终端的输入历史以及管理
配置终端历史文件地址
bash 会将所有终端的输入历史保存在 ~/.bash_history 中,同理,zsh 会保存在 ~/.zsh_history 中。
zsh 使用 HISTFILE 变量来管理保存的 zsh_history 文件,默认一般保存在 ~/.zsh_history 中。
配置 zsh 中记录的终端历史条数
在 zsh 的配置中:1
说明:
HISTSIZE是终端历史中保存的最大行数 2SAVEHIST是保存在历史文件中的最大行数
-
https://unix.stackexchange.com/a/273863/115007
HISTFILE=”$HOME/.zsh_history” HISTSIZE=10000000 SAVEHIST=10000000 setopt BANG_HIST # Treat the ‘!’ character specially during expansion. setopt EXTENDED_HISTORY # Write the history file in the “:start:elapsed;command” format. setopt INC_APPEND_HISTORY # Write to the history file immediately, not when the shell exits. setopt SHARE_HISTORY # Share history between all sessions. setopt HIST_EXPIRE_DUPS_FIRST # Expire duplicate entries first when trimming history. setopt HIST_IGNORE_DUPS # Don’t record an entry that was just recorded again. setopt HIST_IGNORE_ALL_DUPS # Delete old recorded entry if new entry is a duplicate. setopt HIST_FIND_NO_DUPS # Do not display a line previously found. setopt HIST_IGNORE_SPACE # Don’t record an entry starting with a space. setopt HIST_SAVE_NO_DUPS # Don’t write duplicate entries in the history file. setopt HIST_REDUCE_BLANKS # Remove superfluous blanks before recording entry. setopt HIST_VERIFY # Don’t execute immediately upon history expansion. setopt HIST_BEEP # Beep when accessing nonexistent history. ↩
-
http://zsh.sourceforge.net/Doc/Release/Parameters.html#index-HISTSIZE ↩
重拾 Wikipedia
时隔这么多年再来说 Wikipedia, 甚至显得有些落伍,毕竟这个时代,甚至说起 Wikipedia 就像是再谈论一个上世纪的东西,但是其实想想 Wikipedia 诞生也快靠近 20 年。就像之前发出的感慨一样,这些年用了很多的应用,很多的网络服务,但仔细想想曾经 Web2.0 所谓的人人可贡献,就我自己的感受来说,那些我曾经大量使用的服务, 在 Google+ 上分享的内容,在 Google Reader 上分享的文章,都随着关闭烟消云散,反而是我曾经不经意间在 Wikipedia 写下的词条,上传的照片这么多年还依然在,并且曾经的词条在经过更多人修订过后更加可信,更加丰富。
所以上个月开始,我不再给豆瓣添加词条,而把所有的条目内容整理到了 Wikipedia,真的开始了解 Wikipedia 之后我才发现, Wikipedia 的世界看似无秩序,但实际对词条的撰写有着比较严格的要求。
想象在这个世界里每个人都能自由分享所有人类知识的总和。 – 吉米·威尔士
在此,推荐每一个人都去尝试编辑一下 Wikipedia,在这里你能学到尊重他人,你能学到如何搜寻信息,你能学会如何书写可靠来源,你能学到如何保持中立,能学到如何培养版权意识。
可靠来源
在编辑 Wikipedia 的时候最常被编辑提及的就是缺乏“可靠来源”,在编辑每个词条内容的时候,每一句写下的话都要有可靠来源,Wikipedia 毕竟不是个人抒发观点的地方,所以给每句话写下可靠的引用。而可靠的引用又指的什么呢,不能是用户产生的内容,我被拒的其中一个原因就是,引用过多的豆瓣信息,而我也知道豆瓣的条目都是用户贡献的。
The fact that the info is not user-generated is certainly encouraging.
说实话要做到“正确”是非常困难的,但是要做到 Fact-Check 还是比较容易的。某一些内容可能放在现在是正确的,但是可能过一段时间就不正确了,所以 Wikipedia 要时时刻刻准备着被修改。
关于版权保护
之所以上面提到为什么编辑 Wikipedia 会学习到版权保护,那是因为,每一个编辑都需要为自己写下的每一句话负责,严禁复制粘贴原文,并且引用的图片必须要做到合理使用,在上传每一个文件时,Wikipedia 都会列出非常详细的说明。也就是在这个过程中,我知道了维基百科对版权重视。
版权法保护的是思想的表现形式(比如一段介绍“相对论”的文字敘述),而不是思想本身(比如相对论本身這一理論)
创建新条目
像我一样的新手,有些时候看到中文 Wikipedia 没有一个词条,便直接新建了一个词条,不妨用新词条向导来新建,如果不清楚该词条是否满足关注度等等要求,甚至可以先编辑 Draft 然后让其他编辑来审核,或者来一同修改。
reference
kswapd0 占用 99% 的 CPU
这两天办公用的 Ubuntu 总是在内存将用尽的时候死机,所有的界面卡住不同,进 tty 用 top 看一眼后发现 kswapd0 这个进程竟然占用 90~100% 左右的 CPU,网上一查说这个进程是用来管理虚拟内存的。
一般的 Linux 都会有 RAM,swap, 和 EXT4 这几个部分,EXT4 分区就是用来存放一般的文件,可以在机械硬盘或者 SSD 上划分出 ext4 分区来保存文件,相对 RAM(内存)来说要稍微慢一些,RAM 就是日常所说的内存,用来做程序运行时的高速缓存,而 SWAP 是交换分区,一般在物理内存比较小的机器上会划分一块物理磁盘来作为 swap 分区。
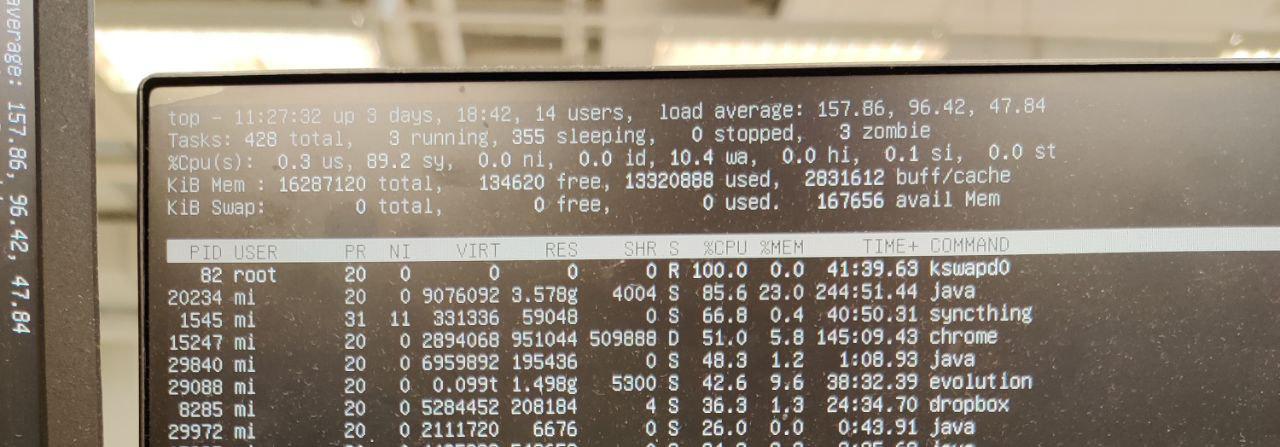
swap 分区是一款虚拟的 RAM,一般在 HDD/SSD 上,当运行比较小的物理内存时,可能经常缺内存,那么系统就会使用 swap 分区,将物理内存中的内容搬迁到 swap 分区中暂存。当可用物理内存比较小的时候,kswapd0 进程就会将相对比较不常用的程序移动到 swap 分区中,这个时候就可能造成这些程序比较卡顿。加入又一台机器物流内存是 4G,而要运行一个需要 5G RAM 的游戏,那么至少有 1G 的内存会放到 swap 分区中。kswapd0 移动内存的过程就会造成 CPU 的大量使用。要解决这个问题有这样几个方式。
在网络上有些教程会提醒用户,当计算机使用了比较大的物理内存的时候,就不需要划分 swap 分区了,一定程度上这种说法也没问题,但是如果 disable swap 分区后,如果遇到程序内存泄漏或者物理内存用完的情况,那么整个计算机就会进入卡死状态。所以推荐还是不要禁用 swap,虽然 swap 分区不会有 RAM 那么快,但是当 RAM 耗尽的时候,swap 分区可以提供一层额外的保护。如果对 swap 比较感兴趣,可以参考这里 阅读更多的相关知识。1
在 askubuntu 的回答中有句话说的很好
Just realize that the SWAP is a failsafe for the RAM.
failsafe 及时发生了故障也要有故障保护机制,否则系统就会 fail.
配置 /etc/sysctl.conf
配置 /etc/sysctl.conf 文件,来告诉 kswapd0 进程只有当物理内存用尽的时候再做移动内存的事情
echo vm.swappiness=0 | sudo tee -a /etc/sysctl.conf
这里 0 表示物理内存还剩余的百分比,这个值的取值范围是 0-100,配置 0 也就意味着只有当没有物理内存可用时再执行 kswapd0.
关闭一些不用的程序
降低或者减少物理内存的使用,也可以降低 kswapd0 过于频繁执行的问题。
购买更多物理内存
一劳永逸的解决内存短缺的问题。也就是换内存条。
手动添加 swap 分区
因为工作的 Ubuntu 是从一盘机械硬盘复制到 SSD 中的,当时 swap 分区没有划分,如果要手动添加 swap 分区可以如下操作。
根据详细的步骤,分区,以及格式化参考之前的文章
编辑 /etc/fstab 文件,增加新的 swap 分区:
sudo vi /etc/fstab
增加类似这样一行:
UUID=735b3be3-779c-4d21-a944-b033225f3ab4 none swap sw 0 0
分区的 UUID,可以通过 blkid 命令来获取:
sudo blkid /dev/sda2
假设 /dev/sda2 就是划分的新的 swap 分区。
优秀开源项目推荐:BookStack 一款高效简单的 Wiki 系统
已经忘记了什么契机,BookStack 就存在了我的 ToDo List 中,一直想要找一款能够快速记录一些常用到的,但是却不太容易记住的东西,原来的方法就是用 markdown + git, 或者如果手边有笔记本,或者手机就记录在 WizNote 中,但这样一来很多内容都散布在各个不同的软件或者应用中,以前也整理过 gitbook 但是一直没有那么系统的想要说整理出一本书这样,所以一直依赖还是用这个博客,记录点点滴滴的学习笔记。
Info
GitHub 地址:
开源协议: MIT license
安装依赖条件:
- PHP & Laravel
- MySQL
浏览 BookStack 的官网 主页上列举了一些 Feature 都是一些非常贴心的功能。
- 完整的权限管理
- WYSIWYG 编辑器,避免了每次我都要 Vim 打开,也使得图片等其他资源管理比较方便
- 搜索,索引,不用每次都要我 rg 先搜索下在编辑了
- 可订制化,从名字到 Logo,到注册选项,虽然我个人用并用不到
- Optional Markdown Editor,这一点非常舒服
- Multi-lingual, 其实我自己用 EN 就够了,不过有时间也给这个项目翻译一下好了
- 支持不同格式的文件导出,赞
这一些功能集合到一起就像是整合版本的 GitBook,支持多人编辑,还有权限管理,完美的解决了使用 markdown + git 管理当文件太多的情况下管理的不便。基于这些理由,所以就在我的 NAS 上,用 Docker 搞了一个。目前先自己用着记录一些暂时未整理好,或者暂时不能公开的内容吧。
安装的过程也非常简单了,官网给出的教程非常详细了,请参考官网.
QNAP 上使用 Docker 安装
首先开启 QNAP 上的 MySQL 服务,然后给 bookstack 新建一个数据库 bookstack,并且给 bookstack 这个数据单独创建一个用户 bookstack。然后因为我的 Docker 配置的网关地址是 10.0.3.1 所以就写了宿主机的地址。然后就不用上面提到的教程单独给 BookStack 开一个 MySQL 实例了,共享宿主机的 MySQL 就行了。
使用命令行:
docker run -d \
--name=bookstack \
-e PUID=1000 \
-e PGID=1000 \
-e APP_URL=${APP_URL} \
-e DB_HOST=${DB_HOST} \
-e DB_USER=${DB_USER} \
-e DB_PASS=${DB_PASS} \
-e DB_DATABASE=${DB_DATABASE} \
-p 6875:80 \
-v ~/path/to/bookstack_config:/config \
--restart unless-stopped \
linuxserver/bookstack
使用 docker-compose:
version: "2"
services:
bookstack:
image: linuxserver/bookstack
container_name: bookstack
environment:
- PUID=1000
- PGID=1000
- DB_HOST=10.0.3.1:3306
- DB_USER=bookstack
- DB_PASS=<password>
- DB_DATABASE=bookstack
volumes:
- /share/Container/bookstack_config:/config
ports:
- 6875:80
restart: unless-stopped
然后等待启动即可。
如果遇到这个问题:
nc: getaddrinfo: Name does not resolve
可以参考 stackoverflow
BT 站点收集整理
不以引进正版为理由的打击盗版都是文化审查。
BT
BT 是 BitTorrent 的缩写。
公开的 BT 站点,请当心 DMCA 钓鱼。
Zooqle
拥有 500 万验证种子文件。
- https://zooqle.com/
eztv
- http://eztv.ag
rss
- http://eztv.ag/ezrss.xml
btbtt
广告很多,记得开启浏览器的广告屏蔽插件,AdBlock, uBlock。
- https://www.btbtt.us/
unblock
- https://unblockit.ca/
The Pirate Bay
- https://www.thepiratebay.org/
RARBG Torrents
- https://rarbg.is/torrents.php
PT
PT 是私有的 Private tracker,相较于 BT,PT 更加私密。
最后如果有很多 PT 站,推荐 PT Plugin Plus 这个浏览器扩展来管理。
PT GTK
PT GTK 是一个分享好看的电影、剧集、学习资源的 PT 站点。
本文日后的更新将会在 PT GTK 站内展开。
btschool
这是我再次开始关注 PT 时,注册的第一个网站。
BeiTai
迄今为止用过的最舒服的 PT 站。
没有考核,速度最快,所以完成后我也会挂很长时间。
Scenetime
SceneTime 是一个 0day/Scene 综合 PT 站,目前存活种子数 80000。
HD Dolby
自从有了 AvistaZ 就不怎么用了。
HDArea
一个没有那么活跃,但是种子数量很多。
HDChina
非常活跃,但平时不怎么用
HDATMOS
HDFans
HDTime
HDZone
LeagueHD
比较早的时候使用比较多,现在也还是不错的,成长比较快的一个站点。推荐。 已经关站。
M-Team
感谢好心人邀请,也是一非常大的站点。不过 free 电影比较少,基本是 50%
聆音 Club
阅读,听书是其特色。
PTMSG
TorrentLeech
0-day
SoulVoice Club
AvistaZ
[[AvistaZ]] 以前叫 AsiaTorrent,是一个东亚、东南亚、南亚的电影、电视剧、音乐的 PT,主要还是中日韩加上港台的资源最多,高清和 DVD 资源都很多。有 10 万用户、3 万种子,是一个比较活跃的高清电影等综合资源的 PT 站点。在注册使用一段时间之后,已经主要使用该网站来看日韩剧了。
重在亚洲的影视资源。可我还没有账号,求邀请。感谢好心人给我邀请,再次感谢。
TTG
暂无账号,求大佬邀请 TTG。
OpenCD
OpenCD 是一个主打音乐的站点,比较想进,但是一直没有机会,所以只能进了 [[jpopsuki]],日韩音乐比较多。主要挺 kpop 的我,目前感觉还行。如果有人有 OpenCD 邀请有求一枚。
CHD Bits
听说是挺大的站,求邀请吧
HDAI
HDAI 是一个比较新的站点,主要是影视剧集。
52PT
主打高清的,不怎么用。
Digital Core
其他
| 在线类 | ||
|---|---|---|
| 名称 | 指路 | 推荐度 |
| 茶杯狐 | https://cupfox.app/ | 5 |
| 电影狗 | https://www.dianyinggou.com/ | 3 |
| NO 视频 | https://www.novipnoad.com/ | 4 |
| 看戏影视 | https://www.kanxi5.com/ | 3 |
| 下载类 | ||
|---|---|---|
| 名称 | 指路 | 推荐度 |
| 分派电影 | https://www.ifenpaidy.com/ | 5 |
| 耐卡 | https://mcar.vip/forum-oumeijuji-1.html | 5 |
| BT 之家 | http://btbtt13.com/ | 4 |
| 人人 | https://yyets.dmesg.app/home | 3 |
| 一刻 | https://www.yikedy.co/ | 4 |
| BD 影视 | https://www.bd2020.com/ | 3 |
| 皮皮虾 | https://ppxzy.cc/ | 5 |
| 极速 BT | http://jisubt.com/ | 4 |
| 全能类 | ||
|---|---|---|
| 名称 | 指路 | 推荐度 |
| BTNull | https://www.btnull.re/ | 5 |
| 小站 | https://newxiaozhan.com/ | 5 |
| 在线之家 | https://www.zxzjtv.com/ | 3 |
| 哔嘀影视 | https://www.btbdys.com/ | 4 |
字幕网站
Spring AOP 笔记
Spring AOP 指的是 Aspect Oriented Programming(面向切面编程),AOP 是一种编程范式,AOP 提供了不同于 OOP 的另一种全新的软件架构思考方式,目的是为了通过分离切面问题来增加程序的模块化,同通俗的话讲就是不修改代码的情况下给程序增加额外的行为。Spring AOP 就是这样一个框架,可以提高我们切面编程的效率。
Spring AOP 的几个常用的使用场景:
- 事务,transaction management
- 日志,logging
- 安全,security
Spring 中有两种方式来使用 AOP
- schema-based approach, 基于 XML 方式配置
- @Aspect annotation approach, 基于注解
Terms
在深入 AOP 之前,先来了解一些关键性的术语:
join-point: 中文通常翻译成切点,切入点,也就是切入的地方,通常是一个方法 a point during the execution of a program, in spring AOP always represents a method executionpointcut:is a predicate or expression that matches join-pointadvice: 具体切入的动作 actions taken by aspect at a particular join-point, is associated with a pointcut expression and runs at any join point matched by the pointcutweaving: linking aspects with other application types or objects to create an advised object.
基于上面的认知,知道 join-point 可以认为是方法调用的时刻,所以 Spring 中有 5 种类型的 Advice 时机:
Before advice, 方法执行前(无法阻止方法执行,除非抛出异常)After returning advice, 正常方法(无异常)返回后执行After throwing advice, 抛出异常时执行After advice, 不管方法正常或者抛出异常后执行Around advice, 方法调用前后
Spring 中 AOP 实现原理
Spring 中 AOP 的实现主要是通过 JDK [[动态代理]]和 [[CGLIB]] 动态代理完成。1可以通过注解 [[Spring @EnableAspectJAutoProxy]] 的参数来指定。
- JDK 动态代理通过反射来代理类,要求被代理的类实现一个接口,JDK 动态代理的核心是
InvocationHandler和Proxy类 - 如果目标类没有实现接口,Spring 会采用 CGLIB 来动态代理目标类,CGLIB 是一个代码生成的类库,可以在运行时动态生成类的子类,CGLIB 通过继承方式代理,所以如果一个类被标记为 final,是无法通过 CGLIB 来做动态代理的
Spring Boot 中使用 AOP
引入依赖:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.1</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
</dependencies>
在启动类上使用 [[Spring @EnableAspectJAutoProxy]] 注解,但其实如果不配置该注解,spring.aop.auto 属性也是默认开启的。
Spring Boot 中指定 CGLIB 实现 AOP。
在注解中指定:
@Configuration
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class AppConfig {}
或者配置属性:
spring.aop.proxy-target-class=true
Maven
具体的版本可以自行搜索使用。
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>4.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>4.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjrt</artifactId>
<version>1.6.11</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.6.11</version>
</dependency>
相关的注解
@Aspect 注解将 Java 类定义为切面,使用 @Pointcut 定义切点。
在不同的位置切入,可以使用 @Before, @After, @AfterReturning, @Around, @AfterThrowing 等等。
@Before,在方法执行前执行@After,方法执行后执行@AfterReturning,方法返回结果之后执行 [[Spring AOP AfterReturning]]@AfterThrowing,异常通知,方法抛出异常之后@Around,环绕方法执行
Pointcut Designators
如何定义切点,以及切点表达式的编写是学习 AOP 的一个重点。
Pointcut expression 由一个 pointcut designator(PCD) 开头,来告诉 Spring 什么时候匹配。Spring 支持很多个 pointcut designators ,最常见的就是 execution 了。
execution
matching method execution join points
匹配某一个特定方法:
@Pointcut("execution(public String info.einverne.FooDao.get(Long))")
假如要匹配 FooDao 中所有方法:
@Pointcut("execution(* info.einverne.FooDao.*(..))")
第一个* 匹配所有的返回值,(..) 表示匹配任意数量的参数。
within
limits matching to join points within certain types
使用 within 也能够达到上面的效果,将类型限定到 FooDao
@Pointcut("within(info.einverne.springboot.demo.dao.FooDao)")
public void logWithClass(JoinPoint jp) {}
或者匹配某个包下所有
@Pointcut("within(info.einverne.springboot.demo.dao..*)")
public void logWithPackage(JoinPoint jp) {}
this and target
- this - limits matching to join points (the execution of methods when using Spring AOP) where the bean reference (Spring AOP proxy) is an instance of the given type
- target - limits matching to join points (the execution of methods when using Spring AOP) where the target object (application object being proxied) is an instance of the given type
this 匹配 bean reference 是给定类型的实例,target 匹配 target Object 是给定类型的实例。this 适用于 Spring AOP 创建 CGLIB-based proxy, target 适用于 JDK-based proxy.
@Pointcut("target(info.einverne.springboot.demo.dao.BaseDao)")
public void logBaseDao(JoinPoint jp) {}
@Pointcut("this(info.einverne.springboot.demo.dao.FooDao)")
public void logThis(JoinPoint jp) {}
args
limits matching to join points (the execution of methods when using Spring AOP) where the arguments are instances of the given types
匹配特定方法参数
// 匹配方法参数是 Long 的方法
@Pointcut("args(Long)")
public void argsMatchLong() {}
args 后面加类名,表示入参是该类的方法。
@target
limits matching to join points (the execution of methods when using Spring AOP) where the class of the executing object has an annotation of the given type
@Pointcut("@target(org.springframework.stereotype.Repository)")
@args
limits matching to join points (the execution of methods when using Spring AOP) where the runtime type of the actual arguments passed have annotations of the given type(s)
// 匹配所有使用了 SomeCustomAnnotation 注解的参数的方法
@Pointcut("@args(info.einverne.SomeCustomAnnotation)")
public void args() {}
@args 需要接注解的类名,表示方法运行时入参标注了指定的注解。
@within
limits matching to join points within types that have the given annotation (the execution of methods declared in types with the given annotation when using Spring AOP)
@Pointcut("@within(org.springframework.stereotype.Repository)")
等于:
@Pointcut("within(@org.springframework.stereotype.Repository *)")
@target 和 @within 的区别:Spring AOP 基于 dynamic proxies, 它仅仅提供了 public, non-static 方法执行的 interception. 而使用 CGLIB proxies, 你可以 intercept package-scoped, non-static 方法。然而 AspectJ 甚至可以 intercept 方法的调用(而不仅仅是方法的执行),member field access (静态或者非静态),constructor call/execution, static class initialisation 等等。2
- @within() is matched statically, requiring the corresponding annotation type to have only the CLASS retention
- @target() is matched at runtime, requiring the same to have the RUNTIME retention
@annotation
@annotation 可以用来表示被注解引用的时机。
limits matching to join points where the subject of the join point (method being executed in Spring AOP) has the given annotation
比如自定义注解:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface LogExecutionTime {
}
那在定义 Pointcut 时可以使用:
@Around("@annotation(com.package.LogExecutionTime)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {}
Order
可以使用 @Order 来指定先后执行顺序。
[[Spring @Order]]
execution expression
execution 在使用时有自己的语法规则:
execution(modifiers-pattern? return-type-pattern declaring-type-pattern?method-name-pattern(param-pattern) throws-pattern?)
public/private void/String/... com.xxxx.SomeClass .saveUser throws *Exception
带问号的可以省略,其他可以支持正则。
组合使用
所有的 Pointcut 之间都可以使用 &&,||, ! 来连接。
@Pointcut("execution(public * *(..))")
private void anyPublicOperation() {}
@Pointcut("within(com.xyz.someapp.trading..*)")
private void inTrading() {}
@Pointcut("anyPublicOperation() && inTrading()")
private void tradingOperation() {}
总结
代码地址:https://github.com/einverne/thrift-swift-demo/tree/master/spring-boot-demo
reference
wp-cli 使用
Install
wget https://raw.githubusercontent.com/wp-cli/builds/gh-pages/phar/wp-cli.phar
sudo chmod +x wp-cli.phar
sudo ln -s /var/www/www.einverne.info/html/wp-cli.phar /usr/local/bin/wp
wp --info
To run any command with WP CLI, you must be in the public directory of your WordPress instance installed.
Usage
Check version
wp core version
Check update
wp core check-update
Update
sudo -u www-data wp core update
sudo -u www-data wp core update-db
Plugin
Check plugins
wp plugin list
sudo -u www-data wp plugin deactivate wordpress-seo
sudo -u www-data wp plugin uninstall wordpress-seo
sudo -u www-data wp plugin update --all
Theme
wp theme search twentyfourteen
sudo -u www-data wp theme install twentyfourteen
sudo -u www-data wp theme activate twentyfourteen
sudo -u www-data wp theme update twentyfourteen
sudo -u www-data wp theme update --all
wp theme list
sudo -u www-data wp theme activate twentyseventeen
sudo -u www-data wp theme uninstall twentyfourteen
Post
wp post list
wp post create --post_type=post --post_title='A sample post'
wp post update 123 --post_status=draft
wp post delete 123
reference
专业医学信息网站整理
前两天鼻炎又犯了,去过很多次医院,也去过不同的医院,有说是慢性鼻炎,有说是过敏性鼻炎,这次检查说是鼻窦炎,总之就是鼻炎了。也尝试过各种药,各种滴鼻液,各种喷雾剂,各种洗鼻水,总是能缓解一段时间,然后到秋冬季节就又会差很多。也不知道是不是环境导致,毕竟大学毕业后还没有在不同城市生活过。所以上一次去了医院之后就在想,对于有些病,或者有些病理信息,是不是我可以在互联网上获得一些信息,然后自我调理,而这两天正好看到 Twitter 上有人提起,所以就整理一下。
医学知识
专业的医学或健康知识可信获取信息源:
- 默沙东诊疗手册 https://www.msdmanuals.com/
- 维基百科 https://wikipedia.org
- WHO;世界卫生组织 (World Health Organization) http://who.int
- 腾讯医典(与 WebMD 联合) https://baike.qq.com/
- 美国食品药品监督管理局:https://fda.gov
CDC
美国疾病控制与预防中心 https://www.cdc.gov/ 世界各国的 CDC https://en.wikipedia.org/wiki/CDC
NIH
美国国立卫生研究院 https://www.nih.gov/
糖尿病 https://dtc.ucsf.edu/zh-hans/
延伸阅读
- 默沙东>
给博客添加 PWA
改造网站支持 Progressive Web Apps (PWA),改善移动端体验。
主要分成一下几步:
- 开启全站 HTTPS
- Service Worker
- Web App Manifest
Service Worker
检测当前的浏览器是否支持 Service Worker
调试 Service Worker,可以在 Chrome 开发者选项 Application 看到 Service Worker.
创建 sw.js 并注册
<script>
if ('serviceWorker' in navigator) {
window.addEventListener('load', function () {
navigator.serviceWorker.register('/sw.js');
//navigator.serviceWorker.ready always resolve
navigator.serviceWorker.ready.then(function (registration) {
console.log('Service worker successfully registered on scope', registration.scope);
});
});
}
</script>
关于 sw.js 比较复杂, 可以参考文末 Google 的文档。
Manifest
manifest 属性
- name —— 网页显示给用户的完整名称
- short_name —— 当空间不足以显示全名时的网站缩写名称
- description —— 关于网站的详细描述
- start_url —— 网页的初始 相对 URL(比如 /)
- scope —— 导航范围。比如,/app/ 的 scope 就限制 app 在这个文件夹里。
- background-color —— 启动屏和浏览器的背景颜色
- theme_color —— 网站的主题颜色,一般都与背景颜色相同,它可以影响网站的显示
- orientation —— 首选的显示方向:any, natural, landscape, landscape-primary, landscape-secondary, portrait, portrait-primary, 和 portrait-secondary。
- display —— 首选的显示方式:fullscreen, standalone (看起来像是 native app),minimal-ui (有简化的浏览器控制选项) 和 browser (常规的浏览器 tab)
- icons —— 定义了 src URL, sizes 和 type 的图片对象数组,用来定义 PWA 的 icon。
页面中添加 manifest.json 使之生效。
<link rel="manifest" href="/manifest.json">
这里 可以生成 manifest 和不同尺寸的 icon
Test
部署后可以测试一下
reference
文件整理之重复文件删除
整理文件的时候总想快速的删掉重复的文件,这里就总结下个人使用感觉良好的几个命令工具,包括 [[jdupes]], rdfind, fdupes, [[fclones]] 这些。
依据推荐指数从高到低。
jdupes
开源地址:
jdupes 是 fdupes 的增强版,根据作者自己的描述,jdupes 比 fdupes 1.51 版本要快 7 倍左右。
使用方式:
Usage: jdupes [options] DIRECTORY...
和 fdupes 类似, jdupes 也有类似的选项:
-d --delete prompt user for files to preserve and delete all
others; important: under particular circumstances,
data may be lost when using this option together
with -s or --symlinks, or when specifying a
particular directory more than once; refer to the
documentation for additional information
-N --noprompt together with --delete, preserve the first file in
each set of duplicates and delete the rest without
prompting the user
-r --recurse for every directory, process its subdirectories too
所以总结一下:
jdupes -r path/to/dir
这行命令不会真正去删重复的文件,如果要删除,用 -d 参数:
jdupes -dr path/to/dir
此时 jdupes 会打印出报告,然后一个一个让用户自己去确认要删除哪一个。
rdfind - find duplicate files in linux
安装使用:
sudo apt-get install rdfind
rdfind -dryrun true path/to/dir
结果会保存在 results.txt 文件中。如果要真正删除 (Be Carefule):
rdfind -deleteduplicates true path/to/dir
或者建立硬链接
rdfind -makehardlinks true path/to/dir
fdupes
安装使用:
sudo apt install fdupes
fdupes path/to/dir
递归搜索:
fdupes -r path/to/dir
如果要删除重复内容可以使用 -d 选项(同样需要非常谨慎):
fdupes -d path/to/dir
-d 选项会弹出选择,用户可以手动选择保留的文件。如果使用 -I 选项会在遇到重复文件时直接删除。
-N 选项和 --delete 一起使用时,会保留第一个文件,然后删除之后的重复文件,不会弹出让用户确认。
最强悍模式:
fdupes -rdN path/to/dir
duperemove
在 review tldr 的 PR 时又看到了一个 C 语言实现的 duperemove,作者没有提供 benchmark,有机会可以尝试一下。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。