Jupyter 简单使用
Jupyter 是一个为了支持多语言交互式编程的项目, Jupyter Notebook 是一个开源的网络程序,允许用户创建和分享包含代码,视图,方程式,文本的文档。
- Notebook documents 是应用产生的文档
- Jupyter Notebook App 是一个服务端应用,可以让用户在浏览器编辑和运行 notebook documents
- Notebook Kernel 是计算引擎,执行 Notebook document 中的代码
- Dashboard 控制面板
Jupyter 支持超过 40 中编程语言,可以轻松通过各种格式分享笔记,代码可以生成丰富的交互输出,包括 HTML,图像,视频,LaTeX 等等。
安装 Notebook
如果有 Python 环境,比较简答,可以按照官方的文档执行
简单的安装:
pip install jupyter
或者使用官方推荐的 Anaconda 安装。
运行
执行如下代码运行
jupyter notebook
jupyter 是支持 TAB 补全的。
常用快捷键
- Ctrl + Enter 执行单元格代码
- Shift + Enter 执行单元格代码并且移动到下一个单元格
- Alt + Enter 执行单元格代码,新建并移动到下一个单元格
Jupyter 能够用来做什么
Jupyter 能够
- 数据清理,转换
- 数值模拟
- 建模统计
- 数据可视化
- 机器学习
- 用于教育
reference
- https://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/what_is_jupyter.html
- https://www.youtube.com/watch?v=HW29067qVWk
- https://www.zhihu.com/question/37490497
- https://zhuanlan.zhihu.com/p/33105153
- https://blog.csdn.net/Lee_J_R/article/details/52791228
GraphQL 初识
在开发服务端接口的时候接触到 GraphQL 这个名词,故而有了这篇文章。因为初始,所以整理过程难免有些错误和疏漏,请留言告知。在我们面对一个新的名词,或者一门新的技术时,了解的过程可以分成这么几部分,他是什么,他解决了什么问题,他和目前同类型的技术相比优势在哪里,这样几个部分去看也就能够比较粗略,但是快速的了解一样新东西了。所以这篇文章的组织结构也以这样的方式进行。
GraphQL 是什么
GraphQL,很容易让人想起来 SQL,其实也很类似,可以理解为是一门查询语句,但和 SQL 不同的是,SQL 是查询关系型数据库,而 GraphQL 是查询 WEB 服务数据。GraphQL 是有 Facebook 开发开源,设计主要是为了解决 RESTful 接口的不足。
RESTful 在设计时,将互联网上的每一个内容都理解为资源,通过 HTTP 不同的请求方法来对资源进行增删改查,而 GraphQL 则是通过客户端自主使用查询语句来获得资源。GraphQL 并不是一门语言或者框架,而是请求数据的一种规范,协议。GraphQL 本身并不直接提供存储管理功能,也不和任何数据库绑定。
GraphQL 解决了什么问题
RESTful 接口遇到的问题
- RESTful 接口数据格式由后端约定,调用者无法修改数据格式,只能够做适配和容错
- 难以维护,因为 RESTful 固有的属性,服务和资源提供接口,所以随着系统和业务变化,RESTful 接口数量会爆炸式增长,不利于维护
- 创建大而全的接口不仅影响调用速度,也浪费了移动端传输流量
- 很多情况下客户端只需要某一个接口中特殊几个字段,但是 RESTful 会将整个数据格式返回
- RESTful 接口在开发时需要相应的维护一套文档,而更新接口时可能导致文档修改不同步
特点
GraphQL 有如下特点:
- 强类型,所有类型都需要预先定义
- 服务端根据客户端提供的查询语句返回对应的 JSON
GraphQL 对外提供只有一个接口,所有请求通过该接口处理,GraphQL 内部做了路由处理。查询语句主要分为两大类,Query 查询,Mutation 修改(非幂等操作,post,put,delete 等)
比如客户端有如下查询语句
query {
user(id: 1) {
id
name
}
}
服务端返回
{
"data": {
"user": {
"id": "1",
"name": "Uncle Charlie"
}
}
}
服务端会返回一个和查询一致的 JSON 字串。
关于 GraphQL 的类型系统,标量类型,对象类型那就自行查看文档即可。
如果你看到这里想要亲手体验一下,那么可以访问 GitHub 提供的在线查询工具
GraphQL 和 RESTful 比较
针对上面 RESTful 出现的问题 GraphQL 的解决方案:
- GraphQL 是强类型定义,接口 Schema 的类型是需要前后端事先约定的
- GraphQL 不会随着业务发展而接口数量暴增,GraphQL 只暴露一个接口,所以这个接口是数据库,缓存,服务的 Facade.
- GraphQL 的调用完全由客户端控制,不会产生无用传输流量
- GraphQL 会根据定义好的类型系统自动生成说明文档,省去了文档同步更新的麻烦
GraphQL 思考模式
使用 GraphQL 接口设计获取数据步骤:
- 设计数据模型,用来描述数据对象
- 前端使用模式查询语言 Schema 来描述请求数据对象类型和具体需要的字段
- 后端 GraphQL 通过请求,根据需要,自动组装数据字段,返回前端
其他语言扩展
Python
- https://medium.com/@fasterpancakes/graphql-server-up-and-running-with-50-lines-of-python-85e8ada9f637
- https://graphene-python.org
JS
其他扩展
- https://github.com/facebook/graphql
- http://graphql.org/
- 生成 GraphQL 接口示意图 voyager https://github.com/APIs-guru/graphql-voyager
- 数据查询优化 https://github.com/facebook/dataloader
- prisma 框架,在 GraphQL 基础上构建,与 GraphQL 兼容,可以当做 ORM 与数据库交互
- 在浏览器中使用查询语句 GraphiQL https://github.com/graphql/graphiql
- GraphQL 对各个语言的支持
reference
MySQL 配置优化
开启慢查询日志
查看慢查询日志
show variables like '%slow_query_log%';
set global slow_query_log=1;
使用上述方式修改,重启 MySQL 后修改丢失,如果要永久生效,需要修改 my.cnf 文件
slow_query_log = 1
slow_query_log_file = /tmp/mysql_slow.log
Go 语言学习笔记 2:基本结构
和大部分编程语言一样,Go 也有很多内置关键字,下面这些关键字和语法相关,不能用于定义。
break
case
chan
const
continue
default
defer
else
fallthrough
for
func
go
goto
if
import
interface
map
package
range
return
select
struct
switch
type
var
三大类预定义的关键字
| 分类 | 关键字 |
|---|---|
| Constants: | true false iota nil |
| Types: | int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr float32 float64 complex128 complex64 bool byte rune string error |
| Functions: | make len cap new append copy close delete complex real imag panic recover |
上面这些可以用于定义。
变量定义
变量定义遵循
var name type = expression
type (类型)可以省略
var name, age, gender = "EV", 18, 1
或者:
var (
name = "EV"
age = 18
gender = 1
)
type 会自动推导
变量只能被声明一次。
Short Variable Declarations
定义简短的写法,只能在函数内部使用
name := expression
这种写法可以省略 var 关键字。
注意 := 是变量声明,而 = 是赋值。
short variable declaration 不是总是定义左边的变量,当在同一个作用域,已经声明过的变量,那么 := 表现为赋值。
枚举
Go 语言不提供枚举类型,不过可以使用常量+iota 来模拟枚举:
const (
E1 int = iota
E2
E3
)
这三个变量分别是 0,1,2
指针
variable 是包含值的一块内存区域,pointer 值是 variable 的地址,指针指向变量真正存储值的地方。不是每一个 value 都有地址,但是每一个变量都有地址。即使在不知道变量名的情况下,可以通过指针间接地读写变量相关的 value。
变量定义为 var x int, 表达式 &x 是取变量 x 的地址,会返回一个指针 *int ,读做指向 int 的指针。假设变量 b 来持有 *int:
x := 1
p := &x // p, of type *int, points to x
fmt.Println(*p) // "1"
*p = 2
fmt.Println(*p) // "2"
指针的 zero value 是 nil. 如果指针指向一个变量 那么 p != nil 为 true。
var x, y int
fmt.Println(&x == &x, &x == &y, &x == nil)
使用 new 方法定义
另外一种创建 variable 的方法是使用内置方法 new, 表达式 new(T) 会创建一个类型 T 的 unnamed variable,并且将类型 T 使用 zero value 初始化,然后返回指向该值的指针,也就是 *T。
p := new(int)
fmt.Println(*p) // "0"
*p = 2
fmt.Println(*p) // "2"
使用 new 方法创建,除了没有变量名字和普通创建没有什么差别。所以下面两个方法等同
func newInt() *int {
return new(int)
}
func newInt() *int {
var dummy int
return &dummy
}
变量的生命周期
- 包变量一直常驻在内存到程序的结束,然后被系统垃圾回收器回收。
- 局部变量,一直生存,直到没有外部指针,或者函数退出,没有路径可以访问到该变量
赋值
赋值其实没啥好说的,任何语言都不可或缺。
但是 Go 支持 元组赋值 Tuple Assignment,那么就可以和 Python 一样,允许多个值一起被赋值
x, y = y, x
类型定义
类型定义
type name underlying-type
type Celsius float64
包和文件
Go 语言中的包 (package) 和其他语言中的 库(libraries),或者模块(module)作用是一样的,为了支持模块化,封装和重用。
Go 中的包让我们控制内部名字是否暴露给外部。就和之前说的那样,大写字母开头的会暴露给外部。
当一个 go 文件包名为 main, 那么就是告诉 go 编译程序,这是一个可执行程序,go 编译器就会尝试将它编译为一个二进制文件。
导入包
导入包需要用到 import 关键字。
import "fmt"
import "net/http"
Go 编译器会去 Go 的环境变量 GOROOT 和 GOPATH 中寻找导入的内容。关于这两个环境变量可以参考上一篇文章。
Go 也支持远程导入包,比如导入 github 上的包
import "github.com/xxx/xxx"
go get 工具可以递归获取依赖。
重命名导入的包
import (
"fmt"
myfmt "mylib/fmt"
)
初始化包
每个包都可以包含多个 init 函数,每个 init 函数都会在 main 函数之前执行,init 函数通常用来做初始化变量,设置包等初始化工作。
Scope
作用域,不要和生命周期搞混,变量声明的作用域是编译期的概念,而变量的生命周期是运行时概念。
一个句法上的块 (block)指的是花括号包围的一组语句。
func f() {}
var g = "g"
func main() {
f := "f"
fmt.Println(f) // "f"; local var f shadows package-level func f
fmt.Println(g) // "g"; package-level var
fmt.Println(h) // compile error: undefined: h
}
reference
- 《The Go Programming Language 2015》
go 语言学习笔记 1:基本介绍和使用
Go 语言特性:
- 静态语言
- 函数支持多返回值
- 错误处理机制
- 支持语言并发
- 面向对象:使用类型,组合,接口来实现面向对象思想
- 反射
- CGO,可以调用 C 语言实现的模块
- 自动垃圾回收
- 静态编译
- 交叉编译
- BSD 开源协议
并发
Go 语言在语言级别支持[[Coroutine|协程]],叫 [[Goroutine]]。Go 语言标准库提供的所有系统调用 (syscall) 操作,当然也包括所有同步 IO 操作,都会出让 CPU 给其他 goroutine
Go 语言推荐采用“Erlang 风格的并发模型”的编程范式来实现进程间通信。
编码风格
要求 public 变量以大写字母开头,private 变量以小写字母开头。
花括号写法,还有错误处理,都有详细的规定。Go 语言也是至今为止学习的语言中,唯一一个将编码风格写入语言要求的。
变量
对于 Go 的变量,推荐使用 ` 驼峰式 `
Go 语言标识命名规则:
- 只能由非空 Unicode,数字,下划线组成(所以 Go 语言中可以使用中文作为变量名,但是不建议)
- 只能以字母或下划线开始
- 区分大小写,避免使用 Go 语言预定义标识符
包名
包名要求小写。
编程哲学
Go 语言反对重载,反对继承,反对虚函数和虚函数重载,Go 提供了继承但是使用组合文法提供。
Go 语言是静态类型语言。
语言特性
一些值得提前了解的语言特性
- 垃圾回收
- 内置 map 类型,支持数组切片
- 函数多返回值,这一点和动态语言的 Python 有些相像
- 错误处理,Go 语言引入了 defer,panic 和 recover 三个关键字来处理错误。
- 匿名函数和闭包,函数也是值类型,可以传递
- 类型和接口,Go 语言的类型定义非常接近 C 语言中的结构 struct,但是 Go 语言没有沿袭 C++ 和 Java 传统构造一个复杂类型系统,不支持继承和重载,只支持基本的类型组合。
并发编程
Go 语言引入 goroutine 概念,关键字 go, 可以让函数以 goroutine 协程方式执行。Go 语言使用 channel 来实现通信顺序进程(CSP,Communicating Sequential Process)模型,方便跨 goroutine 通信。
安装使用
Linux 安装
从 这里 下载,然后解压并添加环境变量
tar -C /usr/local -xzf go1.18.3.linux-amd64.tar.gz
export PATH=$PATH:/usr/local/go/bin
然后设置 GOPATH 环境变量
安装 C 相关工具
sudo apt-get install bison ed gawk gcc libc6-dev make
macOS 下安装
在 macOS 下安装:
brew install go
可以使用 go version 来验证是否安装成功。
安装目录
在安装好的 Go 目录下,有几个重要的目录
/bin,可执行文件,编译器,Go 语言相关工具/doc,文档/lib,文档模板/misc,支持 Go 编辑器相关配置/os_arch包含标准库包对象文件.a/src,源代码/src/cmd,Go 和 C 编译器和命令行脚本
几个重要的环境变量
$GOROOT表示该 go 的安装目录,值一般都是/usr/local/, 当然,也可以安装在别的地方$GOARCH表示目标机器的处理器架构,它的值可以是 386、amd64 或 arm$GOOS表示目标机器的操作系统,它的值可以是 arwin、freebsd、linux 或 windows$GOPATH采用和$GOROOT一样的值,但从 Go 1.11 本开始,你必须修改为其它路径。它可以包含多个包含 Go 语言源码文件、包文件和可执行文件的路径,而这些路径下又必须分别包含三个规定的目录:src、pkg和bin, 这三个目录分别用于存放源码文件、包文件和可执行文件
GOPATH 可以理解成工作目录,一般需要包括 3 个文件夹:
src源文件,通过包名区分pkg编译后的文件bin可执行文件(go install),只需要将$GOPATH/bin加入环境变量就可以在操作系统任意位置执行
Hello World
创建一个 workspace,然后开始 hello world,在 workspace 下新建 src/hello 目录,在目录下创建文件 vim hello.go
package main
import "fmt"
func main() {
fmt.Printf("hello, world\n")
}
退出文件,在 hello 目录下执行 go build,此时会生成一二可执行文件 hello,执行 ./hello 可以看到输出。
- 每个 Go 源代码文件的开头都是一个 package 声明,表示该 Go 代码所属的包
- 在包声明之后,是一系列的 import 语句,用于导入该程序所依赖的包,不得包含在源代码文件中没有用到的包,否则 Go 编译器会报编译错误
- Go 语言的 main() 函数不能带参数,也不能定义返回值。命令行传入的参数在 os.Args 变量中保存。
函数体定义
func 函数名(参数列表)(返回值列表) {
// 函数体
}
如果不进行编译,也可以直接 go run hello.go 来运行。
类型系统
在 Go 语言中有四个关键字和定义类型相关,var,const,type 和 func 前两个和变量相关,第三个可以用来自定义类型,func 定义方法。
- 内置常量:true, false, nil, iota
- 内置类型:bool, byte, rune, int, int8, int16, int32, int64, uint, unit8 …, float32, …
- 内置函数:make, len, cap, new, append, copy, close, delete, complex, real, imag, panic, revoer,
- 空白标识符:
_
内置类型
和其他强类型语言一样,Go 语言内置一些基础类型,比如 Strings,Numbers(int32,int64,float32,float64 等等),Booleans。这些类型本质上是原始类型。当对值进行增加或者删除市,会创建一个新值。当把这些值传递给方法时,会传递一个对应值的副本。
引用类型
Go 语言中有下面几个引用类型:切片、映射、通道、接口和函数类型。当声明上述类型时,创建的变量被称为标头(header)值,每个引用类型创建的标头值是包含一个指向底层数据结构的指针。
header 中包含一个指针,通过复制来传递一个引用类型的值的副本。
结构类型
结构类型用来描述一组数据值。
保留字
Go 语言有很多保留字
- 声明:import, package
- 实体声明和定义:chan, const, func, interface, map, struct, type, var
- 流程控制:break, case, continue, default, defer, else, fallthrough, for, go, goto, if, range, return, select, switch
变量
在 Go 语言中变量初始化和变量赋值是不同的概念。
常见的语法,比如:
var var2 = 10
var3 := 11
这里 := 表示同时进行变量声明和初始化。出现在 := 左侧的变量不应该是已经被声明过的。
操作符
- 算术运算符:+, -,
*,/, %, ++, – - 关系: >, < …
-
逻辑运算符: &&, , ! -
位运算符:&, , ^, « , » , &^ -
赋值运算符:=, +=, -=, *=, %=, &=, =, ^=, «=, »= - 其他运算符:
<-
声明语句
- 声明变量 var
- 常量 const
const PI = 3.14 - 方法 func
- 类型 type
最后
我们对于一些事物的不理解或者畏惧,原因都在于这些事情所有意无意带有的绚丽外衣和神秘面纱。只要揭开这一层直达本质,就会发现一切其实都很简单。
reference
- 《Go 语言编程》
- 《Go 语言实战》
- https://tour.golang.org/basics/1
- https://blog.opskumu.com/go-programming-language.html
跨平台开源卡片记忆工具 Anki
在最开始了解到这个应用的时候,我无法简单地用一句话来形容这个应用,大部分人将它称为背单词软件,单词记忆应用,部分人有拿他作为知识管理应用,甚至有人拿他来学习乐谱,诗歌,但总之如果要用简单的话来描述这个软件,那么跨平台必定是关键词,另外一个关键词就是卡片(flash card),在另外一个就是循环记忆,那么至于卡片上承载什么样的内容,就完全由用户来决定了。
德国心理学家[[莱特纳]]在 1970 年出版了他一部重要的著作《How to learn to learn》,他在这本书中引用艾宾豪斯的遗忘曲线,发明了「莱特纳系统」,也就是「间隔式复习」的方法,让记忆达到最佳。
[[Anki]] 就是间隔式复习的一个实现方式。Anki 中通过模拟卡片的前后两面,通过内置的算法,间隔记忆卡片的内容,可以在卡片上写任何内容。
很长一段时间内我都无法很好的尝试使用 [[Anki]] 来进行记忆,烦恼我的一点理由就是 Anki 的卡片制作过程,我知道很多人都说学习记忆是在卡片制作过程中,但是我发现制作卡片花费的时间已经超过我使用纸张来记录的时间。所以很长一段时间内 Anki 就躺在我所有的设备上,虽然偶尔会打开一下,但是依然没有养成每天记忆的习惯,反而在其他背单词软件中坚持了下来。但是在使用线程的单词记忆软件的时候,我不时的会想起 Anki 来,也渐渐地发现线程的单词记忆软件有其自身的缺点,而这个缺点正是 Anki 可以弥补的(虽然可能需要花费一些时间来熟悉 Anki)。
Anki 背后的两个思想
- 主动召回
- 主动召回就是通过提问,回答来记忆,用户主动回答问题。主动召回会激活大脑中的多个区域,迫使用户去思考和理解信息,有助于将新信息和现有知识建立链接
- 记忆的时候有很多方法,
- 被动回顾,翻书,被单词,被动的阅读,听或者看。
- 联想法,通过联想记忆
- 打桩记忆法,将要记忆的东西和所熟悉的事物联系起来记忆
- 蔡格尼克记忆效应,人们对于尚未处理完的事情,比已处理完成的事情印象更加深刻
- [[费曼学习法]],适合学习语法,输出是最好的输入
- 间隔重复
- [[间隔式复习]] 的目的,就是让被记住的内容可以间隔比较长时间再复习; 对于快速忘记的内容在间隔比较短的时间就复习; 透过复习的手段让所有学过的内容都越忘越慢,几次反覆下来,就可以达成完全记住的目的。
一些使用的误区
比如使用通常的软件来背单词,优势在于这些软件可能事先已经准备好了单词集,发音,例句,讲解等等,然而在使用过程中就会发现这些东西始终是字面上的东西,即使记忆了和多遍,依然没有被录入到自己的脑袋里。反而有些时候,比如某一次到异国他乡遇到的一个单词,像烙印一样深深地印在脑子里,每一次想到这地方脑海里便会回忆起这个单词。丝毫没有可以去记忆,但潜意识中就已经将这个单词记忆下来了。所以这个时候我又想起了 Anki,对于想要记忆的东西,不妨用自己的语言描述放到 Anki 的背后,写一段故事也好,描述一个场景也好,自己写下来的东西,每次翻到的时候记忆总是要比别人准备好的东西要深刻。
另外一个使用 Anki 的误区便是,当你发现你在制作卡片时陷入了不间断的 Copy/Paste ,那么请立即停下来,就像 这里 说的那样,首先去理解你要记忆的东西,否则你会陷入无限的知识债务。这一点和做笔记的时候不停摘录而不去消化,买书屯书而不读是一样的,理解了才能真正成为你自己的东西。
end up accruing a lot of ‘knowledge debt’ that you’ll have to pay for down the line.
应该花费更多的时间来理解需要记忆的内容,而不是在制作卡片上。当对内容理解越深刻,那么以后 reviewing 或者 recalling 的时候花费的时间也会减少。
下载
官方网站:
下载解压之后有 README,看其中说明,安装即可。
使用场景
任何需要记忆的内容都可以使用 Anki 帮助进行,Anki 不感知内容,支持图像,音频,视频,甚至科学符号(LaTeX),比如你可以使用 Anki:
- 学习一门语言,通过 Anki 背诵记忆单词,学习语法知识
- 准备医学或者法律考试
- 记忆人的名字或者脸
- 记忆长段的诗歌
- 甚至记住吉他的和弦
- 学习哲学家的主要观点
理念
Anki 背后的理念:
- active recall testing 主动召回测试,制作和使用卡片正面的问题去记忆背后的内容
- spaced repetition,间隔重复,通过记忆程度来不断设置复习时间间隔
几个概念
官方文档已经非常细致,可以直接 阅读 ,这边只列举一些比较重要的内容。
- Cards 卡片
- Deck 卡组,包含卡片的集合,可以导出为
apkg文件
Cards
卡片,Anki 的核心概念,正面问题,背面答案,或者正面单词,背面解释。
Deck
来自朗文的解释:a set of playing cards,翻译为一组卡牌
Profile
朗文的解释:a short description that gives important details about a person, a group of people, or a place,翻译为档案,介绍也都可以,在 Anki 的 File 菜单中,可以切换 Profile,不至于导入别人的卡牌之后弄乱自己的设置,或者自己在使用时也可以根据不同的场景定义不同的 Profile。
学习
学习过程中,打开 Decks 可以看到一个 Overview,卡片的种类被分为三种类型:
- New, never been studied before
- Learning, cards have been seen for the first time recently, and are still being learnt
- To Review, cards were previously learnt, and now need to be reviewed so you don’t forget them
首次学习
进入到卡片学习,底部会有多个按钮,第一次学习的卡片会出现三个按钮:
- Again moves the card back to the first step
- Good moves the card to the next step.
- Easy immediately converts the card into a review card, even if there were steps remaining
Reviewing
再次学习一个卡片的时候,也就是 review 阶段时,有四个按钮
- Again,let Anki to show the card more frequently in the future
- Hard,shows the card at a slightly longer delay than last time, and tells Anki to show the card more frequently in the future.
- Good, tells Anki that the last delay was about right
- Easy, tells Anki you found the delay too short
上面的按钮对应的快捷键是 1,2,3,4。
每一张卡片都会经历三个阶段:新卡片、学习中、结束。
其他
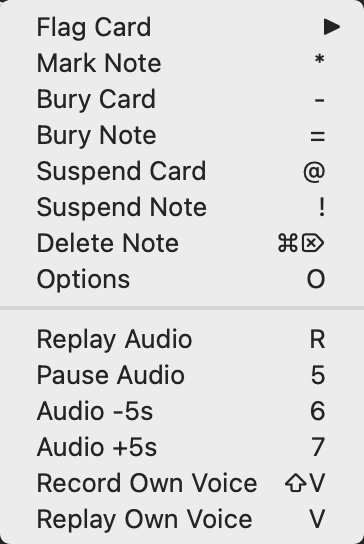
- Flag Card: 标记卡片,为卡片增加或删除一个彩色标记。
- Mark Note: 标记笔记,为当前笔记添加 marked 标签
- Bury Card / Note: 搁置卡片 / 笔记,从复习队列中隐藏卡片或笔记,直到第二天
- Suspend Card / Note: 暂停卡片/笔记,暂时不想某笔记,又不想删除它的时候
- Delete Note: 删除笔记
Bury card
Bury card 表示暂时不显示该卡片,但是该卡片会在之后再显示出来。
这个模式适用于,比如当前的卡片暂时不想记忆,然后类比就是将此卡片直接放到了牌堆的最后。但是随着复习总有一点还是会复习到此卡片。
Suspend Card
Suspend Card 表示将此卡片移除牌组,永远也不回再展示,直到用户手动 unsuspend 才会继续放入牌组。
这个模式适用于,比如某个阶段不想记忆某个卡片,直接将此卡片移走的情况。比如说如果发现卡片存在错误,需要手动进行修复一下,那么就可以先标记 suspend 然后继续。
学习资源
官网那一定是最全的,包含各国语言
插件
Add-ons
推荐几个(只适用于我目前使用的 2.1 版本,随着时间变化,下面的 id 可能失效):
- 900455869 TTS 发音
- 1612375712 触发全屏
- 2055492159 AnkiConnect
- 775418273 WordQuery https://github.com/finalion/WordQuery 用来简化制作卡片的过程,查询单词立即自动制作卡片,支持从 mdx stardict 字典中直接检索,支持网络字典
AnkiConnect
[[AnkiConnect]]源码地址:https://github.com/FooSoft/anki-connect
这个插件将 Anki 的功能暴露一份 RESTful 接口,这样就可以用接口方式来操纵 Anki。安装开启该插件后会监听 8765,默认绑定 HTTP 服务到 127.0.0.1,只有本机可以访问该服务。如果想要其他网络访问,可以设置环境变量 ANKICONNECT_BIND_ADDRESS 为 0.0.0.0。
FastWordQuery
可以从不同的来源将词添加到 Anki
自动化制作卡片
Saladict to Anki
2021 年更新
之前推荐的 Chrome to Anki 插件已经很久没有更新,所以又找到了 Saladict 这样一款插件,在设置中可以很方便地找到如何连接 Anki。
Chrome to Anki
需要借助一款 Chrome 插件
和一个 Anki 插件
这两个插件都是开源 12 的,看官方的说明也很简单就略过了。
GoldenDict to Anki
虽然目前一直在寻找方法能够间 GoldenDict 查词记录自动制作卡片到 Anki,但是目前尚未找到合适的方法,虽然有了解到可以使用 mdx-sever 共享一个 HTTP 服务,然后使用上面的方法自动制作,但感觉依然有些麻烦。Anki 上的卡片还是自己手动创建比较稳妥。
Kindle to Anki
对于 Kindle 我很少将它连到电脑上做导出导入的事情,所以这个不准备弄了。
如果对于 Kindle 有重度依赖,并且希望使用 Anki 的方式来整理标注的话,可以试试 ankindle 这样一个插件,可以导出单词和标注,并且制作成 flashcard 用来记忆。
Tips
几个小小的 tips.
Add-ons固然是非常有用,非常强大的,但是千万不要在上面花费过多的时间。在软件工程领域有句话,越早的优化可能带来灾难,get things done 要比优化重要的多。- 在 Revising 卡片的过程中,及时的将卡片标注为是否需要编辑,然后及时的更新卡片的内容
搭建 Anki 同步服务器
参考官方的 repo
需要注意的是目前这个 Anki Sync Server 只支持特定版本的客户端,需要到 GitHub 页面自己确认一下。
Install
可以使用 这个 docker-compose :
version: "3"
services:
anki-sync-server:
container_name: anki-sync-server
image: kuklinistvan/anki-sync-server:latest
restart: always
ports:
- "27701:27701"
volumes:
- ./data:/app/data
服务端创建用户
sudo docker exec -it anki-sync-server /bin/sh
# help
/app/anki-sync-server/ankisyncctl.py --help
# add user
/app/anki-sync-server/ankisyncctl.py adduser username
input password
# list users
/app/anki-sync-server/ankisyncctl.py lsuser
# modify password
/app/anki-sync-server/ankisyncctl.py passwd username
Linux 等桌面客户端
菜单,工具,插件,安装插件 2124817646:
http://1.2.3.4:27701
http://1.2.3.4:27701/msync/
Android 客户端配置
在客户端,设置,高级设置,自定义同步服务器中设置。
reference
每天学习一个命令:用 ab 命令来进行 HTTP 服务压测
ab 是针对 HTTP 服务进行性能压力测试的工具,它最初被设计用来测量 Apache 服务器的性能指标,主要用来测试 Apache 服务器每秒能够处理多少请求以及响应时间,但这个命令也可以用来测试通用的 HTTP 服务器性能,比如 Nginx,tomcat,resin 等等。
几个概念
吞吐量 Requests per second
吞吐量是系统每秒钟处理的请求数量,可以通过 总请求数量 / 请求花费时间 来计算。
服务器平均请求等待时间
服务器平均请求等待时间指的是服务器平均处理一个请求花费的时间,公式是 总花费时间 / 请求数量,这个指标是吞吐量的倒数。(Time per request)
并发连接数
指的是某一时刻服务器同时接受的连接数。
安装使用
安装
sudo apt install apache2-utils
使用
ab -c 10 -n 10000 -k -H "Accept-Encoding: gzip, deflate" http://localhost:8080/
解释
-c concurrency并发数-n requests一次测试的请求数量-k表示 keep alive,保持连接-H headers自定义 Header
举例
ab -k -c 10 -n 100 https://www.einverne.info/
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking www.einverne.info (be patient).....done
Server Software: nginx
Server Hostname: www.einverne.info
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
Document Path: /
Document Length: 53802 bytes
Concurrency Level: 10
Time taken for tests: 1.125 seconds
Complete requests: 100
Failed requests: 0
Keep-Alive requests: 0
Total transferred: 5400681 bytes
HTML transferred: 5380200 bytes
Requests per second: 88.91 [#/sec] (mean)
Time per request: 112.470 [ms] (mean)
Time per request: 11.247 [ms] (mean, across all concurrent requests)
Transfer rate: 4689.35 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 5 48 35.3 44 163
Processing: 9 62 65.7 47 559
Waiting: 7 59 64.7 45 543
Total: 25 109 75.4 83 564
Percentage of the requests served within a certain time (ms)
50% 83
66% 111
75% 123
80% 128
90% 225
95% 275
98% 337
99% 564
100% 564 (longest request)
实际使用
登录问题
对于实际场景中经常需要用的登录问题,如果接口需要验证 Cookie ,那么使用 -C 写到 Cookie 内容
ab -n 100 -C key=value http://localhost
或者使用 -H 带 Cookie 自定义多个字段
ab -n 100 -H "Cookie: Key1=Value1; Key2=Value2" http://localhost
总结
ab 只能测试简单的 RESTful 接口,只能应付简单的压测任务。如果需要更加专业的压测工具可以使用 jmeter。
reference
Dash 视频串流技术
这里的 Dash 可不是一加手机的快充技术,在使用 Youtube DL 的时候频繁的接触到 DASH 这个关键词,查了一下 DASH 是流媒体技术,全称是 Dynamic Adaptive Streaming over HTTP,自适应流媒体技术,通过 HTTP 服务传送流媒体,在 YouTube,Netflix,Hulu 等流媒体网站中被频繁应用,国内 Bilibili 也引入了该技术 1。
该技术的大致实现原理是在服务端将视频分片,每个分片都有自身的编码方式,甚至不同的分辨率,码率等等,而在客户端根据当前网速或者设备自行选择需要播放的分片,可以实现不同画质内容无缝切换。所以在 YouTube 切换画质时完全不会黑屏,更不会影响观看。更加具体的原理解释可以参考这里
另外几个值得一说的功能是
- 音频视频分离,在后台播放时可以只拉取音频
- 支持多音轨,多视频轨,多字幕任意切换
DASH 技术与编码器无关,可以使用 H.265, H.264, VP9 等等任何编码器进行编码。
DASH 结构
DASH 音视频流标识文件被称为 Media Presentation Description,包含了一组结构化音频视频内容。
MP4Box 命令
MP4Box 命令 可以对 MP4 文件进行合并,切割,提取等操作。更多可以参考官网
总而言之, MP4Box 命令可以实现如下:
- 操作 MP4,3GP 等 ISO 文件,从不同来源和不同格式添加,删除,复用音频,视频和字幕
- 将 MPEG-4 XMT 或者 W3C SVG 等编解码为二进制格式 MPEG-4 BIFS 或者 LASeR
- 将元数据附加到单个流或整个 ISO 文件以生成符合 MPEG-21 或混合的 MPEG-4 / MPEG-21 文件
- 用于准备 HTTP Adaptive Streaming 内容
- 包装和标记结果,用于在不同设备(例如电话,平板电脑)或不同软件(例如 iTunes)上进行流式传输,下载和回放。
用于内容打包
MP4Box 可以用于将现成内容打包到 ISO 媒体文件,比如 MP4,3GP 等文件中。需要注意的是 MP4Box 命令并不会重新编码音频,视频,图片文件。将 DivX 文件转变为 MP4 文件:
MP4Box -add file.avi new_file.mp4
或者添加第二条音轨到上一条命令输出的文件
MP4Box -add audio2.mp3 new_file.mp4
MP4Box 可以从现存的容器中获取资源,可以使用 -info 来查看媒体资源
MP4Box -info file.avi
然后使用如下类似方法导入文件的音轨
MP4Box -add file.avi#audio new_file.mp4
分发
MP4Box 可以用于准备各种协议的传输分发协议,主要是 HTTP 下载或者 RTP streaming。
To prepare a file for simple progressive HTTP download, the following instruction will interleave file data by chunks of 500 milliseconds in order to enable playback while downloading the file (HTTP FastStart):
MP4Box -inter 500 file.mp4
To prepare for RTP, the following instruction will create RTP hint tracks for the file. This enables classic streaming servers like DarwinStreamingServer or QuickTime Streaming Server to deliver the file through RTSP/RTP:
MP4Box -hint file.mp4
To prepare for adaptive streaming (MPEG-DASH), the following instruction will create the DASH manifest and associated files. For more information on DASH see this post:
MP4Box -dash 1000 file.mp4
Dash
查看 MP4Box dash 相关的帮助:
MP4Box -h dash
DASH Options:
-mpd m3u8 converts HLS manifest (local or remote http) to MPD
Note: not compatible with other DASH options (except -out and -tmp) and does not convert associated segments
-dash dur enables DASH-ing of the file(s) with a segment duration of DUR ms
Note: the duration of a fragment (subsegment) is set
using the -frag switch.
Note: for onDemand profile, sets duration of a subsegment
-dash-strict dur [DEPRECATED, will behave like -dash]
-dash-live[=F] dur generates a live DASH session using dur segment duration, optionally writing live context to F
MP4Box will run the live session until 'q' is pressed or a fatal error occurs.
-ddbg-live[=F] dur same as -dash-live without time regulation for debug purposes.
-frag time_in_ms Specifies a fragment duration of time_in_ms.
* Note: By default, this is the DASH duration
-out filename specifies output MPD file name.
-tmp dirname specifies directory for temporary file creation
* Note: Default temp dir is OS-dependent
-profile NAME specifies the target DASH profile: "onDemand",
"live", "main", "simple", "full",
"hbbtv1.5:live", "dashavc264:live", "dashavc264:onDemand"
* This will set default option values to ensure conformance to the desired profile
* Default profile is "full" in static mode, "live" in dynamic mode
-profile-ext STRING specifies a list of profile extensions, as used by DASH-IF and DVB.
The string will be colon-concatenated with the profile used
比如随便拿一个 mp4 文件:
MP4Box -dash 2000 -rap -profile dashavc264:onDemand input.mp4
解释:
-dash 2000按照 1s 来切-rap强制让分段从随机点开始-profile dashavc264:onDemand可以查看 dash specifications 来查看更多 profile 相关的信息
这个操作不会对视频文件进行重新编码,只是将视频进行切片,所以非常快。执行命令结束后会得到 .mpd 文件和 *_dashinit.mp4 两个额外的文件。生成的这两个文件放到 HTTP 服务器中就可以在支持 mdp 播放的播放器中播放。
一些支持 DASH 的播放器
reference
- https://zh.wikipedia.org/wiki/Matroska
- 基于HTTP的动态自适应流
- https://zhuanlan.zhihu.com/p/24063863
- https://www.instructables.com/id/Making-Your-Own-Simple-DASH-MPEG-Server-Windows-10/
- https://www.jianshu.com/p/ad8544e2d3fd
- https://bitmovin.com/mp4box-dash-content-generation-x264/
- http://wiki.webmproject.org/adaptive-streaming/instructions-to-playback-adaptive-webm-using-dash
-
https://www.bilibili.com/read/cv867888/ ↩
mastering xxx vs xxx cookbook vs xxx in action 系列图书的区别
常看计算机相关图书的话对,Mastering XXX,XXX in Action 肯定不会陌生,不同系列的图书定位是有差别的,刚开始学习一种技术时,选择一本合适的书非常重要。所以这里就我个人的感受来说一下这几个系列的区别。
Mastering XXX
大部分 Mastering 系列图书都是 Packt Publishing 出版社出版的。Mastering 系列的图书是大而全的书籍,从介绍开始,到使用,再到具体的技术细节都有涉及。翻译为中文一般叫做“精通 XXX”,“深入理解 XXX”。
适合有一定基础的初学者阅读。
常见的有:
- 《Mastering Kubernetes》
- 《Mastering Python》
- 《Mastering Nginx》
XXX Cookbook
Cookbook 系列由 O’REILLY 出版社出版,这个系列会侧重于该语言,该工具的使用技巧和方法,会涵盖周边的工具库,算法等等,包含大量的编程技巧和示例代码。该系列的书比较实用,目录编排会通过实例来展示工具或者语言的实用,是一种实用主义的书。Cookbook 直译是食谱的意思,联想来就能够知道这个系列的书目的是为了让读者能做出一道菜来,通过组织不同的原材料(组织代码),最后获得一道美味的食物(达成的目标)。
该系列的书能够让读者认识到是什么,怎么用,最后能够做什么。其实从 cookbook 原本的意思中也能够感知到
a book that gives instructions on cooking and how to cook individual dishes
适合有一定编程能力的学习者参考。
常见的比如:
- 《Python Cookbook》该书已经第三版
XXX in Action
in Action 系列的图书也是比较著名的一个系列,一般翻译为 “XXX 实战”,该系列图书由 MANNING 出版社出版,国内一般由人民邮电出版社翻译。听这个名字就知道这是偏实战的一本书,通常情况下会在书中有一个贯穿全书的例子,比如用 Redis 的特性实现某个系统功能等等。
但总得来说也是一本入门级别的书籍,适合初学者和有一定经验的从业者。
常见:
- 《Machine Learning in Action》
- 《Spring in Action》
- 《Spring Boot in Action》
- 《Redis in Action》
- 《Maven in Action》
Learning XXX
适合初学者,我看过 《Learning Python》 这本,是我看过的所有的 Python 相关书籍中最详细的一本,每一个语言的细节,每一个用法的区别都是非常详细的。
Learning 系列的图书也是 O’Reilly 出版社的系列,这系列的图书比较初级,但是细节部分很详细,推荐初学者快速入门。
常见:
- 《Learning Perl》
- 《Learning Python》
Head First
Head First 系列的图书看的不多,最出名的可能是那本《Head First 设计模式》了吧,但是 Head First 系列书我查了一下都比较老,这个系列可能是这里面最没有存在感的一个系列了。至于特色部分等我看一些之后回来补上。
补充 Head First 系列,之所以叫做 Head First 是这个系列的图书开创了一种学习模式,通过大量的配图,对话,营造一种比较好的理解方式,通过联想记忆,让读者能够长时间集中注意力然后达到学习的目的。
常见:
- 《Head First Android Development》
Thinking in XXX
Thinking in 系列,一般翻译为 XXX 编程思想。该系列的图书主要是讲述一种编程思维,用该语言的思维来抽象现实问题。
该系列常见的:
- 《Thinking in Java》
- 《Thinking in C++》
Dive into XXX
Dive into 系列一般翻译为“深入 XXX”,也是比较全面的介绍性书籍,书籍的组织方式一般也是由浅入深。
常见;
- 《Dive into Python》
Primer
既然已经写了这么多了,也不在乎多这一类的书籍,Primer 最熟悉的一本应该就是 C++ Primer 了,最开始还以为是一本 C++ 中高级的书,但其实是一本初级入门读本,从 Primer 单词的释义就能看出
a book that contains basic instructions
所以见到此类的书大可直接阅读。
总结
对于新的一项技术,如果处于是什么都不太清楚的状态,推荐先找 Learning 系列的图书,如果没有可以找 Mastering 或者 Cookbook 系列的图书,先从直观上对该技术有一个总体的了解,是什么,有什么功能,能够做什么。然后具体对其中的细节进行学习。
reference
- 豆瓣
Selenium 使用介绍
在之前介绍 Appium 的时候就提到了一些 Selenium ,如果说 Appium 是移动端测试框架,那么 Selenium 就是 Web 端测试框架。简单的理解就可以认为我们可以编程控制浏览器的行为。Selenium 支持 Chrome,Firefox,Safari 等主流浏览器,也支持 PhantomJS, Headless Chrome 等等无头 (headless) 浏览器(无界面)。Selenium 支持的语言也非常多 Java, C#,Python, Ruby,JavaScript 1 等等
官网
安装使用
安装 Python 客户端
pip install selenium
Python client Driver 的文档在这里
安装第三方驱动,所有支持的驱动可以在这里 找到。几个重要的 Driver
- https://sites.google.com/a/chromium.org/chromedriver/ 或者 http://chromedriver.chromium.org/downloads
- https://chromedriver.storage.googleapis.com/index.html
- https://github.com/mozilla/geckodriver/
举例
import unittest
from selenium import webdriver
class GoogleTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.google.com')
self.assertIn('Google', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
reference
-
https://www.seleniumhq.org/download/ ↩
文章分类
最近文章
- 2024 年台北之行 去年的时候就得知了海外的大陆人可以通过官方网站申请入台证,从而可以在海外直接入境台湾,所以 4 月份女朋友过来日本之后就通过线上系统申请了入台证,入台证申请通过并付费之后是只有 3 个月有效期的,因为我们申请的比较晚,所以有效期的三个月正好落在了最热的 7,8,9 月份,但考虑到暑假有假期,我们还是决定硬着头皮买了机票。
- macOS 上的多栏文件管理器 QSpace QSpace 是一个 macOS 上的多窗口平铺的文件管理器,可以作为 Finder 的代替,在 Windows 上曾经用过很长时间的 [[Total Commander]],后来更换到 Linux Mint 之后默认的文件管理器自带多面板,反而是用了很多年 macOS ,才意识到原来我缺一个多窗口,多面板的文件管理器。
- Dinox 又一款 AI 语音转录笔记 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- Emote 又一款 AI 语音笔记应用 继发现了 Voicenotes 以及 Dinox 之后,又发现一款语音笔记 Emote,相较于前两款应用,Emote 吸引我的就是其实时转录的功能,在用 Voicenotes 的时候时长担心如果应用出现故障,没有把我要录下来的话录制进去,后期怎么办,而 Emote 就解决了这个问题,实时转录的功能恰好作为了一个声音录制的监听。
- 音流:一款支持 Navidrome 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。