为知笔记导出和备份
WizNote 已经用了好几年,虽然也一直在续费,但总感觉将死不死,基于整理这几年近 4000 条的笔记的目的,也一方面为迁移出 WizNote 的目的,研究一下 WizNote 笔记导出和备份的方法。
文中有些具体分析,基于 WizNote for Linux Version 2.5.8 版本,不同版本之间可能有些差异,务必要注意。
在 Linux 下 WizNote 笔记本地缓存放在~/.wiznote/{your-account-email-addr}/data/notes目录下面,都是{GUID}的方式存放,这些文件都是 zip 文件,每个文件里面包含 html , 图片以及元数据。元数据meta.xml 包含了每个 note 的相关信息,比如标题描述等等
如果需要更详细的信息,可以通过读 SQLite 的工具打开 ~/.wiznote/{your-account-email-addr}/data/index.db 文件
准备工作
在导出数据之前有一些准备工作,先同步所有数据,在 Preference 中,Sync 同步选项下
- Personal sync method 选 Download all data
- Group sync method 选择 Download all data when sync
- Download attachment 选择 Download all attachments
否则可能导致本地缓存不是全部的笔记而造成一定程度数据丢失。
解决方法
在 index.db 数据库中有两张很重要的表,WIZ_DOCUMENT 其中包括了所有笔记的信息,包括笔记的 GUID,标题等等信息,具体的表结构可以查看后文附录中内容。另外一张很重要的表是 WIZ_DOCUMENT_ATTACHMENT 其中存储了笔记附件信息。
表中重要的几列
DOCUMENT_GUID看名字就能够猜出来这是笔记的全局唯一 ID,对应着 data 目录中存储的笔记 IDDOCUMENT_TITLE,DOCUMENT_LOCATION等等顾名思义就不多说- 上面提及的两张表通过
DOCUMENT_GUID形成关联,一个笔记可能会对应一个或者多个附件,这些信息都包含在附件表中
所以对应的解决方案就是中 db 中读取笔记的 meta 信息,从磁盘 data 目录中找到对应的笔记,解压缩,然后将对应的附件拷贝到对应的笔记目录。
源码地址:https://github.com/einverne/ExptWizNote
附录
表结构 WIZ_DOCUMENT
create table WIZ_DOCUMENT
(
DOCUMENT_GUID char(36) not null
primary key,
DOCUMENT_TITLE varchar(768) not null,
DOCUMENT_LOCATION varchar(768),
DOCUMENT_NAME varchar(300),
DOCUMENT_SEO varchar(300),
DOCUMENT_URL varchar(2048),
DOCUMENT_AUTHOR varchar(150),
DOCUMENT_KEYWORDS varchar(300),
DOCUMENT_TYPE varchar(20),
DOCUMENT_OWNER varchar(150),
DOCUMENT_FILE_TYPE varchar(20),
STYLE_GUID char(38),
DT_CREATED char(19),
DT_MODIFIED char(19),
DT_ACCESSED char(19),
DOCUMENT_ICON_INDEX int,
DOCUMENT_SYNC int,
DOCUMENT_PROTECT int,
DOCUMENT_READ_COUNT int,
DOCUMENT_ATTACHEMENT_COUNT int,
DOCUMENT_INDEXED int,
DT_INFO_MODIFIED char(19),
DOCUMENT_INFO_MD5 char(32),
DT_DATA_MODIFIED char(19),
DOCUMENT_DATA_MD5 char(32),
DT_PARAM_MODIFIED char(19),
DOCUMENT_PARAM_MD5 char(32),
WIZ_VERSION int64,
INFO_CHANGED int default 1,
DATA_CHANGED int default 1
);
表 WIZ_DOCUMENT_ATTACHMENT 结构
create table WIZ_DOCUMENT_ATTACHMENT
(
ATTACHMENT_GUID char(36) not null
primary key,
DOCUMENT_GUID varchar(36) not null,
ATTACHMENT_NAME varchar(768) not null,
ATTACHMENT_URL varchar(2048),
ATTACHMENT_DESCRIPTION varchar(600),
DT_INFO_MODIFIED char(19),
ATTACHMENT_INFO_MD5 char(32),
DT_DATA_MODIFIED char(19),
ATTACHMENT_DATA_MD5 char(32),
WIZ_VERSION int64
);
Nginx location 匹配规则
之前的关于 Nginx Config 的文章是当时看 Nginx 书记录下来的笔记,很大略,没有实际操作,等终究用到 location 的时候发现还是有很多需要注意的问题,比如匹配的优先顺序,比如 root 和 alias 的区别等等,所以单独拿一篇文章来记录一下目前遇到的问题,并来解决一下。
location 匹配顺序
之前的文章 也简单的提到了 Nginx 配置中 location 块,这个配置能够是的针对 URL 中不同的路径分别可以配置不同的处理路径。
我当前遇到的问题就是提供 API 接口的项目和静态文件的项目是两个单独的项目,我需要 / 处理 proxy_pass 到本地一个端口,而 /resources 到本地另外一个静态资源文件的路径。
location 的语法在很多的文档教程中都被描述为:
location [ = | ~ | ~* | ^~ ] uri { ... }
=用于非正则精确匹配 uri ,要求字符串与 uri 严格匹配,如果匹配成功,则停止向下搜索,并立即处理此请求^~用于非正则 uri 前,Nginx 服务器找到标示 uri 和请求字符串匹配程度最高的 location 后立即使用该 location 处理请求,不再匹配 location 块的正则 url~表示该 uri 包含正则,并且区分大小写~*表示 uri 包含正则,不区分大小写
从四个类别中就能看出来,location 使用两种表示方法,一种为不带 ~ 的前缀字符,一种是带有 ~ 的正则。
需要注意的是:
- 如果使用正则,那么 location 定义的顺序很重要,第一个匹配的正则就立即执行
- 使用精确匹配可以提高查询速度,比如经常请求的路径可以精确匹配
=
一个具体的请求 path 过来之后,Nginx 的具体匹配过程可以分为这么几步:
- 检查前缀字符定义的 location,记录最长的匹配项
- 如果找到了精确匹配
=的 location,结束查找,只用该配置 - 按顺序查找正则定义的 location,如果匹配则停止查找
- 如果没有匹配的正则,则使用之前记录的最长匹配 location
那么针对特定的问题:
location ^~ /resources {
alias /home/einverne/project/static/;
# autoindex on;
}
location ~ / {
proxy_pass http://localhost:9000;
}
首先对于静态文件,我们要让匹配到的第一时间就命中,所以使用了 ^~
关于 location 匹配结尾的斜杠
在 location 后面接的表达式中的 slash 斜杠,可有可无,并没有影响。而对于 URL 中的尾部 / 则是,当有 / 时表示目录,没有时表示文件。当有 / 是服务器会自动去对应目录下找默认文件,而如果没有/ 则会优先去匹配文件,如果找不到文件才会重定向到目录,查默认文件。
root 和 alias 的区别
在 Location 或者其他 Nginx 配置中会经常看到 root 和 alias ,开始我以为这两者是能够混用的,但其实两者有着很大的区别。root 指令会将 location 中的部分附加到 root 定义的末尾形成一个完整的路径;而 alias 则不会包含 location 中定义的部分。
比如:
location /static {
root /var/www/app/static/;
autoindex off;
}
那么当 Nginx 寻找路径时会是:
/var/www/app/static/static/
如果这个在 static 目录的 static 目录不存在则显而易见会产生 404 错误。这是因为 location 中的 static 部分被附加到了 root 指定的路径后面,因此正确的做法是:
location /static {
root /var/www/app/;
autoindex off;
}
而对于 alias 正确的做法则是:
location /static {
alias /var/www/app/static/;
autoindex off;
}
reference
- https://segmentfault.com/a/1190000013267839
- https://stackoverflow.com/a/10647080/1820217
koajs 简单使用
Koa 是一个背靠 Express 的团队设计的全新的 Web 框架,旨在使之成为一个更轻量,更丰富,更加 robust 的基础框架。通过促进异步方法的使用,Koa 允许使用者抛弃 callback 调用,并且大大简化了错误处理。Koa 并没有将中间件绑定到核心代码,而是提供了一组优雅的方法让编写服务更加快速,通过很多第三方的扩展给 Koa 提供服务,从而实现更加丰富完整的 HTTP server。
Koa is a new web framework designed by the team behind Express, which aims to be a smaller, more expressive, and more robust foundation for web applications and APIs. By leveraging async functions, Koa allows you to ditch callbacks and greatly increase error-handling. Koa does not bundle any middleware within its core, and it provides an elegant suite of methods that make writing servers fast and enjoyable.
安装和入门
Koa 需要 node v7.6.0 及以上版本
nvm install 7
npm i koa
node my-koa-app.js
先从简单的例子说起,实现一个简单的 HTTP 服务:
const Koa = require('koa');
const app = new Koa();
const main = ctx => {
ctx.response.body = 'Hello World';
};
app.use(main);
app.listen(3000);
Koa 有一个 Context 对象,表示一次请求上下文,通过对该对象的访问来控制返回给客户端的内容。
路由
Koa 的原生路由就需要使用者自己通过字符串匹配来维护复杂的路由,通过扩展 koa-route 可以实现更加丰富的路由选择
const route = require('koa-route');
const about = ctx => {
ctx.response.type = 'html';
ctx.response.body = '<a href="/">About</a>';
};
const main = ctx => {
ctx.response.body = 'Hello World';
};
app.use(route.get('/', main));
app.use(route.get('/about', about));
那么这样之后通过 localhost:3000/ 和 localhost:3000/about 就可以访问不同内容。
对于静态资源可以使用 koa-static
const path = require('path');
const serve = require('koa-static');
const main = serve(path.join(__dirname));
app.use(main);
更多的内容可以参考文末链接。
reference
- https://koajs.com/
- https://github.com/koajs/koa
- http://www.ruanyifeng.com/blog/2017/08/koa.html
- https://chenshenhai.github.io/koa2-note/note/start/quick.html
- 《Koa 实战》 http://book.apebook.org/minghe/koa-action/hello-koa/what.html
gulp 工具简单使用
Gulp 是基于 Node.js 的前端构建工具,可以通过 Gulp 实现前端代码编译,压缩,测试,图片压缩,浏览器自动刷新,等等,Gulp 提供了很多插件。
大概可以理解成 makefile 之于 C++, Maven 之于 Java 吧,通过定义任务简化前端代码构建过程中繁琐的过程。
简单使用
全局安装
npm i gulp -g
然后在项目根目录安装一遍
npm i gulp --save-dev
一般在根目录创建 gulpfile.js 文件,用来编写 gulp task。
以压缩图片举例:
gulp.task('images', function() {
return gulp.src('src/images/**/*')
.pipe(imagemin({ optimizationLevel: 3, progressive: true, interlaced: true }))
.pipe(gulp.dest('dist/assets/img'))
.pipe(notify({ message: 'Images task complete' }));
});
再运行 gulp images 就可以将 src/images 文件夹及子文件夹图片压缩,最后存放到 dist 目录。
关于压缩图片其实有很多选择:
reference
使用 nltk 词形还原
今天在用 mdx-server 将 mdx 文件导出 HTTP 接口时发现 mdx-server 项目并不支持类似于 GoldenDict Morphology 构词法一样的规则,所以只能够在 mdx-server 外自行处理英语单词的词形变化,搜索一圈之后发现了 NLTK。
英语中词形还原叫做 lemmatization,是将一个任何形式的单词还原为一般形式的意思。另外一个相关的概念是 stemming 也就是词干提取,抽取单词的词干或者词根。这两种方法在自然语言处理中都有大量的使用。这两种方式既有联系也有很大差异。
- 两者的目标相似,lemmatization 和 stemming 目标都是将单词的衍生形态简化或者归并为词干 stem 或者原形,都是对相同单词不同形态的还原
- lemmatization 和 stemming 的结果有交叉,cats 的结果相同
- 主流实现方法类似,通过语言中存在的规则和词典映射提取
- 主要应用领域相似,应用于信息检索和文本,自然语言处理等方面
区别
词干提取采用缩减方法,将词转变为词干,cats 变为 cat,将 effective 处理成 effect,而词性还原采用转变的方法,将词还原为一般形态,将 drove 变为 drive,将 driving 变为 drive
Stemming
In linguistic morphology and information retrieval, stemming is the process for reducing inflected (or sometimes derived) words to their stem, base or root form—generally a written word form. The stem need not be identical to the morphological root of the word; it is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root. Algorithms for stemming have been studied in computer science since the 1960s. Many search engines treat words with the same stem as synonyms as a kind of query expansion, a process called conflation.
Stemming programs are commonly referred to as stemming algorithms or stemmers.
Lemmatization
Lemmatisation (or lemmatization) in linguistics, is the process of grouping together the different inflected forms of a word so they can be analysed as a single item.
In computational linguistics, lemmatisation is the algorithmic process of determining the lemma for a given word. Since the process may involve complex tasks such as understanding context and determining the part of speech of a word in a sentence (requiring, for example, knowledge of the grammar of a language) it can be a hard task to implement a lemmatiser for a new language.
In many languages, words appear in several inflected forms. For example, in English, the verb ‘to walk’ may appear as ‘walk’, ‘walked’, ‘walks’, ‘walking’. The base form, ‘walk’, that one might look up in a dictionary, is called the lemma for the word. The combination of the base form with the part of speech is often called the lexeme of the word.
Lemmatisation is closely related to stemming. The difference is that a stemmer operates on a single word without knowledge of the context, and therefore cannot discriminate between words which have different meanings depending on part of speech. However, stemmers are typically easier to implement and run faster, and the reduced accuracy may not matter for some applications.
NLTK Lemmatization
The NLTK Lemmatization 方法基于 WordNet 内置的 morphy function.
>>> from nltk.stem import WordNetLemmatizer
>>> wordnet_lemmatizer = WordNetLemmatizer()
>>> wordnet_lemmatizer.lemmatize(‘dogs’)
u’dog’
>>> wordnet_lemmatizer.lemmatize(‘churches’)
u’church’
>>> wordnet_lemmatizer.lemmatize(‘aardwolves’)
u’aardwolf’
>>> wordnet_lemmatizer.lemmatize(‘abaci’)
u’abacus’
>>> wordnet_lemmatizer.lemmatize(‘hardrock’)
‘hardrock’
>>> wordnet_lemmatizer.lemmatize(‘are’)
‘are’
>>> wordnet_lemmatizer.lemmatize(‘is’)
‘is’
lemmatize() 方法有第二个 pos 参数,可以传入 n 表示 noun,或者 v 表示 verb,或者其他的形容词等等,提高准确度。
更多的 doc 可以参考 API。
reference
- https://blog.csdn.net/m0_37744293/article/details/79065002
- https://textminingonline.com/dive-into-nltk-part-iv-stemming-and-lemmatization
- https://www.nltk.org
- https://www.nltk.org/book/ch05.html
- http://wordnetweb.princeton.edu/perl/webwn?s=Mastering&sub=Search+WordNet&o2=&o0=1&o8=1&o1=1&o7=&o5=&o9=&o6=&o3=&o4=&h=
AngularJS 学习笔记
如果要说 AngularJS 是什么,那么用这些关键词就能够定义,单页面,适合编写大量 CRUD 操作,MVC
AngularJS 有如下特性:
- 模板语言
- 自动刷新
- 依赖注入
- 模块测试
AngularJS 安装
安装 AngularJS 之前需要确保 Node.js 和 npm 安装。AngularJS 需要 node.js 的 8.x 或者 10.x 版本。
nodejs npm 安装
以前不熟悉 nodejs 的时候为了简单的使用 npm 所以找了 apt 方式安装的方法,这里如果要学习推荐通过 nvm 来安装,可以类似于 pyenv 一样来安装多个版本的 nodejs,并且可以非常方便的管理不同的环境。安装过程比较简单,直接去官方 repo 即可。
简单使用
nvm install node # "node" 是最新版本的别名,所以这行命令是安装最新的 node
nvm install v10.13.0
如果要查看可用版本可以使用
nvm ls-remote
启用并使用最新版本
nvm use v10.13.0
这时在查看 npm 的位置 whereis npm 就会发现在 ~/.nvm/versions 目录下了。
安装 Angular CLI
Angular CLI 用来创建项目,创建应用和库代码,并可以执行多种开发任务,测试,打包,发布等等
npm install -g @angular/cli
创建工作空间和初始化应用
在创建开发环境时还会选择一些特外的特性
ng new angularjs-demo
启动开发服务器
Angular 自带一个开发服务器,可以在本地轻松构建和调试,进入工作空间 (angularjs-demo)
cd angularjs-demo
ng serve --open
更加详细的可以参考官网 quickstart
使用
在学完官网的 Hero demo 之后对 AngularJS 有了一个基本印象,对于基本的 MVC,在 AngularJS 中通过学习 Java 中,定义好 Service 通过依赖注入到模板和 Component 中。
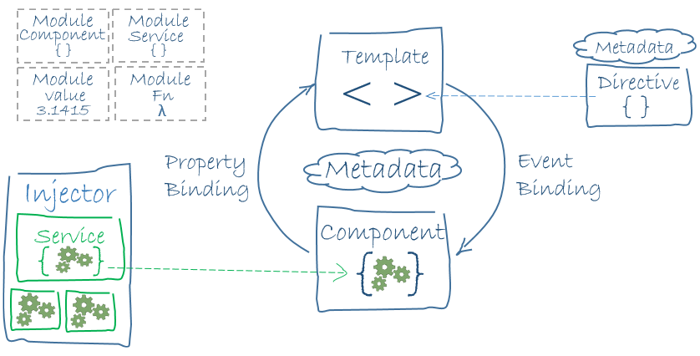
组件和模板定义 Angular 的视图,然后在视图中注入 Service 提供服务。
模块
模块称为 NgModule,存放一些内聚的代码和模板,每个 Angular 都至少有一个 NgModule 类,根模板,习惯上命名为 AppModule,位于 app.module.ts。
在 1.x 时代,可以使用如下代码定义模块
angular.module('myApp', []);
组件
组件控制屏幕上一小片区域,在类中定义组件的逻辑,为视图提供支持。@Component 装饰器会指出紧随其后的那个类是个组件类,并为其指定元数据。
每一个 Component 由以下部分组成:
- Template
- Class
- Metadata
AngularJS 有一套自己的模板语法,这个需要熟悉一下。
AngularJS 支持双向数据绑定,大致语法如下:
从 Component 到 DOM
- ``
[property]="value"
从 DOM 到 Component
(event) = "handler"[(ng-model)] = "property"
服务
Angular 将组件和服务区分,提高模块性和复用性,服务应该提供某一类具体的功能。Angular 通过依赖注入来将逻辑和组件分离。服务可以被多个 Component 共用。
Controller
在 Angular 1.x 时代,Controller 也是很重要的一个部分,一个 Controller 应该是最简单,并且只对一个 view 负责的角色。如果要在 Controller 之间共享信息那么可以使用上面提及的 Service。
Directive
Directive 一般被叫做指令,Angular 中有三种类型的指令:
- 组件,是一种特殊的包含模板的指令
- 结构指令 (structural directives),通过添加和移除 DOM 元素的指令,包括 ngFor, ngIf
- 属性指令,改变元素显示和行为的指令,ngStyle
Angular2 中,属性指令至少需要一个带有 @Directive 装饰器修饰的控制器类,官网有一个很好的 highlight.directive.ts 例子。
数据绑定
数据模型对象 $scope 是一个简单的 Javascript 对象,其属性可以被视图,或者 Controller 访问。双向数据绑定意味着如果视图中数值发生变化,数据 Model 会根据脏检查意识到该变化,而数据 Model 发生变化,视图也会依据变化重新渲染。
简单的数据绑定
<input ng-model="person.name" type="text" placeholder="Yourname">
<h1>Hello\{\{ person.name \}\}</h1>
独特的语法
Angular 有一套自己的 HTML 标记语法,比如在 app.component.ts 中定义
title = '这是一个 AngularJS-demo 演示';
那就可以通过类似于模板的语法来访问该变量:
Welcome to !
又比如条件语句 ngIf,后面的 isLogin 是在 class 中定义好的 boolean 变量:
<div *ngIf="isLogin">Hi </div>
或者循环 ngFor,for 后面接一个表达式
*ngFor = "let variable of variablelist"
比如:
<a *ngFor="let nav of navs"></a>
本文 demo 源码: https://gitlab.com/einverne/angularjs-demo
reference
Aviator 轻量 Java 表达式引擎
Aviator 是一个轻量级、高性能的 Java 表达式执行引擎,它动态地将表达式编译成字节码并运行。
特性:
- 支持数字、字符串、正则、运算符等等
- 支持函数
- 内置 bigint
- ASM 模式可直接将脚本编译成 JVM 字节码
使用
<dependency>
<groupId>com.googlecode.aviator</groupId>
<artifactId>aviator</artifactId>
<version>{version}</version>
</dependency>
最简单直观的使用:
import com.googlecode.aviator.AviatorEvaluator;
public class TestAviator {
public static void main(String[] args) {
Long result = (Long) AviatorEvaluator.execute("1+2+3");
System.out.println(result);
}
}
更加复杂的使用方式可以参考 wiki,文档已经足够详细,不再重复。
源码解析
执行表达式
主要接口
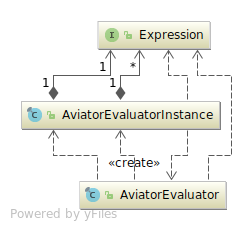
AviatorEvaluator 最重要的方法:
execute(String expression)
execute(String expression, Map<String,Object> env)
execute(String expression, Map<String,Object> env, boolean cached)
这些方法用来执行表达式,并获取结果。围绕这个方法也有可以传入变量的 exec 方法
exec(String expression, Object... values)
内置方法和自定义方法
自定义方法
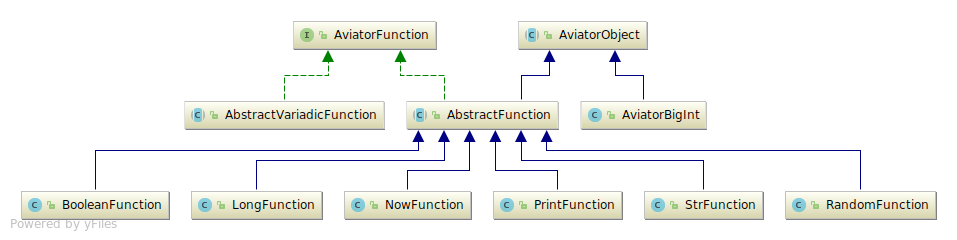
主要可以分为以下几大类,包括数学计算相关,字符串处理相关
数学计算
MathAbsFunction
MathCosFunction
MathLog10Function
MathLogFunction
MathPowFunction
MathRoundFunction
MathSinFunction
MathSqrtFunction
MathTanFunction
字符串相关
StringContainsFunction
StringEndsWithFunction
StringIndexOfFunction
StringJoinFunction
StringLengthFunction
StringReplaceAllFunction
StringReplaceFirstFunction
StringSplitFunction
StringStartsWithFunction
StringSubStringFunction
序列相关方法
SeqCompsitePredFunFunction
SeqCountFunction # count(list) 长度
SeqFilterFunction # 过滤
SeqIncludeFunction # 是否在序列中
SeqMakePredicateFunFunction
SeqMapFunction # 遍历序列
SeqPredicateFunction
SeqReduceFunction # 求和
SeqSortFunction
SeqEveryFunction # 每个都满足
SeqNotAnyFunction # 不在
SeqSomeFunction # 序列中一个元素满足
额外的方法
BinaryFunction
BooleanFunction
Date2StringFunction
DateFormatCache
DoubleFunction
LongFunction
NowFunction
PrintFunction
PrintlnFunction
RandomFunction
StrFunction
String2DateFunction
SysDateFunction
表达式语法解析
FakeCodeGenerator
演示将中缀表达式转换为后缀表达式
reference
后知后觉之 iOS 内置字典
用了近两年 iOS,中途也因为学习需要下载了很多的字典,但是没想到的是 iOS 竟然内置有版权的字典。
之前在下拉搜索框 (Spotlight) 中输入单词偶然会见到单词释义,但是也没有多想,可没想到原来长按选中之后的 “Look up” 竟然有查词的功能。后来查了一下原来 iOS 和 Mac 自带 dictionary 的应用。而 iOS 从 iOS 9 开始就已经有了这功能,iOS 9 中是长按高亮之后在弹出的菜单中选择 Define,而更新到 iOS 10 以后有了一些变化。
向 iOS 添加新字典
字典在 “Setting -> General -> Dictionary” 菜单中,然后选择适当的词典下载到设备中就能够使用。iOS 和 Mac 为不同国家不同语言用户提供了非常多的版权字典,虽然有些词典有些瑕疵但是完全不影响使用。系统自带的词典见附录。
查词
查词有两种,第一种比较方便,在选中单词后在弹出的上下文菜单中选择“Look Up”,系统会弹出查词结果。
第二中就是在 HOME 下拉然后在搜索框中输入想要查找的单词,在下面的结果中会有字典的结果。
当然如果想要有自定义更好的字典那就要使用之前提到的 Goldendict 了。
附录字典列表
- 现代汉语规范词典 / The Standard Dictionary of Contemporary Chinese
> Copyright © 2010, 2013 Oxford University Press and Foreign Language Teaching and Research Publishing, Co., Ltd. All rights reserved. - 牛津英汉汉英词典 / Oxford Chinese Dictionary
> Copyright © 2010, 2015 Oxford University Press and Foreign Language Teaching and Research Publishing Co., Ltd. All rights reserved. - Politikens Nudansk Ordbog / Politikens Modern Danish Dictionary
> Copyright © 2010 Politikens Forlagshus, under licence to Oxford University Press. All rights reserved. - Politikens Nudansk Ordbog / Politikens Modern Danish Dictionary
> Copyright © 2010 Politikens Forlagshus, under licence to Oxford University Press. All rights reserved. - Wörterbuchsubstanz aus: Duden – Wissensnetz deutsche Sprache
> Copyright © 2011, 2013 Bibliographisches Institut GmbH, under licence to Oxford University Press. All rights reserved. - Oxford German Dictionary
> Copyright © 2008, 2015 Oxford University Press. All rights reserved. - С. И. Ожегов «Толковый словарь русского языка» / S.I. Ojegov: Explanatory Dictionary of the Russian Language
> Copyright © 2012 “Universe and Education” Publishing House Ltd., under licence to Oxford University Press. All rights reserved. - Multidictionnaire de la langue française
> Copyright © 2012, 2014 Les Éditions Québec Amérique Inc., under licence to Oxford University Press. All rights reserved. - Oxford-Hachette French Dictionary
> Copyright © 2007, 2015 Oxford University Press & Hachette Livre. All rights reserved. - 五南國語活用辭典 / Wu-Nan Chinese Dictionary
> Copyright © 1987, 2015 Wu-Nan Book Inc. under licence to Oxford University Press. All rights reserved. - 뉴에이스 국어사전 / New Ace Korean Language Dictionary
> Copyright © 2012 DIOTEK, under licence to Oxford University Press. All rights reserved. - 뉴에이스 영한사전 / New Ace English-Korean Dictionary
> Copyright © 2011, 2014 DIOTEK Co., Ltd., under licence to Oxford University Press. All rights reserved. - 뉴에이스 한영사전 / New Ace Korean-English Dictionary
> Copyright © 2011, 2014 DIOTEK Co., Ltd., under licence to Oxford University Press. All rights reserved. - Prisma woordenboek Nederlands
> Copyright © 2010, 2013 Uitgeverij Unieboek | Het Spectrum bv, under licence to Oxford University Press. All rights reserved. - Prisma Handwoordenboek Engels
> Copyright © 2010, 2013 Uitgeverij Unieboek | Het Spectrum bv, under licence to Oxford University Press. All rights reserved. - Norsk Ordbok / Norwegian Monolingual Dictionary
> Copyright © 2012, 2014 Kunnskapsforlaget ANS, under licence to Oxford University Press. All rights reserved. - Dicionário de Português licenciado para Oxford University Press
> Copyright © 2012 Editora Objetiva, under licence to Oxford University Press. All Rights reserved. - スーパー大辞林 / Super Daijirin Japanese Dictionary
> Copyright © 2010, 2013 Sanseido Co., Ltd., under licence to Oxford University Press. All rights reserved. - ウィズダム英和辞典 / The Wisdom English-Japanese Dictionary
> Copyright © 2007, 2013 Sanseido Company Ltd., under licence to Oxford University Press. All rights reserved. - ウィズダム和英辞典 / The Wisdom Japanese-English Dictionary
> Copyright © 2007, 2013 Sanseido Company Ltd., under licence to Oxford University Press. All rights reserved. - NE Ordbok / NE Dictionary
> Copyright © 2013 Nationalencyklopedin, under licence to Oxford University Press. All rights reserved. - พจนานุกรมไทย ฉบับทันสมัยและสมบูรณ์ / Complete Thai Dictionary
> Copyright © 2009 Se-Education PLC, under licence to Oxford University Press. All rights reserved. - Arkadaş Türkçe Sözlük
> Copyright © 2012 Arkadaş Publishing LTD, under licence to Oxford University Press. All rights reserved. - Diccionario General de la Lengua Española Vox
> Copyright © 2012, 2013 Larousse Editorial, S.L., under licence to Oxford University Press. All rights reserved. - Gran Diccionario Oxford – Español-Inglés • Inglés-Español / Oxford Spanish Dictionary
> Copyright © 2008, 2015 Oxford University Press. All rights reserved. - Un dizionario italiano da un affiliato di Oxford University Press
> Copyright © 2005, 2013 Mondadori Education S.p.A., under licence to Oxford University Press. All rights reserved. - Oxford Paravia Il Dizionario inglese – italiano/italiano – inglese / Oxford – Paravia Italian Dictionary
> Copyright © 2010, 2015 Oxford-Paravia Italian Dictionary, Pearson Italia, Milano – Torino, and Oxford University Press. All rights reserved. - राजपाल हिन्दी शब्दकोश / Rajpal Hindi Dictionary
> Copyright © 2011 Rajpal & Sons, under licence to Oxford University Press. All rights reserved. - Oxford Thesaurus of English
> Copyright © 2009, 2016 by Oxford University Press. All rights reserved. - Oxford Dictionary of English
> Copyright © 2010, 2016 by Oxford University Press. All rights reserved. - Oxford American Writer’s Thesaurus
> Copyright © 2012, 2016 by Oxford University Press, Inc. All rights reserved. - New Oxford American Dictionary
>Copyright © 2010, 2016 by Oxford University Press, Inc. All rights reserved.
reference
Drools Kie 中的 Assets
Drools Workbench 中有很多的 Assets (资源)类型,每一种类型的 asset 都意味着一种类型的规则模型,下面就记录下学习的过程。
Model
这个是最好理解的概念了,和 Java 的对象一样。可以通过基础类型定义一些抽象的概念。
Data enumerations
枚举,和常见的枚举也没有太大差别,不过在 Drools 中会被下拉菜单用到。
| Fact | Field | Context |
|---|---|---|
| Applicant | age | [20, 25, 30] |
然后会生成这样的代码
'Applicant.age' : [20,25,30]
如果想要缩写可以使用等号,比如
'Person.gender' : ['M=Male','F=Female']
guided rules
向导型规则,通过 WHEN ,THEN 语句快速建立规则,相对比较简单的一种。在规则设计器中可以轻松的添加条件和结果规则。
Guided rules 规则相对比较简单适合用于单一简单的规则建立。
Guided decision tables
向导型决策表是一种以表格形式表现规则的工具,非常适合描述条件判断很多,条件又可以相互组合,有很多决策方案的情况。决策表可以将这些复杂的逻辑以一种精确而简单的表格形式整理出来,通过 Workbench 中直观的表格形式非常清晰。
Drools 中的决策表可以非常轻松的引导用户制作一个基于 UI 的规则,可以定义规则 attributes, metadata, conditions 和 actions。一旦通过 UI 形式定义好规则,那么所有的规则都会编译为 Drools Rule Language(DRL) 规则。
创建向导型决策表
- Menu → Design → Projects and click the project name
- Click Add Asset → Guided Decision Table
- 填入名字,选择 Package,选择的包需要和依赖的 data Object 在同一个包下
- 选择 Use Wizard 通过向导进行初始化,或者后面自己设定
- 选择 hit policy,不同类型的 hit policy 见下方
- 选择 Extended entry or Limited entry ,两种不同的类型见下方
- 点击 OK 完成,如果选择了 Use Wizard 会出现向导,如果没有选择会出现 table 设计器
- 如果使用向导,选择 imports,fact patterns, constraints 和 actions,选择 table 是否需要 expand。点击 Finish 结束向导
Hit policy
Hit policy 决定了决策表中的每一个规则(每一行)按照什么样的顺序执行,从上往下,或者按照优先级等等
- None 默认,多行可以同时被执行,verification 会将冲突 warning 出来
- Resolved Hit,和 First Hit 类似,每一次只有一行可以被执行,但是可以根据优先级,定义在列表中的执行顺序。可以给不同行设置不同的优先级,从而维持界面中的顺序,但是可以根据需要定义执行顺序
- Unique Hit, 一次只能执行一行,每一行必须 Unique,条件不能有重叠,如果多于一行被执行,会有 warning
- First Hit,依据表中的顺序,从上到下,每一次执行一行,一旦有命中则返回
- Rule Order,多行可以同时执行,verification 不会将冲突警告
Guided decision tables 的类型
Drools 中支持两种类型的决策表:Extended entry and Limited entry
- Extended entry:Extended Entry decision table 是列定义 Pattern,Field,和 Operator,不包括值。值,状态,在决策表的 body 中。
- Limited entry: Limited Entry decision table 的列除了上面的 Pattern, Field, 和 Operator 之外也可以定义具体的数值,具体的状态会以 boolean 值显示在表的 body 中。
向 Guided decision tables 中添加列
在创建完 Guided decision tables 之后可以向表中添加列。
必备条件:所有在列参数中使用的 Facts 或者 Fields 都需要提前创建,并且在同一个包中。
步骤:
- 在 table designer 中选择 Columns -> Insert Column
- 在 Include advanced options 中查看完整的列选项
- 选择想要的列类型,点击 Next
Guided decision tables 中列的类型
Add a Condition
Conditions 代表着 fact patterns 中表示左侧 “WHEN” 部分的规则。使用该列类型,你可以定义一个或者多个条件列,用来检查特定属性值的输入,然后影响 “THEN” 部分的规则。可以定义 bindings,或者选择之前的定义。
when
$i : IncomeSource( type == "Asset" ) // binds the IncomeSource object to $1 variable
then
...
end
Add a Condition BRL fragment
Business Rule Language (BRL) 是规则 “WHEN” 部分,action BRL fragment 是 “THEN” 部分规则。
Add a Metadata column
可以定义 metadata 元素作为列,每一列都代表这普通的 metadata。
Add an Action BRL fragment
action BRL fragment 是 “THEN” 部分的规则,定义该列可以定义 THEN 的动作。
Add an Attribute column
通过该列,可以添加一个或者多个属性,代表着 DRL 规则的属性,比如 Saliance,Enabled, Date-Effective. 通过定义 Salience 100 可以定义优先级。
不过需要注意的是,根据不同的 Hit Policy 设置有些属性可能被禁用。
Delete an existing fact
通过该列,可以定义一些操作,比如删除之前添加的 fact 等等。
Execute a Work Item
通过该列,可以执行之前定义的 work item handler. (work item 可以通过 Menu → Design → Projects → [select project] → Add Asset → Work Item definition 来创建 )
Set the value of a field
很好理解,通过该列,可以设置一个 field。
Set the value of a field with a Work Item result
通过该列可以给 THEN 部分规则设置一个通过 work item hander 得到的结果。 work item 必须和结果参数使用相同的类型以便于赋值。
Guided Decision Table Graph
创建图
当创建 Guided Decision Table Graph 之后系统会自动扫描存在 Guided Decision Tables。
在菜单栏中点击 Documents 添加 graph
guided rule templates
规则模板,可以使用占位符来生成模板来给其他使用
Guided decision trees
向导型决策树,当新建一个决策树之后,编辑器是空白的,左边是可用的数据对象,以及他们的 fields 和 Actions。右边是一张可编辑的图,可以将左侧的内容拖拽到图上来构造一棵树。
构造树有一些简单的限制:
- tree 必须在 root 节点上有一个 Data Object
- tree 只能有一个 root
- Data Objects 可以拥有其他 Data Objects, field 约束或者 Actions 作为子节点,field 约束必须在同一个 DATA Object 的 fields 父节点下
- Field 约束可以有其他 field 约束或者 Actions 作为子节点,field 约束必须在同 Data Object 的 field 节点下
- Actions 只能有其他 Actions 作为子节点
Spreadsheet decision tables
由用户上传一张 excel 表
Decision tables
Decision tables 是 XLS 或者 XLSX spreadsheets ,可以用来定义业务规则。可以直接上传到 Business Central 中。
表中的每一行都是一条规则,列都是条件,动作或者其他规则属性。当创建并上传了决策表之后,规则会被编译成 DRL。
Test Scenario
Test Scenario 用来验证规则是否符合预期,当规则发生改变,可以使用 Test Scenario 来回归测试。
reference
使用 hub 命令来操作 GitHub
hub 命令是 git 命令的扩展,利用 GitHub 的 API 可以轻松的扩展 Git 的能力,比如常见的 pull requests 可以通过命令行来实现。
安装
在官网的文档上,Mac 有一键安装,Fedora 有一键安装,唯独 Ubuntu/Mint 系列没有一键安装的,其实用 hub 的二进制也非常容易,不过没有一键安装,比如 apt install hub 这样的命令还是有些麻烦。
所以有了这个很简单的脚本
VERSION="2.5.1"
wget https://github.com/github/hub/releases/download/v$VERSION/hub-linux-amd64-$VERSION.tgz
tar xzvf hub-linux-amd64-$VERSION.tgz
sudo ./hub-linux-amd64-$VERSION/install
对于 bash,zsh 的自动补全可以参考文末的链接。
Mac 或者 Go 安装可以参考这里
当第一次和 GitHub 有交互时会弹出用户名和密码用来生成 OAuth token,token 保存在 ~/.config/hub 文件中。或者可以提供 GITHUB_TOKEN 环境变量,值是拥有 repo 权限的 access token。
如果需要设置 zsh 的 autocomplete 可以
# Setup autocomplete for zsh:
mkdir -p ~/.zsh/completions
cp ./hub-linux-amd64-$VERSION/etc/hub.zsh_completion ~/.zsh/completions/_hub
echo "fpath=(~/.zsh/completions $fpath)" >> ~/.zshrc
echo "autoload -U compinit && compinit" >> ~/.zshrc
echo "eval "$(hub alias -s)"" >> ~/.zshrc
使用
贡献者
如果是开源项目贡献者,hub 可以使用命令来拉取代码,浏览页面,fork repos,甚至提交 pull requests 等等。
这里为了和 git 命令区别开,还是使用 hub 命令,如果熟悉之后可以设置一个别名直接用 hub 替换 git 命令。
hub clone dotfiles # clone own repo
hub clone github/hub # clone others
hub browse -- issues # Open browser and navigate to issue page
贡献者工作流
hub clone others/repo
cd repo
git checkout -b feature
git commit -m "done with feature"
hub fork # fork repo , hub command will add a remote
hub push YOUR_USER feature
hub pull-request
维护者工作流目前还没有用到先略过。
常用命令介绍
hub push
将本地 branch push 到 remote,和 git 命令类似
hub push REMOTE[,REMOTE2...] [REF]
比如
hub push origin,staging,qa branch_name
hub create
在 GitHub 创建 repo 并且添加 remote.
hub create [-poc] [-d DESC] [-h HOMEPAGE] [[ORGANIZATION/]NAME]
alias
编辑:
git config --global --edit
添加:
[alias]
pr="!f() { \
BRANCH_NAME=$(git rev-parse --abbrev-ref HEAD); \
git push -u origin $BRANCH_NAME; \
hub pull-request; \
};f "
这样以后使用 git pr,就可以实现,push 当前分支,并创建 PR 了。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。