: Specified key was too long; max key length is 767 bytes
2021/10/30 07:33:49 [sql] [gogs.io/gogs/internal/db/db.go:166] [823.087µs] CREATE TABLE `lfs_object` (`repo_id` bigint,`oid` varchar(255),`size` bigint NOT NULL,`storage` varchar(255) NOT NULL,`created_at` DATETIME NOT NULL , PRIMARY KEY (`repo_id`,`oid`)) ENGINE=InnoDB [] (0 rows affected)
结合之前在 changelog 中看到的,升级到 0.12.x 之后 Gogs 会自动创建这张表,而创建失败了自然就无法启动报 502 错误了。
看这个错误 Error 1071,一看就是 MySQL 的错误。
Error 1071: Specified key was too long; max key length is 767 bytes
我的机器上使用的是 MariaDB,然后 gogs 数据库默认使用的是 utf8mb4_general_ci collation,默认情况下索引长度会有问题,所以将数据库的默认 collation 改成 utf8_general_ci 即可。
使用 phpmyadmin 修改 collation
登录 phpmyadmin 选中数据库 gogs,然后在 Operations 最下面可以看到 Collation 设置,直接修改保存即可。
使用命令行修改 collation
ALTER DATABASE <database_name> CHARACTER SET utf8 COLLATE utf8_general_ci;
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。