通过 microk8s 使用 Kubernetes
看 Kubernetes 相关书籍的时候都推荐使用 minikube 来在本地安装 Kubernetes 调试环境,但是发现 minikube 安装和使用,都需要使用虚拟化工具,比较麻烦,搜索一下之后发现了 microk8s , microk8s 安装非常简单
snap install microk8s --classic
只需要本地有 snap 环境就可以非常快速一行命令安装成功。
为了不和已经安装的 kubectl 产生冲突,microk8s 有自己的 microk8s.kubectl 命令 o
microk8s.kubectl get services
如果本地没有 kubectl 命令可以增加一个别名
snap alias microk8s.kubectl kubectl
或者取消
snap unalias kubectl
API 服务监听 8080 端口
microk8s.kubectl config view
查看。
Kubernetes Addons
microk8s 只是最精简的安装,所以只有 api-server, controller-manager, scheduler, kubelet, cni, kube-proxy 被安装运行。额外的服务比如 kube-dns, dashboard 可以通过 microk8s.enable 启动
microk8s.enable dns dashboard
禁用
microk8s.disable dns dashboard
可用的扩展
- dns
- dashboard
- storage
- ingress
- gpu
- istio
- registry
- metrics-server
停止或重启 microk8s
snap disable microk8s # 停止
snap enable microk8s # 重启
移除
microk8s.reset
snap remove microk8s
更多配置参考官网
reference
Kubernetes
免责声明:这篇文章只是在了解 Kubernetes 时的一些笔记记录,非常不全面,如果需要全面了解 Kubernetes 那么还请看书或者文档。
Kubernetes 是什么
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
Kubernetes 是 Google 开源的容器集群管理系统,为容器化应用提供资源调度,部署运行,服务发现,扩容和缩容等一系列服务。
能够做什么
Kubernetes 最重要的功能就是容器编排(container orchestration),也就是确保所有的容器能够按照预先的设定在物理机或者虚拟机上执行不同的工作流程。容器必须按照约定打包, Kubernetes 会监控所有正在运行的容器,如果容器”死亡“,或者”无响应“,都会被 Kubernetes 处理。
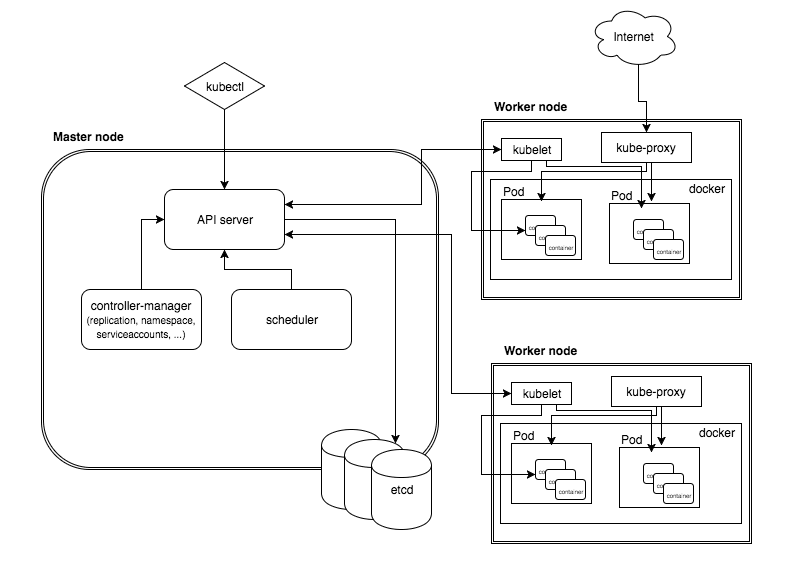
图片来自 Architecture 101
- Cluster, A cluster is a collection of hosts storage and networking resources that Kubernetes uses to run the various workloads that comprise your system.
-
Node(除去 Master 的其他机器), single host, a physical or virtual machine. job is to run pods,可以通过
kubectl get nodes查看 node,或者kubectl describe node <node_name>查看详细信息- kubelet 负责 Pod 对应容器创建、启动停止等
- kube-proxy 实现 Kubernetes Service 通信和负载均衡
- Docker 引擎,负责本机容器创建和管理
-
Master (集群控制节点), is the control plane of Kubernetes, consists of several components, like API server, a scheduler, and a controller manager.
- kube-apiserver 提供 HTTP Rest 接口
- kube-controller-manager 资源对象自动化控制中心
- kube-scheduler 负责资源调度 Pod 调度
- Pod is the unit of work in Kubernetes. Each pod contains one or more containers.
- Label (标签),Label 可以附加到各种资源上,node,pod,service,RC 等。
-
Replication Controller(RC),核心概念之一,定义一个期望的场景,声明某种 Pod 的副本数量在任意时刻都符合某个期望值
- Pod 期待的副本数 replicas
- 筛选目标 Pod 的 Label Selector
- 当 Pod 副本数小于预期时,创建新 Pod 的 Pod 模板
- Replica Sets 和 RC 的区别,在于支持集合的 Label selector,而 RC 只支持基于等式的 Label Selector
- Horizontal Pod Autoscaler(HPA) 实现 Pod 扩容和缩容。
- Service 可以理解为一个微服务
为什么要用 Kubernetes
- 单机走向集群已是必然
- 设计实现分布式系统
- Kubernetes 全面拥抱微服务架构
- Kubernetes 架构有超强的横向扩容能力
分布式系统设计模式
Sidecar Pattern
The Sidecar pattern 是在 pod 中除去 main application 容器之外额外附加的一个容器模式。主要的应用感知不到 sidecar 容器。最好的例子就是中心化的日志收集器,主要的应用容器可以将日志打到 stdout,然后 sidecar 容器收集,然后将所有的日志发送到中心日志服务。
这种方式和在主应用中加入日志系统带来的优势是巨大的,首先,应用可以不被中心日志服务拖累,其次如果想要升级或者改变日志服务,只需要更新 sidecar 容器即可,而不需要修改主应用。
关于更加详细的分析可以参考这篇文章
Ambassador pattern
The Ambassador pattern 可以理解为一个代理层,对于一个远程服务,可以表现为一个本地服务加一些规则来代替提供相同的服务。最常见的使用场景就是,有一个 Redis 集群,master 用来写,而其他 replicas 用来读。
一个 local Ambassador 容器通过代理提供服务,然后暴露 Redis 给主应用容器。主应用容器通过 localhost:6379 来连接 Redis,但是实际上是连接到了同一个 pod 中的 ambassador ,这个代理层会过滤请求,发送写请求给真正的 Redis master,然后读请求会随机的发送给从服务器(replicas)。和 Sidecar 模式中主应用容器一样,主应用是不感知这样的模式的。
这种模式的优点是当 Redis 集群配置发生改变时,只需要 ambassador 做相应的修改即可,主应用不用任何改动。
Adapter pattern
The Adapter pattern 可以理解成将输出标准化。考虑一种模式,一个服务是逐渐发布的,他产生的报告格式可能和之前的格式不相同,但是其他接收输出报告的服务或者应用还没有升级。那么一个 Adapter 容器可以被部署到同一个 pod,将主应用输出的内容转换成老的格式,直到所有的报告消费者都升级完成。Adapter 容器和主应用容器共享一个文件系统,他可以监控本地文件系统,一旦新的应用写入内容,立即将其修改。
Multi-node pattern
单节点 patterns 被 Kubernetes 通过 pod 直接支持。Multi-node 模式,比如 leader election, work queues, 和 scatter-gather 并没有直接支持,但是通过标准接口组合 pods 可以实现。
下载安装
使用 Minikube 快速搭建单节点集群
具体的教程参考官网
使用 microk8s 安装
microk8s 是另外一个用以提供 Kubernetes 快速安装的工具,参考这里
使用
创建 rc 配置
样例文件:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
解释:
kind资源类型spec.replicasPod 副本期待数量spec.template基于此模板创建 pod 实例- template 下
specPod 中容器定义
发布到 Kubernetes
kubectl create -f nginx-rc.yaml
用命令查看
kubectl get rc
kubectl get pods
reference
Drools Kie 简单使用
Drools 是一个 Java 的商业过程实现,这是 Bob McWhirter 所编写的一个开源项目,由 JBoss 和 Red Hat Inc 支持。 Drools 提供一个核心的 Business Rules Engine(BRE) 和一个网页编写规则的管理系统(Drools Workbench)和 一个 Eclipse IDE 的插件,一同构成完整的 Drools 生态。
Drools 是一个 Java 实现的开源[[规则引擎]] (Rule Engine),或者又被称为 Business Rules Management System(BRMS) 。Drools workbench 被叫做 Drools-WB,KIE-WB(或者也叫 KIE Drools workbench) 组合了 Guvnor, Drools 和 jBPM 插件。1
简单地来说,Drools 是一系列的工具集合允许用户将业务逻辑和数据分离。
Kie Server 是一个模块化的,独立的组件,可以用来演示和执行规则和流程。
KIE 全称是 Knowledge Is Everything 2
Drools 功能划分
Drools 大致可以分为两个部分:Authoring 和 Runtime
- Authoring:编写规则部分,包括创建规则文件 .DRL 文件
- Runtime:包括创建工作内存处理规则等等
Authoring
Authoring 包括:
- 规则文件 DRL 创建
- 语法检查
- 编译规则到源码文件
Runtime
Drools Runtime 需要告诉如何执行特定 jar,用户可以在不同的 Runtime 中执行程序。
Working Memory
Working Memory 是 Drools Engine 的核心要素:Facts 被插入的时候。Facts 是 plain Java Classes,被插入到 Working Memory 的 Facts 会被修改或者扩展。
为什么会产生规则引擎
在企业复杂项目演进过程中随着外部条件复杂化会造成不断变化的业务逻辑,在系统实现时需要考虑将应用开发实现和商业业务决策逻辑剥离。这些规则可以集中管理,也可以在运行时动态管理修改,规则引擎正是基于上面的背景诞生的解决方案。
规则引擎用来处理什么问题
Drools 用来解决复杂规则的问题。现实问题往往会有很多逻辑判断,而如果将这些逻辑判断都编码写死在代码逻辑中,不仅实现混乱,而不易于维护。Drools 可以让应用逻辑和数据逻辑分离,通过直观的规则编排将数据逻辑单独处理。
通常来讲,如果一个系统需要接受一系列的参数,根据这些参数做一些决策,那么 Drools 应该都能够处理。
规则引擎(BRMS)的特点:
- 业务规则可以嵌入应用程序任何位置
- 可持久化
- 依据市场变化,业务规则需要能够快速,低成本更新
- 测试场景可视化
- 版本控制
- 类人语言
可以这么理解规则引擎,是一种在应用程序中可嵌入的组件,将业务逻辑从应用代码中分离,使用行业特定的规则模块编写业务逻辑,接受数据输入,解释业务规则,并根据规则做出业务决策。
规则引擎适用场景
规则引擎并不万能,在业务中使用规则引擎需要预先分析业务的使用场景,规则引擎适用于下面的场景:
- 业务规则数量有限,如果有成百条规则就明显不太适合使用规则引擎
- 规则经常发生变动
声明式编程
规则引擎描述做什么,而不是如何去做。规则可以对复杂问题进行简化,规则的事先声明也使得困难问题得以分步解决,并且可以通过规则来验证。不像程序代码,规则使用比较简单的语法规则书写,规则比编码更易读。
逻辑与数据分离
数据保存在系统对象,逻辑保存在规则,打破了面向对象编程系统中数据和逻辑耦合的问题。
当逻辑跨领域时更为有用,通过将逻辑规则集中在一起维护,取代了分散在代码中的问题。
速度和可测量
Rete 算法,Leaps 算法,提供了系统数据对象有效的匹配。RETE 算法来自 Dr. Charles Forgy 在 1979 年的 《专家系统原理和编程》中 CIS587:The RETE Algorithm
集中化规则
通过规则,可以建立一个可执行的规则库,规则库代表着现实业务策略,理想情况下可读性高的规则还可以作为文档。
类自然语言的规则
通过 DSL 领域特定语言,可以让编码者通过接近自然语言的方式来编写规则。这让非技术人员和领域专家可以使用自己的逻辑来理解和编写规则。
工具集成
类似于 Eclipse 这样的工具提供了方法用来编辑和管理规则,并且可以用来提供反馈,校验。同时也有审计和调试的工具。
说明设施
Rule 系统提供了方法可以记录决策的结果,以及如何被决策的过程。
如何使用规则引擎
规则引擎至少应该包括:
- 加载卸载规则集 API
- 数据操作 API
- 引擎执行 API
使用规则引擎遵循五个典型步骤:
- 创建规则
- 向引擎添加或者更换规则
- 向引擎提交数据
- 引擎执行
- 导出引擎执行结果,获取数据
一个开放的规则引擎可以被嵌在程序任何位置。
Docker 启动 drools workbench
Google 搜索之后发现 drools-workbench 有下面两个版本,不带 showcase 的版本是设计用来扩展,可以增加自己的的配置的镜像,而如果想要直接使用,那么可以使用 drools-workbench-showcase:latest 这个镜像,这个镜像包含了一些默认的配置。
docker pull jboss/drools-workbench
docker pull jboss/drools-workbench-showcase
拉取镜像后
docker run -p 8080:8080 -p 8001:8001 -d --name drools-wb jboss/drools-workbench-showcase:latest
当应用启动后,可以访问 http://localhost:8080/drools-wb 来体验 workbench 功能。
下面是镜像中默认包含的用户和角色:
USER PASSWORD ROLE
*********************************************
admin admin admin,analyst,kiemgmt
krisv krisv admin,analyst
john john analyst,Accounting,PM
sales-rep sales-rep analyst,sales
katy katy analyst,HR
jack jack analyst,IT
如果想要自己扩展用户,那么可以尝试使用不带 showcase 的版本。
Docker 启动 Kie Server
拉取镜像
docker pull jboss/kie-server-showcase
拉取完成后,如下启动:
docker run -p 8180:8080 -d --name kie-server --link drools-wb:kie_wb jboss/kie-server-showcase:latest
Drools
Drools 大体可以分为两个部分:Authoring 构建 和 Runtime 运行。
Authoring
构建过程涉及到 .drl 规则文件创建,通过上面的 workbench 可以使用界面来创建规则。
Runtime
运行时则是在执行规则的服务,kie 提供了 server 可以用来执行规则。
如果要 clone KIE 中的规则,那么在项目的 General Settings 中获取 SSH 地址
git clone ssh://0.0.0.0:8001/MySpace/example
这个地址需要注意,如果是使用 Docker 安装的,那么在 clone 的地址中需要加入用户
git clone ssh://admin@0.0.0.0:8001/MySpace/example
然后再使用密码即可。
reference
- http://www.drools.org/
- https://hub.docker.com/r/jboss/drools-workbench-showcase/
- https://training-course-material.com/training/Drools_KIE_introduction
- https://blog.csdn.net/chinrui/article/details/79018351
- http://geosmart.github.io/2016/08/22/Drools%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
- http://www.iigrowing.cn/java_gui_ze_yin_qing_zong_jie.html
- https://examples.javacodegeeks.com/enterprise-java/jboss-drools/jboss-drools-best-practices-tutorial/
Netty 简单实用
Netty 是异步、事件驱动的网络框架,可以用于开发高性能的网络服务器程序。
传统的多线程服务端程序是 Blocking (阻塞的),也就是接受客户端连接,读数据,发送数据是阻塞的,线程必须处理完才能继续下一个请求。而 Netty 的 NIO 采用事件机制,将连接,读,写分开,使用很少的线程就能够异步 IO。Netty 是在 Java NIO 的基础上的一层封装。
Netty 的官方文档和入门手册已经非常详细了,几乎是手把手的实现了 DISCARD ,ECHO 和 TIMESERVER 的例子,把官方的例子实现一遍对 Netty 就会有一点的了解了。
使用 LineBasedFrameDecoder 解决 TCP 粘包问题
TCP 粘包拆包
首先要了解 TCP 的粘包和拆包,TCP 是一个流协议,是一串没有边界的数据,TCP 并不了解上层业务数据含义,他会根据 TCP 缓冲区实际情况进行包划分,所以业务上,一个完整的包可能被 TCP 拆分为多个包发送,也可能把多个小包封装为一个大数据包发送。
业界对 TCP 粘包和拆包的解决方案:
- 消息定长,固定长度,不够补位
- 包尾增加回车换行符进行切割,FTP
- 将消息分为消息头和消息体,在消息头中包含消息总长度,通常设计一个字段用 int32 来表示消息长度
- 其他应用层协议
Netty 提供了半包解码器来解决 TCP 粘包拆包问题。
private class ChildChannelHandler extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel arg0) throws Exception {
arg0.pipeline().addLast(new LineBasedFrameDecoder(1024));
arg0.pipeline().addLast(new StringDecoder());
arg0.pipeline().addLast(new TimeServerHandler());
}
}
对于使用者,只需要将支持半包解码的 Handler 添加到 ChannelPipeline 即可。
LineBasedFrameDecoder 原理是依次遍历 ByteBuf 中可读字节,判断是否有 \n 或 \r\n ,有则以此为结束,组成一行。
StringDecoder 是将接受到的对象转成字符串,然后调用后面的 Handler,LineBasedFrameDecoder 和 StringDecoder 组合就是按行切换的文本解码器。
分隔符和定长解码器
就像上文说的 TCP 以流进行传输,上层应用对消息进行区分,采用的方式:
- 固定长度
- 回车换行作为结束符
- 特殊分隔符作为结束
- 定义消息头,包含消息总长度
Netty 对这四种方式做了抽象,提供四种解码器来解决对应的问题。上面使用了 LineBasedFrameDecoder 解决了 TCP 的粘包问题,另外还有两个比较常用的 DelimiterBaseFrameDecoder 和 FixedLengthFrameDecoder。
DelimiterBaseFrameDecoder 是分隔符解码器,而 FixedLengthFrameDecoder 是固定长度解码器。
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(1024, delimiter));
ch.pipeline().addLast(new FixedLengthFrameDecoder(20));
对应的源代码可以参考这里
Netty 实际用途
Netty 在 RPC 框架中有大量的使用,提到 RPC 就不得不提 Java 的编解码。Java 序列化的主要目的:
- 对象持久化
- 网络传输
但是 Java 序列化也有缺陷:
- 无法跨语言使用
- 序列化后码流太大
- 序列化性能不行
代码库:https://gitlab.com/einverne/netty-guide-book
reference
- 《Netty 权威指南》
- https://netty.io/wiki/user-guide-for-5.x.html
由 libevent 库开始学习 Linux IO 模型
在看 Java 的 Netty 的时候,了解到了 NIO,从 NIO 了解到了 C 语言实现的 libevent 。我们为什么需要这样一个库,他的出现是为了解决什么问题。对于熟悉网络编程,或者多线程的人来说,都会知道一个普遍存在的问题,CPU 要远远快过 IO。所以如果我们要同时处理多个任务,而当前的任务阻塞了 IO,那么理想的状态应该是让 CPU 执行其他任务,而让阻塞 IO 的任务放到后台执行。
libevent 库提供了一种事件响应机制,当事件发生在用户关心的文件描述符上时,通知用户,并且隐藏后台真正使用的方法(select,epoll,kqueue) ,这避免了让用户为各个平台书写不同代码的问题。
Linux 网络 IO 模型
Linux 内核将所有外部设备看做一个文件来操作,对一个文件的读写操作会调用内核提供的命令,返回 file descriptor。对一个 socket 的读写也有相应的描述符,socketfd,描述符是一个数字,指向内核中一个结构体。
UNIX 网络编程对 IO 模型划分了 5 类:
- 阻塞 I/O 模型:默认情况下所有文件操作都是阻塞的。以套接字为例,进程中调用 recvfrom,系统调用直到数据包到达且被复制到应用进程缓冲区或者发生错误时才返回,期间一直等待,进程从调用 recvfrom 开始到返回整个过程是被阻塞的
- 非阻塞 I/O 模型:recvfrom 从应用层到内核,如果该缓冲区没有数据,直接返回一个 EWOULDBLOCK 错误,一般轮讯检查该状态,看内核是否有数据
- I/O 复用模型:Linux 提供 select/poll ,进程通过一个或者多个文件描述符传递给 select 或者 poll 系统调用,阻塞在 select 操作,select/poll 可以侦测多个文件描述符是否处于就绪状态。Linux 还提供 epoll 系统调用,epoll 使用基于事件驱动方式代替顺序扫描
- 信号驱动 I/O 模型,开启套接口信号驱动 IO 功能,通过系统调用 sigaction 执行信号处理函数(非阻塞),当数据准备好,进程生成 SIGIO 信号,通过信号回调通知应用程序调用 recvfrom 来读取数据,并通知主循环函数处理
- 异步 IO:告知内核启动某个操作,并让内核在整个操作完成后(包括将数据从内核复制到用户缓冲区)通知用户。这种模型区别于信号驱动主要区别是:信号驱动 IO 由内核通知何时开始 IO 操作;异步 IO 由内核通知 IO 何时已经完成
更多的可以参考《UNIX 网络编程》这本书。
NIO 类库
NIO 在 JDK 1.4 引入,弥补了 JAVA 原来的同步阻塞 IO 的不足。
缓冲区 Buffer
Buffer 是一个对象,包含一些要写入或者要读的数据。在面向流的 IO 中,数据可以直接写入或者读取到 Stream 对象中,在 NIO 库中,所有的数据都是用缓冲区处理。
缓冲区实质上是数组,通常是字节数组 ByteBuffer,缓冲区也不仅是一个数组,缓冲区提供了数据结构化访问以及维护读写位置等信息。
最常用的是 ByteBuffer ,但是每一种 Java 基本类型都对应一个缓冲区。
通道 Channel
网络数据通过 Channel 读写,通道和流不同的是通道是双向的,流只是一个方向的移动,通道可以同时用于读、写或者同时进行。
Channel 可以分为两类:
- 网络读写的 SelectableChannel
- 文件 FileChannel
多路复用器 Selector
Selector 会不断轮询注册在上面的 Channel,如果某 Channel 发生读写时间,Channel 处于就绪状态,被 Selector 轮询出来,通过 SelectionKey 获取就绪 Channel 集合,进行后续 IO。
reference
Java 查漏补缺之 jvm
JVM 设计者将 JVM 内存结构划分为多个区域,每个内存区域有各自的用途,负责存储各自的数据类型。有些内存区生命周期和 JVM 一致,也有些和线程生命周期一致,伴随着诞生,伴随着消亡。
Java 源代码文件会被编译为字节码(.class),然后由 JVM 中类加载器加载类字节码,加载完毕后,交给 JVM 执行引擎,整个程序郭晨中 JVM 会使用一段内存空间来存储执行过程中需要用到的数据和信息,这段空间一般被称为 Runtime Data Area,也就是 JVM 内存。
线程共享内存区
允许被所有线程共享访问的内存区,包括堆,方法区,运行时常量池三个内存区。
堆
Java 堆区在 JVM 启动时被创建,在实际内存空间可以是不连续的。Java 堆用于存储对象实例,GC 执行垃圾回收重点区域。JVM 一些优化会将生命周期长的 Java 对象移动到堆外。所以 Java 堆不再是 Java 对象内存分配唯一的选择。
JVM 中的对象分为,生命周期比较短的瞬时对象和长时间的对象。针对不同的 Java 对象,采取不同的垃圾收集策略,分代收集。GC 分代收集,新生代 和 老年代。
-Xms 和 -Xmx 参数分别可以设置 JVM 启动时起始内存和最大内存。
方法区
方法区存储了每一个 Java 类结构信息,包括运行时常量池,字段和方法数据,构造函数,普通方法字节码内容以及类,实例,接口初始化需要用到的特殊方法等数据。
-XX:MaxPermSize 设置方法区内存大小,方法区内存不会被 GC 频繁回收,又称“永久代”。
运行时常量池 Runtime Constant Pool
运行时常量池属于方法区中一部分。有效的字节码文件包含类的版本信息、字段、方法和接口等描述信息之外,还包含常量池表(Constant Pool Table),运行时常量池就是字节码文件中常量池表的运行时表现形式。
线程私有内存区
和共享内存区不同,私有内存区是不允许被所有线程共享访问的。线程私有内存区是只允许被所属的独立线程进行访问的一类内存区域,包括 PC 寄存器,Java 栈,本地方法栈三个。
PC 计数器 Program Counter Register
JVM 中的 PC 计数器(又被称为 PC 寄存器,不同于物理的寄存器,这里只是代称),JVM 中的 PC 寄存器是对物理 PC 寄存器的抽象,线程私有,生命周期和线程生命周期一致。
Java 虚拟机栈
Java 虚拟机栈描述的是 Java 方法执行的内存模型:每个方法执行时会创建栈帧(Stack Frame)。
Java 虚拟机栈用于存储栈帧(Stack Frame),栈帧中所存储的是局部变量表,操作数栈,以及方法出口等信息。
Java 堆中存储对象实例,Java 栈中局部变量表用于存储各类原始数据类型,引用(reference)以及 returnAddress 类型。
Java 栈允许被实现为固定或者动态扩展内存大小,如果 Java 栈被设定为固定大小,一旦线程请求分配的栈容量超过 JVM 允许最大值,JVM 会抛出一个 StackOverflowError 异常,如果配置动态,则抛出 OutOfMemoryError。
本地方法栈 Native Method Stack
本地方法栈(Native Method Stack)用于支持本地方法(native 方法,比如调用 C/C++ 方法),和 Java 栈作用类似。
一般来说,Java 对象引用涉及到内存三个区域:堆,栈,方法区
Object o = new Object()
o是一个引用,存储在栈中new Object()实例对象存在堆中- 堆中还记录能够查询到此 Object 对象的类型数据(接口,方法,field,对象类型),实际的数据则放在方法区
垃圾回收算法
垃圾标记
常见的垃圾回收算法是引用计数法和根搜索法,引用计数虽然实现简单粗暴,但是无法解决相互引用,无法释放内存的问题,所以引入了根搜索算法。根搜索算法是以根对象集合作为起始点,按照从上到下的方式搜索被根对象集合所连接的目标对象是否可达,如果不可达,则对象死亡,标记为垃圾对象。
在 HotSpot 中,根对象集合包含:
- Java 栈中对象引用
- 本地方法栈中对象引用
- 运行时常量池中对象引用
- 方法区中类静态属性的对象引用
- 与一个类对应的唯一数据类型 Class 对象
垃圾回收
标记压缩算法
垃圾回收分两个阶段,垃圾标记和内存释放,和下面要说的两种回收算法相比,标记清除效率低下,更重要的是,可能造成回收之后内存空间不连续。
复制算法
为了解决标记压缩算法造成的内存碎片问题,JVM 设计者引入了复制算法。Java 堆区如果进一步细分,可以分为新生代,老年代,而新生代又可以分为 Eden 空间,From Survivor 和 To Survivor 空间。在 HotSpot 中,Eden 空间和另外两个空间默认比 8:1,可以通过 -XX:survivorRatio 来调整。执行 Minor GC(新生代垃圾回收)时,Eden 空间中的存活对象会被复制到 To 空间,之前经历过 Minor GC 并且在 From 空间中存活的对象,也会被复制到 To 空间。当下面两种特殊情况下,Eden 和 From 空间中的存活对象不会被复制到 To 空间:
- 存活对象分代年龄超过
-XX:MaxTenuringThreshold所指定的阈值,直接晋升到老年代 - 当 To 空间容量达到阈值,存活对象直接晋升到老年代
当所有存活对象复制到 To 空间或者变为老年代时,剩下都为垃圾对象,意味着 Minor GC,释放掉 Eden 和 From 空间。然后 From 和 To 空间互换。
复制算法适合高效率的 Minor GC,但是不适合老年代的内存回收。
标记压缩算法
因为以上两种算法都有或多或少的问题,所以 JVM 又引入了 标记压缩算法,在成功标记出内存的垃圾对象后,该算法会将所有的存活对象都移动到一个规整的连续的内存空间,然后执行 Full GC 回收无用对象内存空间。当算法成功之后,已用和未用空间各自存放一边。
reference
- 《Java 虚拟机精讲》
Go 语言学习笔记 3:基础类型
和大多数强类型语言一样,Go 也有自己基本的类型系统。Go 语言的类型大致可以分为四大类:
- basic types 基础类型(basic types)包括
numbers,strings,booleans - aggregate types 聚合类型(aggregate types)包括
arrays,structs - reference types 引用类型(reference types) 包括不同组,包括
pointers,slices,maps,functions,channels,他们都是程序变量或者状态的引用 - interface types, 接口类型 (interface types) 是特殊的一个类型,会在后面单独介绍。
Integers
Go 数值类型包括整型,浮点数和复数。对于整型
- 有符号 int8(8 位,1 个字节)、int16、int32 和 int64
- 无符号 uint8、uint16、uint32 和 uint64
- 还有对应特定 CPU 的 int 和 uint,在不同平台上可能为 32bit 或者 64 bit。
rune等同于 int32 用来表示 Unicodebyte等同于 uint8 通常用来表示原始数据uintptr无符号整数类型,用来存储指针,uintptr 通常用在更加底层编程
注意 int 和 int32 不是同一类型。
书中这边还介绍了运算符优先级和类型转换,进制转换的具体问题,详情可以参考。
Floating-Point 浮点类型
Go 提供了两种精度的浮点数 float32 和 float64 ,常量 math.MaxFloat32 表示 float32 能表示的最大数,math.MaxFloat64 同理。
float32 类型的浮点数可以提供大约 6 个十进制数的精度,而 float64 则可以提供约 15 个十进制数的精度;通常应该优先使用 float64 类型。
Complex Numbers 复数
Go 语言提供了两种精度的复数类型:complex64(8 字节) 和 complex128(16 个字节),分别对应 float32 和 float64 两种浮点数精度。内置的 complex 函数用于构建复数,real 和 imag 函数用来返回实部和虚部:
var x complex128 = complex(1,2) // 1+2i
var y complex128 = complex(3,4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
Booleans
布尔值只有两个值 true or false
Strings
字符串是不可变的字节序列,可以包含任何数据,通常文本会解释为 UTF8 编码 Unicode 。len 函数返回的是字节数目。
标准库中有四个包对字符串处理尤为重要:bytes、strings、strconv 和 unicode 包。strings 包提供了许多如字符串的查询、替换、比较、截断、拆分和合并等功能。
bytes 包也提供了很多类似功能的函数,但是针对和字符串有着相同结构的 []byte 类型。因为字符串是只读的,因此逐步构建字符串会导致很多分配和复制。在这种情况下,使用 bytes.Buffer 类型将会更有效,稍后我们将展示。
strconv 包提供了布尔型、整型数、浮点数和对应字符串的相互转换,还提供了双引号转义相关的转换。
unicode 包提供了 IsDigit、IsLetter、IsUpper 和 IsLower 等类似功能,它们用于给字符分类。每个函数有一个单一的 rune 类型的参数,然后返回一个布尔值。而像 ToUpper 和 ToLower 之类的转换函数将用于 rune 字符的大小写转换。所有的这些函数都是遵循 Unicode 标准定义的字母、数字等分类规范。strings 包也有类似的函数,它们是 ToUpper 和 ToLower,将原始字符串的每个字符都做相应的转换,然后返回新的字符串。
Constants
常量表达式在编译器计算,每种常量的潜在类型都是基础类型。
常量声明语句定义了常量的名字,常量值不能被修改。
const pi = 3.1415
或者
const (
e = 2.71
pi = 3.14
)
iota 常量生成器
常量声明可以使用 iota 常量生成器初始化,用于生成一组相似规则初始化的常量,const 语句中,第一个声明常量所在行,iota 会被置为 0,然后每行加一。
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
服务器监控整理
手上的 VPS 多余一台的时候总是想着通过一个统一的界面来监控管理。
需要监控的项
- VPS 及服务在线时间
- 从某地到该 VPS 的 ping 值稳定程度 [[smokeping]]
- 该 VPS 各项资源的使用情况,包括 CPU,内存,IO,网络带宽使用
之前也有分享过两个很不错的服务器监控程序 nodequery 和 netdata。之后又陆陆续续发现了其他一些不错的监控程序,所以就顺手整理一下。
商业方案,也就是提供服务在线监控,并且如果超过一定使用量向用户收取一定费用的服务:
- [[SyAgent]]
- [[EHEH]]
商业开源方案:
- [[Netdata]]
Netdata 也提供一个免费的云端 Netdata Cloud。
Self-hosted 方案,容器化方案,所有监控内容可以直接通过容器部署:
- [[dockprom]]
-
[[2021-08-28-nezha-monitor 哪吒监控安装及简单使用说明]] - [[uptime-kuma]]
- [[ServerStatus]]
SyAgent
SyAgent 是我在 LET 上面看到的一个选项,不过该网站由个人运营维护。
EHEH
EHEH 是一个闭源的监控平台,类似于 Nodequery,安全性待评估。
服务已经不存在。果然闭源的不可信啊。
dockprom
一个容器化解决方案,集成了 Prometheus, Grafana, cAdvisor 等等。
Zabbix
Zabbix 是一个企业级的开源监控方案。
GPL 开源协议。
Cockpit
[[Cockpit]] 是一款开源的 Linux 服务器管理解决方案。可以执行如启动容器,管理存储,配置网络,检查日志等操作。它能够同时控制和监控多台服务器。它提供的主要功能如:可视化的监控系统性能,管理 Docker 容器,终端窗口中基于 Web,管理用户帐号,收集系统配置和诊断信息,修改网络设置等。它的配置文档也很实用,可以快速安装并开始监控服务器。
nodequery
这一个产品只需要在服务器上安装一个脚本,该脚本会定时将 Linux 系统状态发送到 nodequery 的网站,在他的网站后台显示,界面非常简介,提供邮件报警服务,简单的使用完全没有任何问题。
唯一的问题就是该网站已经很多年没有更新,很担心后续是否能够继续使用。
担心的事情总是会发生,nodequery 已经停止了服务。
netdata
[[Netdata]] 是一款开源的监控程序,安装简单,安装之后会开启一个服务端口用来展示服务器状态,这个监控页面上各个参数都有非常好看的图表来展示。
主页:https://github.com/netdata/netdata
ServerStatus
上面两种监控方案需要针对每一台服务器进行安装,如果有多台服务器需要在统一的后台进行监控,那么可以选择 ServerStatus ,ServerStatus 是一个开源的监控系统,可以在同一个页面同时检测多台服务器流量,硬盘,内存等多个参数。
主页:https://github.com/BotoX/ServerStatus 中文版:https://github.com/cppla/ServerStatus
eZ Server Monitor
一款非常轻便的服务器监控程序,PHP 脚本。同时提供了 Bash 和 Web 版本。
主页:https://www.ezservermonitor.com/ 源码:https://github.com/shevabam/ezservermonitor-web
Nezha monitor
[[nezha 哪吒面板]] 是一款使用 Go 编写的服务器内存,CPU,网络使用情况的开源监控面板。
Datadog
Datadog 是一个企业级的服务监控,日志记录等等平台。
reference
由 WebM 格式学习常见的容器和编码格式
因为使用 YouTube 所以接触到了 WebM 格式,这个格式 Google 开源的一个媒体容器格式,常见的文件后缀名是 .webm,他设计的目标是为了给 HTML5 提供视频和音频。Google 发起的 WebM 项目还有一个姊妹项目 WebP 是提供图像编码的。BSD 协议开源。1
编码格式和容器格式
我们平常所见的媒体格式,有 avi,mp3,mp4,mkv 等等,但是这些都是媒体文件容器的扩展,WikiPedia 有一份比较完整的媒体容器列表,在这份列表中我们也能看到其实 webm 格式就是 Matroska 容器的一层“皮”,mkv 格式也是 Matroska 容器的。
而这里说的容器又被称为封装格式,就是将编码好的视频,音频按照一定的规范封装到一起。当然有些容器也支持字幕,脚本之类,同一种容器中可以放不同编码的视频。
容器格式和编码格式要区别开来,放在容器中的媒体可以有不同的编码格式,编码格式指的是用特定的压缩技术对视频,音频处理。但是有些容器也能够提供二次压缩处理。常见的编码格式有:mpeg-2,mpeg-4,h.263,h.264 等等。
常见容器格式
下面简要的说一些常见的容器格式。
WebM
WebM 容器是 Matroska 一种特殊的 profile,可以封装 VP8 视频编码, Vorbis 音频编码。在 2013 年支持了 VP9 视频编码,和 Opus 音频编码。
WebM 官网 https://www.webmproject.org/
AVI
AVI 全称 Audio Video Interleaved 音频视频交错格式,微软在 1992 年推出,采用有损压缩,压缩高,因此画质相对较差,但是应用仍然非常广泛,但是随着技术发展,逐渐被淘汰了。
MOV
MOV 是 QuickTime 格式,是 Apple 公司开发的音频、视频格式,和 AVI 格式几乎同一时间出现,现在也处于被淘汰状态。
RMVB/RM
这个格式是 Real Networks 公司所指定的音频视频压缩规范,可以根据不同的网络传输速率,而指定不同的压缩比率,从而实现低速率网络上的音视频实时传送,早起的 RMVB 格式是为了在有限带宽下在线播放视频而研发,曾经一度普及整个互联网。但现在也已经被淘汰。
MKV
MKV 是 Matroska Video 的简称,MKV 最大的特点就是能够容纳多种不同类型的视频、音频、和字幕格式。
Matroska 官网 https://www.matroska.org
MPG/MPEG
MPG 又被称为 MPEG (Moving Pictures Experts Group),是国际标准化组织认可的媒体封装格式,MPEG 一般指的是容器格式,而 MPEG-1, MPEG-2 一般是指编码格式。
一般的 MPEG4 容器封装了 H.264 编码格式,AAC 音频编码格式
Ogg
Ogg 是一个自由且开放标准的容器格式,Ogg 可以放入各种自由和开放源代码的编解码器 2, Ogg 通常用于一下编码
- Vorbis 可变比特率,16~500 kbit/s 的音频数据,有损
- Opus 通常用于音乐,以可变比特率处理语音,6~510kbit/s
- [[FLAC]] 无损
常见编码格式
通常情况下未编码的音频和视频内容都非常庞大,1080p 的视频一帧 1920*1080 像素大小,假设是 8 bit,一个像素 1 字节,那么一帧的大小就是 2M 大小,一般视频 1 秒为 30 帧,那么未压缩的视频几十秒钟就会达到 1Gb 大小,所以在存储时需要经过压缩。下面就是一些常见的视频压缩算法。关于更多视频编码概念的内容可以参考这里
MPEG-1
在 1992 年制定标准,针对 1.5Mbps 以下数据传输速率而设计的国际标准,也是 VCD 制作格式。用 MPEG-1 压缩算法,大致可以将 120 分钟的电影压缩到 1.2 GB 左右大小。
MPEG-2
标准定于 1994 年,设计目标为更高工业标准的图像质量和更高的传输速率,这种压缩算法主要用于 DVD 和 SVCD 制作,在高清电视和视频编辑也有广泛的应用。使用 MPEG-2 算法可以把 120 分钟的电影压缩到 4 到 8 GB 大小。
MPEG-4
标准定于 1998 年,为播放高清流媒体而设计,可以利用窄带宽,通过帧重建技术,压缩和传输数据,可以用最少的数据获得最清晰的图像质量。这种压缩算法包含了 MPEG 标准不具备的可变比特率,版权保护等功能。
这边可以额外说一下 mp3 音频压缩,指的是 MPEG-1 或者 MPEG-2 音频压缩的 Layer III3,并不是 MPEG-3。而为什么没有 MPEG-3 是因为 MPEG-2 已经足够满足 MPEG-3 提出的目标 4,所以这个 MPEG-3 标准就被废除了。
H.264
H.264 也是 MPEG-4 第十部分,因此也叫 ISO/IEC 14496-10,或者叫做 MPEG-4 AVC,MPEG-4 Part 10 。H.264 也是 MPEG-4 的一部分。
H.264 最大的优势是很高的压缩比率,在同等画质下,H.264 压缩比是 MPEG-2 的 2 倍以上,是 MPEG-4 的 1.5 到 2 倍。H.264 需要授权付费使用。
H.265
是 H.264 的升级版,在保证画质的情况下拥有更高的压缩率。也是授权使用。
常见音频编码格式
通常情况一个媒体文件必定是有视频和音频的,而上面提到的媒体容器中有些也是支持多音频编码轨的,比如说常见的电影可能包含多个国家语言音轨,而常见的 KTV 媒体格式可能需要包含一个原声轨,一个音频轨道。
AAC
AAC 是 Advanced Audio Coding,高级音频编码,出现于 1997 年,基于 MPEG-2 音频编码技术,由 Fraunhofer IIS、杜比实验室、AT&T、Sony(索尼)等公司共同开发,目的是取代 MP3 格式。2000 年,MPEG-4 标准出现后,AAC 重新集成了其特性,加入了 SBR 技术和 PS 技术,为了区别于传统的 MPEG-2 AAC 又称为 MPEG-4 AAC. 相关的规范标准分别是 ISO/IEC 13818-7,ISO/IEC 14496-3 作为一种高压缩比的音频压缩算法,AAC 压缩比通常为 18:1,也有数据说为 20:1,远胜 mp3。
在音质方面,由于采用多声道,和使用低复杂性的描述方式,使其比几乎所有的传统编码方式在同规格的情况下更胜一筹。AAC 可以支持多达 48 个音轨,15 个低频(LFE)音轨,5.1 多声道支持,更高的采样率(最高可达 96kHz,音频 CD 为 44.1kHz)和更高的采样精度(支持 8bit、16bit、24bit、32bit,音频 CD 为 16bit)以及有多种语言的兼容能力,更高的解码效率,一般来说,AAC 可以在对比 MP3 文件缩小 30% 的前提下提供更好的音质
AC-3
Digital Audio Compression Standard 杜比实验室出品,有损压缩,可以包含 6 个独立声道。最著名的是 5.1 声道, 5 代表 5 个基本声道,可以独立连接五个不同音箱,右前 RF,中 C,左前 LF,右后 RR,左后 LR,1 则代表一个低频声效,连接低音辅助音箱(20 到 120Hz),开源解码库 liba52.
APE
APE 是 Monkey’s Audio 提供的一种无损压缩格式,APE 可以无损失高音质地压缩和还原。APE 的压缩率相当高,并且音质保持得很好,获得了不少发烧用户的青睐
DTS
DTS 是 Digital Theater Systems ,数码影院系统,由 DTS 公司开发,是一种多通道音频技术,低损,环绕立体声,被广泛应用入 DVD 等高清片源上。需要授权,和杜比公司是竞争对手,常见的是 DTS 5.1,保存 5 条音频通道数据用于立体环绕声,分别是 center, left-front, right-front, left-rear, and right-rear。
FLAC
FLAC 是 Free Lossless Audio Codec,开源无损压缩编码格式,不会破坏任何原有音频,可以还原光碟音质,被很多软件硬件产品支持。
官网: http://flac.sourceforge.net/
MP3
MPEG-1 or MPEG-2 Audio Layer III 经常被称作 MP3,是目前最流行的音频编码格式,有损压缩,相关的规范标准在 ISO/IEC 11172-3, ISO/IEC 13818-3。它设计用来大幅度地降低音频数据量,将音乐以 1:10 甚至 1:12 压缩。mp3 的比特率是可变的,在高声中包含的原始信息越多,回放时品质也越高。
根据比特率,MP3 可以分为
- MP3-CBR,固定码率
- MP3-VBR,动态码率
Opus
Opus 是一个有损编码格式,适用于网络低延迟,实时声音传输,标准 RFC 6716。Opus 是开放格式,没有专利和限制,目标希望去代替 Speex 和 Vorbis。
2018 年 10 月,Xiph.Org 基金会开发了 Opus 1.3 版本,改进了语音和音乐质量,兼容 RFC 6716,该版本首次加入环绕立体声格式 Ambisonics 支持。5
总结
在归纳了目前市面上常见的媒体文件容器和编码之后,我们应该知道 WebM 是一个媒体容器,在 YouTube 上应用广泛。WebM 容器可以放入不同编码的音视频流,所以在下载了一个 webm 的文件之后可以使用
ffmpeg -i file.webm
来查看容器中的媒体文件,就我个人情况,因为 YouTube 很大一部分是用户上传,所以有些情况下 YouTube 的音频还是会选用 aac 编码,当然我也遇到过 opus。
reference
读万字访谈后感:软硬件公司的差别
9 月份一次出门在路上看了这篇万字采访,这篇文章主要以 Osterloh (Google 硬件部门 Leader)为脉络梳理了 Google 这几年在 硬件方面的尝试。文章中的观点并不是那么直白,但是看完却有一股气憋在心中不得不抒。作为用 Google 产品这么多年的忠实用户,Galaxy Nexus,Nexus 6 也是陪我度过了很多年,而 Google Glass 当年如何的红火,但是不得不说在 Google 在硬件确实不如其软件行业的发展,现在音箱被 Amazon Echo 压着打,手机不管是 Nexus 还是 Pixel 丝毫无法动摇 iPhone 的地位,更不用说失败的 Nexus Q,Android TV,等等。
Google 为什么做不好硬件
这篇文章其实并没有直接点明为什么 Google 做不好硬件,但是文章展示的一些细节中我们就能看出一些端倪。其中很重要的一点就是 Google 企业文化的障碍。文中这样说
发布和迭代根本不适用于硬件
Google 更擅长的是快速发布产品,在迭代中快速更新产品,然而硬件不是软件,不能直接通过云端更新就让设备焕然一新,文章中说的,调整每一个细节都有可能需要改变供应商的时间表。
在苹果,软件管理人员总是在考虑特定的产品;软件工程高级副总裁 Craig Federighi 的目标是让 iPhone 变得更棒;而 Google 优先事项总是试图同时支持自己的产品,合作伙伴和整个互联网。
上面这番话让我对软硬件区别有了更深的了解,习惯了软件思维,所以总是想着尽快地发布,但其实不论做软件产品还是做硬件产品,只有当产品足够完美再去发布。近十几年的软件行业总是越来越快,恨不得今天的电子,明天就要发布。然而事实上观察那些成功的产品,总会在发布的最初的版本就定下了未来几年甚至十几年的形态,发布之后最多也只是修修补补,反而是那些不怎么成功的产品,每隔几个月增加一些功能,每隔一年改一次版,或许有人也要反驳,正是互联网的快速迭代更新的能力,才有了让产品试错的可能,才能让产品在试错中找到发展的道路。但其实往往这样的产品,在迭代过程中丢失了初衷,在一次次尝试过程中磨损了激情和动力。
Google Glass,Nexus Q 本来可以更完美,但却在一个错误的时间,错误的场合发布,最终不了了之。
硬件和 AI 结合
有些时候确实无法去反驳这一条看似真理的话,将硬件设备和机器学习,AI 相结合,在文章中提到
在语音技术的早期阶段,用户很难找出语音助手除了设置定时器和播放音乐之外可以做什么。
智能助手 Siri 被提出之后,Amazon 有 Alex, Google 曾经有过 Google Now,Google Now on Tap,最后演变为 Google Assistant,语音助手真正成为了一个手机不可或缺的一部分。但是观察近些年这些巨头对这个“产品”的态度可以明显的看到差别,因为 Alex 并没有大规模的在手机上使用,就略过,就现在两大操作系统 Android 和 iOS 上的 Google Assistant 和 Siri 来看。Google 一心想要将 Assistant 打造的无所不能,无所不在,而 Siri 却慢慢的将控制的权利交给用户,比如在 iOS 12 中让用户自定义“捷径”。就两个产品的进化而言其实都没有错,但是无疑在 AI 并不完善的现在让 AI 不知所措甚至不如让 AI 遵循用户定义好的快捷方式来的有效。
无可置疑 Google 助手的能力要远远强于 Siri ,然而在使用的过程中非常直观的体验就是,让 Google Assistant 关掉 Wifi 都那么费劲(当然这是说的早期的时候)。或许这也是 Google 无法控制硬件带来的问题。很多人对比这些助手的时候总是哪一些,金门大桥多长多长,现在的总统是谁来提问,然而现实中大部分的问题这些助手都无法回答,而从地球到月球有多远这样的问题出现频率又有多高呢?
我想象中的手机助手至少应该能够控制手机中频繁操作的功能,比如设置提醒,设置日历,发送 SNS 消息,又比如控制 Wifi,流量开关等等。我曾记得之前看到过一些文章,介绍了产品功能在设计的时候要考虑到用户的期待。比如说用户按下一个按钮之后会发生什么,再比如说用户问完一个问题之后期待的答案。iOS 在 12 中更新的捷径,让用户自定义助手的处理,虽然门槛稍高,但却完美的避免了这一个答非所问的尴尬。
苹果公司近两年的一系列收购,Workflow,音乐识别应用 Shazam1,音乐分析引擎 Asaii 2,可以预期的是这些产品会和 Siri 甚至是 iPhone 整个产品线结合的更加紧密。这一方面弥补了软件方面的不足,另一方面也让硬件产品更加完美。
废话说了那么多,这只是对最近 Google 关停 Google+,又是审查版搜索不满的一顿发泄而已。Google 已经不是那个时候的 Google 了,倒是如今的微软,苹果更值得关心一下。
reference
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。