什么是向量数据库
在介绍什么是向量数据库之前先来了解一下数据库的种类。
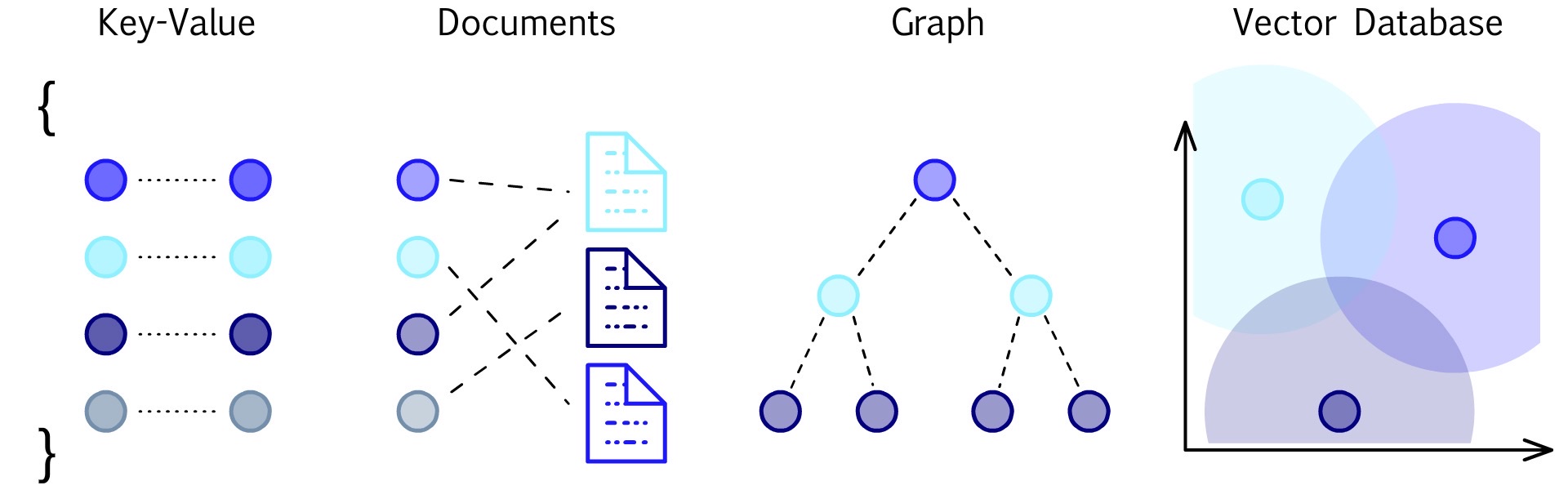
图上从左往右依次是 Key-Value 数据库([[Redis]],[[HBase]]),文档数据库([[MongoDB]],[[Cosmos DB]]),[[图数据库]]([[图数据库 Neo4j]],[[图数据库 Nebula Graph]]),向量数据库。
向量数据库就是用来存储,检索,分析向量的数据库。
向量数据库是一种专门用于存储和查询向量数据的数据库,其中向量数据指的是由数字组成的向量。向量数据库通常使用高效的相似度搜索算法,例如余弦相似度或欧几里得距离,来快速查询与目标向量最相似的向量。向量数据库在机器学习、计算机视觉、自然语言处理等领域中得到广泛应用。
The vectors are usually generated by applying some kind of transformation or embedding function to the raw data, such as text, images, audio, video, and others.
为什么需要有向量数据库
解决两个问题:
- 高效的相似性检索 (similarity search)
- 相似文本检索
- 从图片检索图片,人脸匹配(支付),车牌号匹配,图片检测等
- 高效的数据组织和分析能力
- 人脸撞库,分析案发现场的人物图片
在机器学习领域,通常使用一组数值来表示一个物体的不同特征。比如我们去搜索图片的时候,数据库中存储和对比的并不是图片,而是去搜索算法提取的图片特征。
向量数据库的特点
向量数据库具有以下特点:
- 提供标准的 SQL 访问接口
- 高效的相似度搜索:向量数据库使用高效的相似度搜索算法,例如余弦相似度或欧几里得距离,来快速查询与目标向量最相似的向量。
- 支持高维向量:向量数据库可以存储和查询高维向量,例如在图像识别和自然语言处理中经常使用的特征向量。
- 高性能:向量数据库通常使用高性能的数据结构和算法,例如哈希表和树结构,以实现快速的查询和插入操作。
- 可扩展性:向量数据库可以通过添加更多的节点或服务器来实现横向扩展,以支持大规模的向量数据集。
- 支持多种数据类型:向量数据库通常支持多种数据类型,例如浮点数、整数和布尔值,以满足不同应用场景的需求。
和传统数据库的区别
- 数据规模上超过关系型数据库,分布式,扩展性
- 查询方式不同,计算密集型
- 传统数据库点查和范围查
- 向量数据库是近似查
- 搜索推荐
- 低延时高并发
向量数据库有哪些
目前比较流行的向量数据库包括:
- [[Milvus]]:一个开源的向量数据库,是全世界第一款向量数据库,也是目前最领先的云原生向量数据库,支持自托管,支持高维向量的存储和查询,提供了多种相似度搜索算法和多种客户端语言接口。构建在开源的 Faiss, HNSW, Annoy 之上
- zilliz 是一个 SaaS 版本的 Milvus 平台,提供在线托管的 Milvus 服务。
- [[Weaviate]] 开源,一个完全托管的向量数据库
- [[Vespa]] 开源,可自托管,提供托管服务
- [[Vald]]
- [[Redis]] Redis 也提供了向量距离的相关内容
- [[Qdrant]] 开源,Rust
- [[Faiss]]:一个由 Facebook 开发的向量数据库,支持高效的相似度搜索和聚类操作,提供了多种索引结构和查询算法。
- sqlite-vss 基于 Faiss 做了一个 SQLite Vector Similarity Search
- [[Pinecone]] 闭源,完全托管的向量数据库
- Annoy:一个开源的向量数据库,支持高维向量的存储和查询,使用随机化近似算法实现快速的相似度搜索。
- Hnswlib:一个开源的向量数据库,支持高维向量的存储和查询,使用基于图的相似度搜索算法实现高效的查询。
- NMSLIB:一个开源的向量数据库,支持多种相似度搜索算法和索引结构,可以用于高维向量和非向量数据的存储和查询。
- Vearch
- TensorDB
- Om-iBASE,基于智能算法提取需存储内容的特征,转变成具有大小定义、特征描述、空间位置的多维数值进行向量化存储的数据库,使内容不仅可被存储,同时可被智能检索与分析。使用向量数据库可有效实现音频、视频、图片、文件等非结构化数据向量化存储,并通过向量检索、向量聚类、向量降维等技术,实现数据精准分析、精准检索。
- Proxima
- VQLite 是一个基于 Google ScaNN 包装的轻量简单的向量数据库,Go 语言编写。
- pgvector 是为 [[PostgreSQL]] 数据库编写的一个向量近似度查询支持。
- [[SPTAG]] 是微软开源的一个近似向量搜索的库
- [[Elasticsearch]] 和 OpenSearch 的 GSI APU
相关的开源项目:
- pigsty 监控/数据库开箱即用 HA/PITR/IaC 一应俱全。Pigsty 可以让用户以接近硬件的成本运行企业级数据库服务。2.0.2 发布之后可以使用 pgvector 来存储向量。
- vearch Vearch 是一个分布式的向量搜索系统。
ChatGPT Embedding 后的内容相似度查询是用 Cosine 算法
托管的向量数据库 Fully managed vector database
相关工具
- docarray 是 Linux 基金会下的一个专门为多模态数据设计的 Python 工具包,一套数据结构就解决了表示、处理、传输和存储,存储这块儿提供了一套统一的向量数据库 API,包括 Redis、Milvus、Qdrant、Weaviate、ES 等等。
可学习的代码:
- https://github.com/GanymedeNil/document.ai 基于向量数据库与 GPT3.5 的通用本地知识库方案(A universal local knowledge base solution based on vector database and GPT3.5)
向量数据库的几个发展方向
- 过去的向量数据库是面向实时性要求高,数据规模小,可用性高的场景,但是随着图像,视频,无人驾驶,NLP 的发展,数据量已经从千万级别增长到百亿级别
- 单机想分布式云原生发展
- 不同的索引实现方式,Faiss 为代表的 IVF 统一到了 HNSW/NGT 为代表的图流派。图索引尽管性能相对差,内存消耗高,但是性能好,召回率高。Google 也发布了 ScaNN 技术
- 规范的查询语言,向量数据库还没有统一的查询接口,大多数是定制的 SDK 或 RESTful 接口
- 向量数据库和传统数据库融合
向量数据库的实现原理
- 存储
- 查询
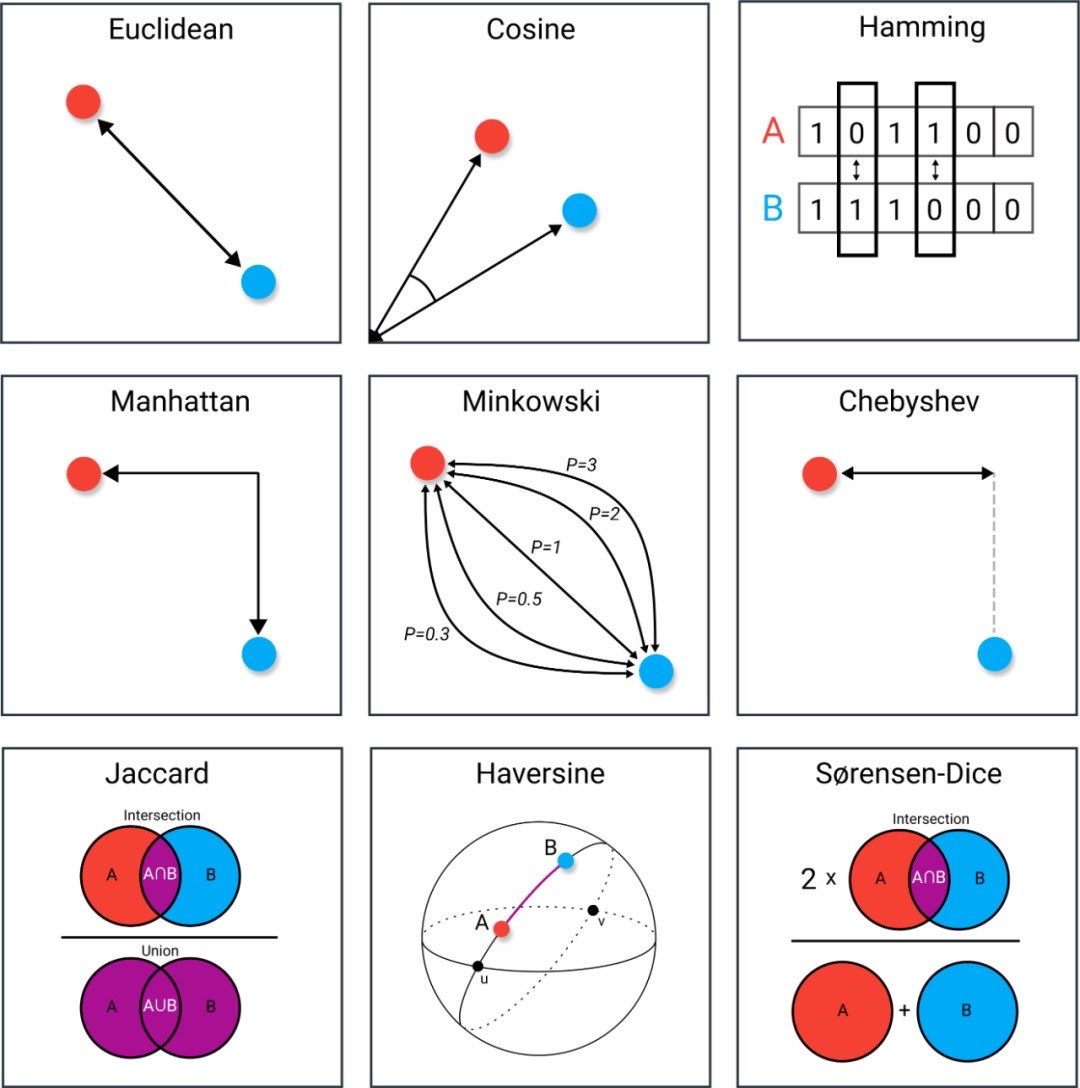
- 相似度计算
- 欧式距离 L2
欧式距离 Euclidean distance L2
欧氏距离是计算两个点之间最短直线距离的方法。
$d(x,y) = d(y,x) = \sqrt{\sum_{i=1}^{n}(x_i-y_i)^2}$
其中 $x=(x_1, x_2, …, a_n)$ 和 $y=(y_1, y_2, …, y_n)$ 是 N 维欧式空间中的点。
内积 Inner product (IP)
两个向量内积距离计算公式
$\mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{n} a_i b_i$
其中,$n$ 是向量的维数,$a_i$ 和 $b_i$ 分别是向量 $\mathbf{a}$ 和 $\mathbf{b}$ 在第 $i$ 个维度上的分量。
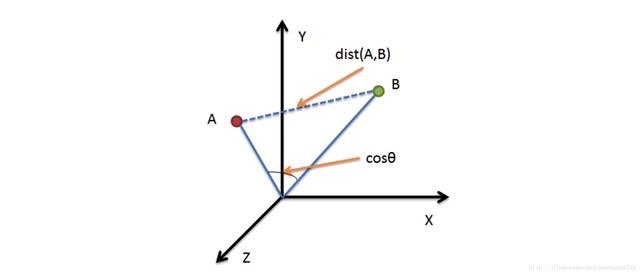
内积更适合计算向量的方向而不是大小。如果要使用点积计算向量相似度,必需对向量作归一化处理,处理后点积与余弦相似度等价。
二维
向量数据库的实际应用
- 相似文本检索
- 图片搜图片
- 搜索音频内容
- 搜索视频内容
一段代码演示向量数据库的用途
[[chatdoc]] 项目
related
- [[LlamaIndex]]
- [[LangChain]]