JSON 反序列化重命名
Java 中有很多 JSON 相关的类库,项目中也频繁的使用 Jackson, fastjson, gson 等等类库。不过这些类库在反序列化 JSON 字符串到 Object 并且进行重命名字段的方法都不太一致,这里就列一下做个参考。
假设有原始字符串
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
反序列化到类 Employee 上。
GSON
类定义
@Data
public class EmployeeGson {
@SerializedName(value = "fullname", alternate = {"Name", "familyName"})
private String name;
private int age;
@SerializedName("salary")
private float wage;
}
测试方法
@Test
public void testRenameFieldGson() {
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
EmployeeGson employee = new Gson().fromJson(originStr, EmployeeGson.class);
System.out.println(employee);
}
Fastjson
类
@Data
public class EmployeeFastjson {
@JSONField(name = "familyName")
private String name;
private int age;
@JSONField(name = "salary")
private float wage;
}
测试方法
@Test
public void testRenameFieldFastjson() {
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
EmployeeFastjson employee = JSON.parseObject(originStr, EmployeeFastjson.class);
System.out.println(employee);
}
Jackson
@Data
public class EmployeeJackson {
@JsonProperty("familyName")
private String name;
private int age;
@JsonProperty("salary")
private float wage;
}
测试方法
@Test
public void testRenameFieldJackson() throws IOException {
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
EmployeeJackson employeeJackson = new ObjectMapper()
.readValue(originStr, EmployeeJackson.class);
System.out.println(employeeJackson);
}
Function 计算
函数计算,阿里云叫做 Function Compute,Aws 叫做 lambda 函数,GCP 叫做 Cloud Functions,各家都有各家的产品。就如同 AWS 页面介绍的那样,函数计算是一个无服务计算,可以用代码来响应事件并自动管理底层计算资源,比如通过 Amazon Gate API 发送 HTTP 请求,在 S3 桶中修改对象等等。
Serverless
抽象的 Serverless 很难概括,不过 Serverless 也经常被人叫做 Function as a Server(FaaS),这就比较好理解了,比如最常见的存储服务,原来的方式是用户租用云服务器,这种方式需要用户自行部署存储服务,磁盘上的数据也不能共享,于是后来发展出来对象存储,文件存储,消息服务等等,这些服务不再有机器的概念,用户可以轻松的扩容和负载均衡,通过平台提供的 API 进行数据的读写,共享。按照实际存储的数量和访问次数付费,这种就是所谓的 Serverless。
FaaS 的特征就是时间驱动,细粒度,弹性收缩,无需管理服务器等底层资源。
拆分微服务有三个考量,组织结构(参考康威定律),运维发布频率(比如将每周发布两次的服务与每两个月发布一次的服务进行拆分)和逻辑调用频度(将高频调用逻辑和低频调用逻辑分开,在 Serverless 架构下能够进一步降低成本)。
Serverless 适用的两大场景
- 应用负载有显著的波峰波谷
- 典型用例 - 基于事件的数据处理
函数计算的优势
- 不需要管理服务器等基础设施,开发者只需要关注于逻辑开发
- 事件驱动
- 可以快速扩容
- 按需付费
- 将监控,日志,报警等等繁琐的事务隔离开
reference
使用 Git worktree 将同一个项目分裂成多个本地目录
在偶然逛 StackOverflow 的时候看到一个提问,能不能在同一个 repo 中同时有两份代码,并且可以保持两份相似但不是完全相同的代码并行开发?虽然对其需求有些好奇和疑惑 ,但也关注了一下下方的回答。
这个时候我知道了 git 原来还有一个命令叫做 git worktree 这是 Git 2.15 版本引入的新概念。我们都知道一个正常的 git workflow 可能就是从 master 拉出新分支 feature 进行功能开发,如果遇到有紧急 bug,那么从 master 拉出 hotfix 分支紧急修复在合并。这是一个比较常规的工作流,那么 git worktree 为何要被引用进来。从官方的文档 1 上能看到 git worktree 的作用是将多个 working trees 附加到同一个 repository 中,允许用户一次 check out 多个分支。但是问题是为了解决相同的问题,为何要引入一个更加复杂的 git worktree ?
疑惑
于是我又去找了一些材料 2,这个回答解决了我部分疑惑,他说到在大型软件开发过程中可能经常需要维护一个古老的分支,比如三年前的分支,当然 git 允许你每个分支维护一个版本,但是切换 branch 的成本太高,尤其是当代码变动很大的时候,有可能改变了项目结构,甚至可能变更了 build system,如果切换 branch,IDE 可能需要花费大量的时间来重新索引和设置。
但是通过 worktree, 可以避免频繁的切换分支,将老的分支 checkout 到单独的文件夹中作为 worktree,每一个分支都可以有一个独立的 IDE 工程。当然像过去一样你也可以在磁盘上 clone 这个 repo 很多次,但这意味着很多硬盘空间的浪费,甚至需要在不同的仓库中拉取相同的变更很多次。
回到原来的问题,使用 git worktree 确实能够解决最上面提及的问题。
使用
git worktree 的命令只有几行非常容易记住
git worktree add ../new-dir some-existing-branch
git worktree add [path] [branch]
这行命令将在 new-dir 目录中将 some-existing-branch 中的内容 check out 出来,就像在该目录中 clone 了一份新代码一样。新的文件地址可以在文件系统中的任何位置,但是注意千万不要将目录放到主仓库中。在此之后新目录中的内容就可以和主仓库中的内容一样,新建分支,push 到远端。
当工作结束后可以直接删除该目录,然后运行 git worktree prune.
总结
git worktree 非常适合大型项目又需要维护多个分支,想要避免来回切换的情况,这里总结一些优点:
- git worktree 可以快速进行并行开发,同一个项目多个分支同时并行演进
- git worktree 的提交可以在同一个项目中共享
- git worktree 和单独 clone 项目相比,节省了硬盘空间,又因为 git worktree 使用 hard link 实现,要远远快于 clone
More
- 学习 Git 最好的动画交互教程
CPU 负载
之前在 Openwrt 负载 中也曾经谈到过 CPU 的负载,通过 top, uptime 等等命令都可以非常快速的查询当前 CPU 的负载。
CPU 的 load average(平均负载)指的是一段时间内正在使用和等待使用 CPU 的平均任务数。
还有一个判断 CPU 的指标是 CPU 的利用率。同样使用 top 命令也能够查到。但是并不意味着负载高就一定 CPU 利用率高。
如果用电话亭来表示 CPU,把等待打电话的人比作 CPU 需要处理的任务的话,那么假设一队人排队打电话,每个人只能打 1 分钟,时间到了必须重新排队,那么随着时间变化,排队的人数会发生变化,这个等待的人数就是 CPU 的负载,而 1 分钟,5 分钟,15 分钟就是采样的频率。
CPU 的利用率就是电话在拨打的时间长度,但是需要注意的是负载高并不意味着利用率高,可能有人排队等到能打电话时拿着话筒等待了几十秒才拨打电话,那么这浪费的几十秒就不能算是 CPU 的利用率。
问题分析
负载高 CPU 利用率低
说明等待运行的任务很多,很有可能有任务僵死,通过 ps –axjf 查看有没有任务处于 D 状态,该状态为不可中断的睡眠状态,处于 D 状态的进程通常是在等待 IO,通常是 IO 密集型任务,如果大量请求都集中于相同的 IO 设备,超出设备的响应能力,会造成任务在运行队列里堆积等待,也就是 D 状态的进程堆积,那么此时 Load Average 就会飙高。
负载低 CPU 利用率高
说明任务少,但是任务执行时间长,有可能是程序本身有问题,如果没有问题那么计算完成后则利用率会下降。这种场景,通常是计算密集型任务,即大量生成耗时短的计算任务。
CPU 使用率低,IO 繁忙,负载低
这种场景,通常是低频大文件读写,由于请求数量不大,所以任务都处于 R 状态(表示正在运行,或者处于运行队列,可以被调度运行),负载数值反映了当前运行的任务数,不会飙升,IO 设备处于满负荷工作状态,导致系统响应能力降低。
Jenkins 使用
这篇文章主要记录一下 Jenkins Pipeline Syntax 的使用。
Pipeline
Jenkins Pipeline 是什么,简单的来说就是一组定义好的任务,相互连接在一起串行或者并行的来执行,比如非常常见的 build,test,deploy 这样需要重复频繁进行的工作。
更加具体地来说就是 Jenkins 定义了一组非常强大的扩展插件用来支持 CI/CD ,用户可以扩展这些内容来实现自己的内容。这么定义呢?那就是本文的重点,Jenkins 允许用户用一种近似伪代码的形式来编写自己的自定义任务,这个特殊的语法叫做 Pipeline DSL(Domain-Specific Language 特定领域语言)。这一套语法借鉴了 Groovy 的语法特点,有一些些略微的差别。
Jenkins Pipeline 的定义会以文本形式写到 Jenkinsfile 文件中。
举例说明:
pipeline {
agent any ①
stages {
stage('Build') { ②
steps { ③
sh 'make' ④
}
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml' ⑤
}
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
}
说明:
- agent 表示 Jenkins 需要分配一个 executor 和 workspace 给该 pipeline
- stage 表示 Pipeline 的 stage
- steps 表示 stage 中需要进行的步骤 单一任务,定义具体让 Jenkins 实现的内容。比如执行一段 shell 脚本
- sh 执行给定的 shell 命令
- junit 是由
plugin:junit[JUnit plugin]提供的聚合测试
Pipeline 定义的脚本使用 Groovy 书写,基本的 Pipeline 可以通过如下方式创建:
- 在 Jenkins web UI 中直接填写脚本
- 项目根目录创建
Jenkinsfile文件,并提交到项目版本控制
Jenkinsfile 的使用有如下优势:
- 允许用户通过一个文件来定义所有分支,所有 pull requests 的自动化任务
- 可以 review Pipeline 的代码并进行审计
- 通过文件进行管理可以便捷的进行多人协作
Pipeline 语法
Jenkins Pipeline 其实有两种语法
- Declarative
- Scripted
Declarative Pipeline, 提供了一种比较易读的方式,这种语法包含了预先定义好的层级结构,用户可以在此基础上进行扩展。但是这种模式也有一定的限制,比如所有声明式管道都必须包含在 pipeline 块中。
Scripted Pipeline 会在 Jenkins master 节点中借助一个轻量的执行器来运行。它使用极少的资源来将定义好的 Pipeline 转换成原子的命令。
Declarative 和 Scripted 方式都很大的差别,需要注意。
post 语法块
post section 定义了 Pipeline 执行结束后要进行的操作。支持在里面定义很多 Conditions 块:always, changed, failure, success 和 unstable。这些条件块会根据不同的返回结果来执行不同的逻辑。比如常用的 failure 之后进行通知。
- always:不管返回什么状态都会执行,可以在其中定义一些清理环境等等操作
- changed:如果当前管道返回值和上一次已经完成的管道返回值不同时候执行,比如说从失败恢复成功状态
- failure:当前管道返回状态值为”failed”时候执行,在 Web UI 界面上面是红色的标志
- success:当前管道返回状态值为”success”时候执行,在 Web UI 界面上面是绿色的标志
- unstable:当前管道返回状态值为”unstable”时候执行,通常因为测试失败,代码不合法引起的。在 Web UI 界面上面是黄色的标志
- aborted: 当 Pipeline 中止时运行,通常是被手动中止
post 指令可以和 agent 同级,也可以和放在 stage 中。
// Declarative //
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
post {
always {
echo 'I will always say Hello again!'
}
}
}
Node 块
Jenkins 执行的机器被称作 node,主节点是 master,其他节点 slave。在 Pipeline 文件中可以指定当前任务运行在哪一个节点中。
stages 块
由一个或者多个 stage 指令组成,stages 块是核心逻辑。对主要部分 Build,Test,Deploy 单独定义 stage 指令。
一个 stage 下至少需要一个 steps,一般也就定义一个就足够了。
step 块
在 steps 中定义 step。
Jenkins 中其他指令
agent
指定整个 pipeline 或某个特定的 stage 的执行环境
- any - 任意一个可用的 agent,那么定义的任务会跑在任意一个可用的 agent 上
- none - 如果放在 pipeline 顶层,那么每一个 stage 都需要定义自己的 agent 指令
- label - 在 jenkins 环境中指定标签的 agent 上面执行,比如 agent { label ‘my-defined-label’ }
- node - agent { node { label ‘labelName’ } } 和 label 一样,但是可用定义更多可选项
- docker - 指定在 docker 容器中运行
- dockerfile - 使用源码根目录下面的 Dockerfile 构建容器来运行
parameters
参数指令,触发这个管道需要用户指定的参数,然后在 step 中通过 params 对象访问这些参数。
pipeline {
agent any
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
stages {
stage('Example') {
steps {
echo "Hello ${params.PERSON}"
}
}
}
}
triggers
触发器指令定义了这个管道何时该执行,一般我们会将管道和 GitHub、GitLab、BitBucket 关联, 然后使用它们的 webhooks 来触发,就不需要这个指令了。如果不适用 webhooks,就可以定义两种 cron 和 pollSCM
- cron - linux 的 cron 格式
triggers { cron('H 4/* 0 0 1-5') } -
pollSCM - jenkins 的 poll scm 语法,比如
triggers { pollSCM('H 4/* 0 0 1-5') }pipeline { agent any triggers { cron(‘H 4/* 0 0 1-5’) } stages { stage(‘Example’) { steps { echo ‘Hello World’ } } } }
stage
stage 指令定义在 stages 块中,里面必须至少包含一个 steps 指令,一个可选的 agent 指令,以及其他 stage 相关指令。
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}
tools
定义自动安装并自动放入 PATH 里面的工具集合,工具名称必须预先在 Jenkins 中配置好了 → Global Tool Configuration.
pipeline {
agent any
tools {
maven 'apache-maven-3.0.1' ①
}
stages {
stage('Example') {
steps {
sh 'mvn --version'
}
}
}
}
内置条件
- branch - 分支匹配才执行
when { branch 'master' } - environment - 环境变量匹配才执行 when { environment name: ‘DEPLOY_TO’, value: ‘production’ }
- expression - groovy 表达式为真才执行 expression { return params.DEBUG_BUILD } }
Pipeline global variables
地址:
- http://jenkins.url/pipeline-syntax/globals
- http://jenkins.url/env-vars.html
reference
SD 卡种类和标示
如果注意观察 SD 卡面上的内容就会发现上面有很多标签,除开 SD 的品牌,可能还会看见,micro,I, U,等等标识,这些标识都不是厂家随意标注的,每一个都有其特殊的含义。了解这些特殊的标示之后对 SD 卡的选购也有一定的便捷。
microSD vs SD 卡
microSD 卡和 SD 卡的区别其实不用太多交代,基本上从大小就能看出区别。因为体积的区别,所以 microSD 卡经常用于便携,小型设备,比如手机,行车记录仪,运动相机等设备中,而大的 SD 卡则会用于单反等设备。
SD vs SDHC vs SDXC
- SD 卡,Secure Digital Memory Card,安全数字存储卡,SD 1.0 标准,由日本 Panasonic、TOSHIBA 及美国 SanDisk 公司于 1999 年 8 月共同开发研制
- SDHC,Secure Digital High Capacity,高容量 SD 存储卡,SD 2.0 标准,2006 年 5 月 SD 协会发布了 SD 2.0 的系统规范,并在其中规定 SDHC 是符合该规范,SDHC 存储卡容量为:4GB–32GB
- SDXC,SD eXtended Capacity,容量扩大化的安全存储卡,新一代 SD 存储卡标准,SD 3.0 标准,旨在大幅提高内存卡界面速度及存储容量,SDXC 存储卡的目前最大容量可达 512GB,理论上最高容量能达到 2TB
| SD 卡标示 | SD | SDHC | SDXC |
|---|---|---|---|
| 容量 | 上限 2G | 2GB - 32 GB | 32G - 2T |
| 格式 | FAT 12, 16 | FAT 32 | exFAT |
可以看到其实我们平时所说的 SD 卡一直在发展,不管是容量还是速度。
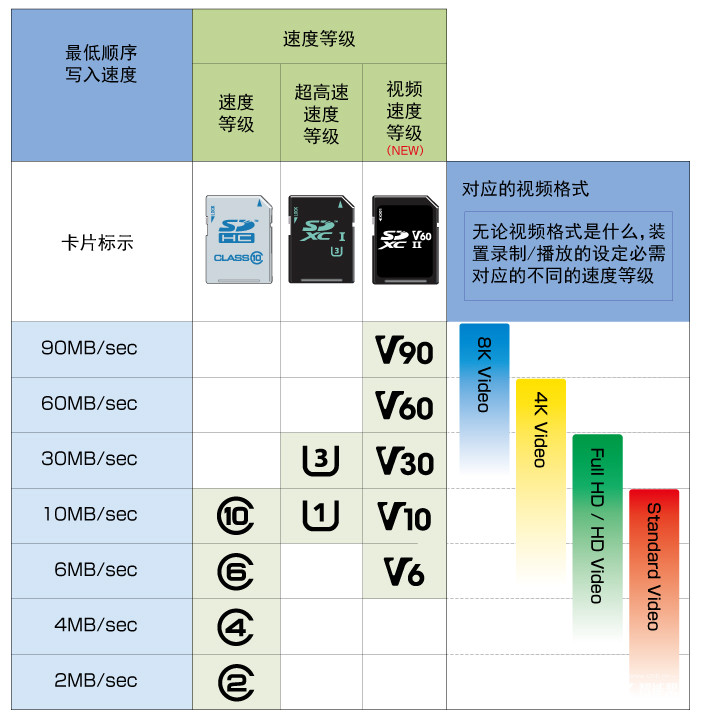
速度等级
在一些稍微老一些的卡上还可能看到 class 2, class 4, class 6, class 10 这样的标识,新一代的 SD 卡会以一个圆圈中间写一个 10 数字来标识 class 10,这个标识表示的是 SD 卡的速度等级。在 2006 年制定 SD 2.0 标准的时候引入了 Class2、Class4、Class6、Class10 级别。
这个 Class 等级,基本上可以理解为 class 10 是 10M/s 的写入速度。
但其实这个级别现在来看又已经过时了,所以现在在 2019 年又会看到 UHS-I,UHS-II,这样的标识,在卡面上会简写成 I,或者 II 这样,这就是 UHS 速度等级。也经常会在旁边看到英文字幕 U 中间写 1 或者 3 这样的标识,这代表着两种不同的速度等级,U1 = 10M/s, U3 = 30M/s.
UHS 速度等级 1 和 3 则是被设计用于 UHS 总线界面,“U1”和“U3”代表的是 UHS 接口规范下的写入速度标准,U1 表示 UHS Class 1,最低写入速度 10MB/s,U3 表示 UHS Class 3,最低写入速度 30MB/s。为了区分 Speed Class 的 Class 2,UHS Class 并没有设置 U2 等级,目前仅有 U1 和 U3,下一个等级也将是 U5。
另外还有一个视频速度等级,会标识成 V6,V10,V30,V60,V90 这样。V 后面的数字和简单的理解成 SD 卡的写入速度,比如 V90 ,就可以理解成写入速度 90M/s .
| 最低写入速度 | Class 写入速度等級标示 | UHS Speed Class 速度 | Video Speed Class | 建议使用环境 |
|---|---|---|---|---|
| 2 MB/s | C2 | 720p | ||
| 4 MB/s | C4 | 高画质拍摄 | ||
| 6 MB/s | C6 | V6 | 高画质拍摄 | |
| 10 MB/s | C10 | U1 | V10 | 1080p Full HD |
| 30 MB/s | U3 | V30 | 4K Video 60/120 fps | |
| 60 MB/s | V60 | 8K Video 60/120 fps | ||
| 90 MB/s | V90 | 8K Video 60/120 fps |
jks pem cer pfx 不同种类的证书
通常在安全级别较高的场景经常需要对通信信息进行加密传输,有一种情况就是非对称加密,将信息使用对方提供的公钥加密传输,然后对方接收到之后使用私钥解密。今天在对接时对方发送了一个压缩包,其中包含了 SSL 不同类型的证书,包括了 jks, pem, cer, pfx 等等文件,现在就来了解一下。
jks
jks 全称 Java KeyStore ,是 Java 的 keytools 证书工具支持的证书私钥格式。jks 包含了公钥和私钥,可以通过 keytool 工具来将公钥和私钥导出。因为包含了私钥,所以 jks 文件通常通过一个密码来加以保护。一般用于 Java 或者 Tomcat 服务器。
keytool -exportcert -rfc -alias mycert -file mycert.cer -keystore mykeys.jks -storepass passw0rd
pfx
[[PFX]] 全称是 Predecessor of PKCS#12, 是微软支持的私钥格式,二进制格式,同时包含证书和私钥,一般有密码保护。一般用于 Windows IIS 服务器。
openssl pkcs12 -in xxx.pfx
转为 pem
openss pkcs12 -in for-iis.pfx -out for-iis.pem -nodes
cer
cer 是证书的公钥,一般都是二进制文件,不保存私钥。
der
二进制格式,Java 和 Windows 服务器偏向使用
openssl x509 -in certificate.der -inform der -text -noout
pem
[[PEM]] 全称是 Privacy Enhanced Mail,格式一般为文本格式,以 -----BEGIN 开头,以 -----END 结尾,中间内容是 BASE64 编码,可保存公钥,也可以保存私钥。有时候会将 pem 格式的私钥改后缀为 .key 以示区别。
这种格式的证书常用于 Apache 和 Nginx 服务器,所以我们在配置 Nginx SSL 的时候就会发现这种格式的证书文件。
Spring 中的 @Transactional 注解
Spring 中有两种不同方式实现事务 —- annotations 和 AOP。
配置事务
在 Spring 3.1 及以后可以使用 @EnableTransactionManagement 注解 1
3.1 之前可以使用 XML 配置,注意几个 tx 的命名空间:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx" xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd">
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="false"/>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
之后在类实现方法中添加 @Transactional 注解即可。
@Transactional(propagation=Propagation.NOT_SUPPORTED)
@Transactional 有如下的属性
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
String value() default "";
Propagation propagation() default Propagation.REQUIRED;
Isolation isolation() default Isolation.DEFAULT;
int timeout() default -1;
boolean readOnly() default false;
Class<? extends Throwable>[] rollbackFor() default {};
String[] rollbackForClassName() default {};
Class<? extends Throwable>[] noRollbackFor() default {};
String[] noRollbackForClassName() default {};
}
传播性
Propagation 支持 7 种不同的传播机制:
- REQUIRED:如果存在事务,则加入当前事务;如果没有事务则开启一个新的事务。
- SUPPORTS: 如果存在一个事务,加入当前事务;如果没有事务,则非事务的执行。但是对于事务同步的事务管理器,PROPAGATION_SUPPORTS 与不使用事务有少许不同。
- NOT_SUPPORTED:总是非事务地执行,并挂起任何存在的事务。
- REQUIRES_NEW:总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
- MANDATORY:如果已经存在一个事务,支持当前事务;如果没有一个活动的事务,则抛出异常。
- NEVER:总是非事务地执行,如果存在一个活动事务,则抛出异常
- NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务,则按 REQUIRED 属性执行。
隔离性
Isolation
- DEFAULT 默认
- READ_UNCOMMITTED: 未授权读取级别 以操作同一行数据为前提,读事务允许其他读事务和写事务,未提交的写事务禁止其他写事务(但允许其他读事务)。此隔离级别可以防止更新丢失,但不能防止脏读 y(一个事务读取到另一个事务未提交的数据)、不可重复读(同一事务中多次读取数据不同)、[[幻读]](同一个事务内读取到另一个事务已提交的 insert 数据)。此隔离级别可以通过“排他写锁”实现
- READ_COMMITTED: 授权读取级别 以操作同一行数据为前提,读事务允许其他读事务和写事务,未提交的写事务禁止其他读事务和写事务。此隔离级别可以防止更新丢失、脏读,但不能防止不可重复读、幻读。此隔离级别可以通过“瞬间共享读锁”和“排他写锁”实现
- REPEATABLE_READ: 可重复读取级别 以操作同一行数据为前提,读事务禁止其他写事务(但允许其他读事务),未提交的写事务禁止其他读事务和写事务。此隔离级别可以防止更新丢失、脏读、不可重复读,但不能防止幻读。此隔离级别可以通过“共享读锁”和“排他写锁”实现
- SERIALIZABLE: 序列化级别 提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,不能并发执行。此隔离级别可以防止更新丢失、脏读、不可重复读、幻读。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到
超时
默认是 30 秒
@Transactional(timeout=30)
只读性
readOnly true of false
多次查询保证结果一致性
回滚异常类
rollbackFor
一组异常类,遇到时 确保 进行回滚。默认情况下 checked exceptions 不进行回滚,仅 unchecked exceptions(即 RuntimeException 的子类)才进行事务回滚
回滚异常类名
rollbackForClassname 一组异常类名,遇到时 确保 进行回滚
不回滚异常类
noRollbackFor 一组异常类,遇到时确保 不 回滚。
不回滚异常类名
noRollbackForClassname 一组异常类,遇到时确保不回滚
实现
默认情况下,数据库按照单独一条语句单独一个事务方式,自动提交模式,每条语句执行完毕,如果执行成功则隐式提交事务,如果失败则隐式回滚。
开启事务管理之后,Spring 会在 org/springframework/jdbc/datasource/DataSourceTransactionManager.java 中将底层自动提交特性关闭。
Spring 事务管理回滚的推荐做法是在当前事务的上下文抛出异常,Spring 事务管理会捕捉任何未处理的异常,然后根据规则决定是否回滚事务。
默认配置下,Spring 只有在抛出异常为运行时 unchecked 异常时才回滚事务,也就是抛出的异常为 RuntimeException 子类(Error 也会)导致回滚,而 checked 异常则不会导致事务回滚。
Spring 在注解了 @Transactional 的类或者方法上创建了一层代理,这一层代理在运行时是不可见的, 这层代理使得 Spring 能够在方法执行之前或者之后增加额外的行为。调用事务时,首先调用的是 AOP 代理对象,而不是目标对象,事务切面通过 TransactionInterceptor 增强事务,在进入目标方法前打开事务,退出目标方法时提交 / 回滚事务。
使用注意
注意事项:
- @Transactional 注解可以被用于接口定义、接口方法、类定义和类的 public 方法上
- @Transactional 注解只能应用到 public 可见度的方法上
- 建议在具体类实现(或方法中)使用 @Transactional 注解,不要在类所实现的接口中使用
- 单纯 @Transactional 注解不能开启事务行为,必须在配置文件中使用配置元素,才真正开启事务行为
- @Transactional 的事务开启,或者是基于接口的,或者是基于类的代理被创建
其他注意事项,比如通过 this 调用事务方法时将不会有事务效果,比如
@Service
public class TargetServiceImpl implements TargetService
{
public void a()
{
this.b();
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void b()
{
// 执行数据库操作
}
}
比如此时调用 this.b() 将不会执行 b 的事务切面。
reference
- https://blog.csdn.net/u013142781/article/details/50421904
- https://www.baeldung.com/transaction-configuration-with-jpa-and-spring
-
https://www.baeldung.com/transaction-configuration-with-jpa-and-spring ↩
Maven 插件学习之: shade 插件
maven shade plugin 插件允许把工程使用到的依赖打包到一个 uber-jar(单一 jar 包) 中并隐藏(重命名)起来。
Shade Plugin 绑定到 package 生命周期。
使用 shade 常见的场景:
- 对包名进行重命名
- 生成单一 jar 包
使用
<project>
...
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<configuration>
<!-- put your configurations here -->
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
...
</project>
实例
该插件允许我们选择最终打的包中包含或者去除那些包,具体可以参考官网
该插件也允许我们将一些类重定位到其他地方(Relocating Classes),如果 uber JAR 被其他项目所以来,直接使用 uber JAR artifact 依赖中的类可能导致和其他相同类的冲突。解决这种问题的方法之一,就是将类重新移动到新位置。官网
默认情况下,到执行 installed/deployed 时默认会生成两个 jar 包,一个以 -shaded 结尾,这个名字是可以配置的。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>customName</shadedClassifierName> <!-- Any name that makes sense -->
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
创建可执行 jar 包,可以将入口添加进来。 官网
reference
Cinnamon 桌面下 Applets 推荐
使用 Linux Mint 一些时候,真的发现有些功能和配置真的非常舒服,以前也写过一篇文章说的是 Cinnamon 桌面自带的 nemo 文件管理器,这可能是我用过的所有系统中自带文件管理器让我用的最舒服的了。所以这里再总结一篇 Cinnamon 下好用的 applets 。
Cinnamon 下所有的 applets 都存放在 ~/.local/share/cinnamon/applets/ 目录下,如果有安装包直接移动到该目录下即可。
Desktop Capture
一句话简单的说就是支持 Screenshot 和 Recorder,录屏和录制视频。
GPaste Reloaded
改写自 Gnome GPaste,提供粘贴板历史记录追踪的功能,可以快速找打粘贴板历史。
Download and Upload Speed
看名字就知道了,看上传下载网速的
Cheaty - CheatSheet keeper
针对主题提供便捷提示的 Cheatsheet。
总结
更多的 Applets 可以到 Cinnamon 的官网自行发掘。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。